 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Memory Utilization with Effective State-Size
Apr 28, 2025The need to develop a general framework for architecture analysis is becoming increasingly important, given the expanding design space of sequence models. To this end, we draw insights from classical signal processing and control theory, to develop a quantitative measure of \textit{memory utilization}: the internal mechanisms through which a model stores past information to produce future outputs. This metric, which we call \textbf{\textit{effective state-size}} (ESS), is tailored to the fundamental class of systems with \textit{input-invariant} and \textit{input-varying linear operators}, encompassing a variety of computational units such as variants of attention, convolutions, and recurrences. Unlike prior work on memory utilization, which either relies on raw operator visualizations (e.g. attention maps), or simply the total \textit{memory capacity} (i.e. cache size) of a model, our metrics provide highly interpretable and actionable measurements. In particular, we show how ESS can be leveraged to improve initialization strategies, inform novel regularizers and advance the performance-efficiency frontier through model distillation. Furthermore, we demonstrate that the effect of context delimiters (such as end-of-speech tokens) on ESS highlights cross-architectural differences in how large language models utilize their available memory to recall information. Overall, we find that ESS provides valuable insights into the dynamics that dictate memory utilization, enabling the design of more efficient and effective sequence models.
SMPLest-X: Ultimate Scaling for Expressive Human Pose and Shape Estimation
Jan 16, 2025Expressive human pose and shape estimation (EHPS) unifies body, hands, and face motion capture with numerous applications. Despite encouraging progress, current state-of-the-art methods focus on training innovative architectural designs on confined datasets. In this work, we investigate the impact of scaling up EHPS towards a family of generalist foundation models. 1) For data scaling, we perform a systematic investigation on 40 EHPS datasets, encompassing a wide range of scenarios that a model trained on any single dataset cannot handle. More importantly, capitalizing on insights obtained from the extensive benchmarking process, we optimize our training scheme and select datasets that lead to a significant leap in EHPS capabilities. Ultimately, we achieve diminishing returns at 10M training instances from diverse data sources. 2) For model scaling, we take advantage of vision transformers (up to ViT-Huge as the backbone) to study the scaling law of model sizes in EHPS. To exclude the influence of algorithmic design, we base our experiments on two minimalist architectures: SMPLer-X, which consists of an intermediate step for hand and face localization, and SMPLest-X, an even simpler version that reduces the network to its bare essentials and highlights significant advances in the capture of articulated hands. With big data and the large model, the foundation models exhibit strong performance across diverse test benchmarks and excellent transferability to even unseen environments. Moreover, our finetuning strategy turns the generalist into specialist models, allowing them to achieve further performance boosts. Notably, our foundation models consistently deliver state-of-the-art results on seven benchmarks such as AGORA, UBody, EgoBody, and our proposed SynHand dataset for comprehensive hand evaluation. (Code is available at: https://github.com/wqyin/SMPLest-X).
DART-LLM: Dependency-Aware Multi-Robot Task Decomposition and Execution using Large Language Models
Nov 13, 2024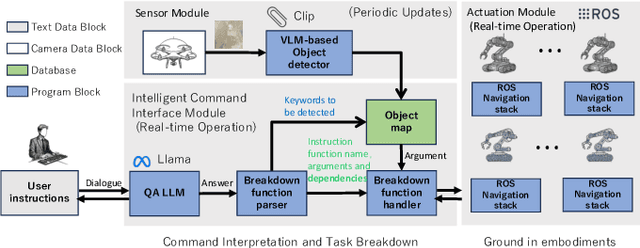
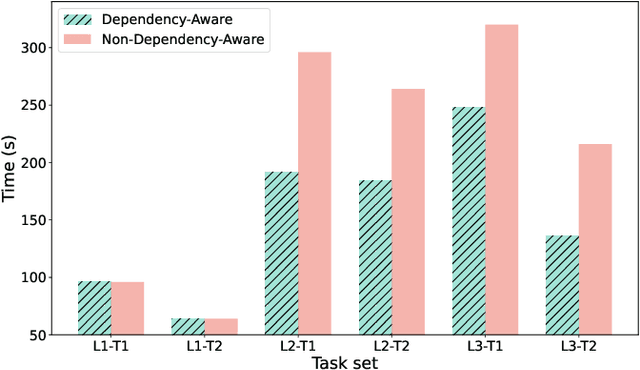
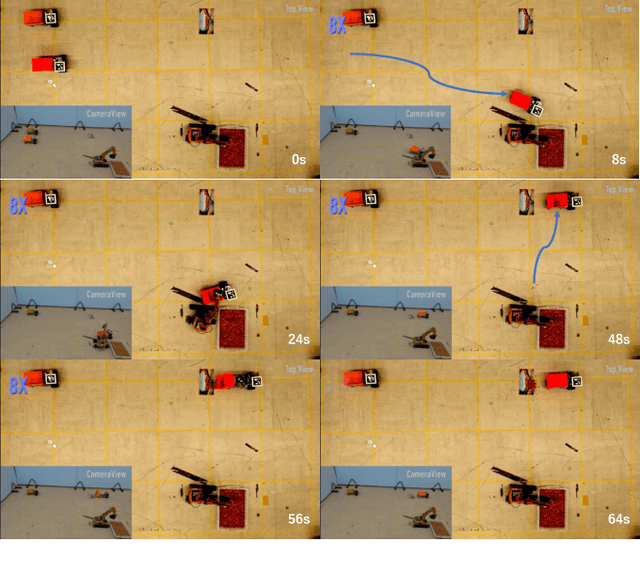
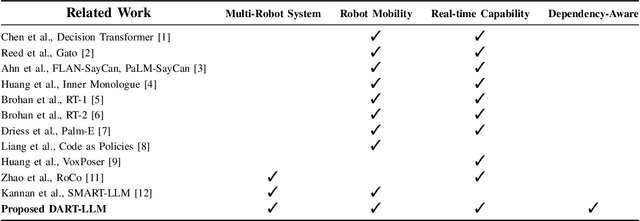
Large Language Models (LLMs) have demonstrated significant reasoning capabilities in robotic systems. However, their deployment in multi-robot systems remains fragmented and struggles to handle complex task dependencies and parallel execution. This study introduces the DART-LLM (Dependency-Aware Multi-Robot Task Decomposition and Execution using Large Language Models) system, designed to address these challenges. DART-LLM utilizes LLMs to parse natural language instructions, decomposing them into multiple subtasks with dependencies to establish complex task sequences, thereby enhancing efficient coordination and parallel execution in multi-robot systems. The system includes the QA LLM module, Breakdown Function modules, Actuation module, and a Vision-Language Model (VLM)-based object detection module, enabling task decomposition and execution from natural language instructions to robotic actions. Experimental results demonstrate that DART-LLM excels in handling long-horizon tasks and collaborative tasks with complex dependencies. Even when using smaller models like Llama 3.1 8B, the system achieves good performance, highlighting DART-LLM's robustness in terms of model size. Please refer to the project website \url{https://wyd0817.github.io/project-dart-llm/} for videos and code.
State-Free Inference of State-Space Models: The Transfer Function Approach
May 10, 2024We approach designing a state-space model for deep learning applications through its dual representation, the transfer function, and uncover a highly efficient sequence parallel inference algorithm that is state-free: unlike other proposed algorithms, state-free inference does not incur any significant memory or computational cost with an increase in state size. We achieve this using properties of the proposed frequency domain transfer function parametrization, which enables direct computation of its corresponding convolutional kernel's spectrum via a single Fast Fourier Transform. Our experimental results across multiple sequence lengths and state sizes illustrates, on average, a 35% training speed improvement over S4 layers -- parametrized in time-domain -- on the Long Range Arena benchmark, while delivering state-of-the-art downstream performances over other attention-free approaches. Moreover, we report improved perplexity in language modeling over a long convolutional Hyena baseline, by simply introducing our transfer function parametrization. Our code is available at https://github.com/ruke1ire/RTF.
WHAC: World-grounded Humans and Cameras
Mar 19, 2024



Estimating human and camera trajectories with accurate scale in the world coordinate system from a monocular video is a highly desirable yet challenging and ill-posed problem. In this study, we aim to recover expressive parametric human models (i.e., SMPL-X) and corresponding camera poses jointly, by leveraging the synergy between three critical players: the world, the human, and the camera. Our approach is founded on two key observations. Firstly, camera-frame SMPL-X estimation methods readily recover absolute human depth. Secondly, human motions inherently provide absolute spatial cues. By integrating these insights, we introduce a novel framework, referred to as WHAC, to facilitate world-grounded expressive human pose and shape estimation (EHPS) alongside camera pose estimation, without relying on traditional optimization techniques. Additionally, we present a new synthetic dataset, WHAC-A-Mole, which includes accurately annotated humans and cameras, and features diverse interactive human motions as well as realistic camera trajectories. Extensive experiments on both standard and newly established benchmarks highlight the superiority and efficacy of our framework. We will make the code and dataset publicly available.
Motion Degeneracy in Self-supervised Learning of Elevation Angle Estimation for 2D Forward-Looking Sonar
Aug 01, 2023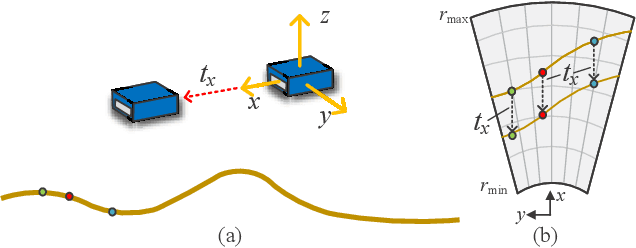
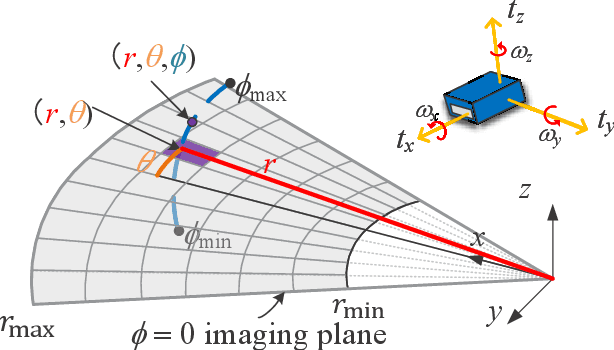
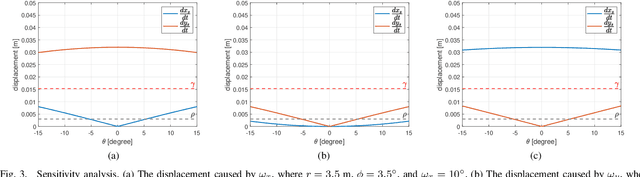
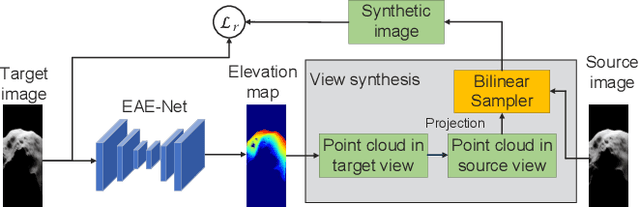
2D forward-looking sonar is a crucial sensor for underwater robotic perception. A well-known problem in this field is estimating missing information in the elevation direction during sonar imaging. There are demands to estimate 3D information per image for 3D mapping and robot navigation during fly-through missions. Recent learning-based methods have demonstrated their strengths, but there are still drawbacks. Supervised learning methods have achieved high-quality results but may require further efforts to acquire 3D ground-truth labels. The existing self-supervised method requires pretraining using synthetic images with 3D supervision. This study aims to realize stable self-supervised learning of elevation angle estimation without pretraining using synthetic images. Failures during self-supervised learning may be caused by motion degeneracy problems. We first analyze the motion field of 2D forward-looking sonar, which is related to the main supervision signal. We utilize a modern learning framework and prove that if the training dataset is built with effective motions, the network can be trained in a self-supervised manner without the knowledge of synthetic data. Both simulation and real experiments validate the proposed method.
2D Forward Looking Sonar Simulation with Ground Echo Modeling
Apr 17, 2023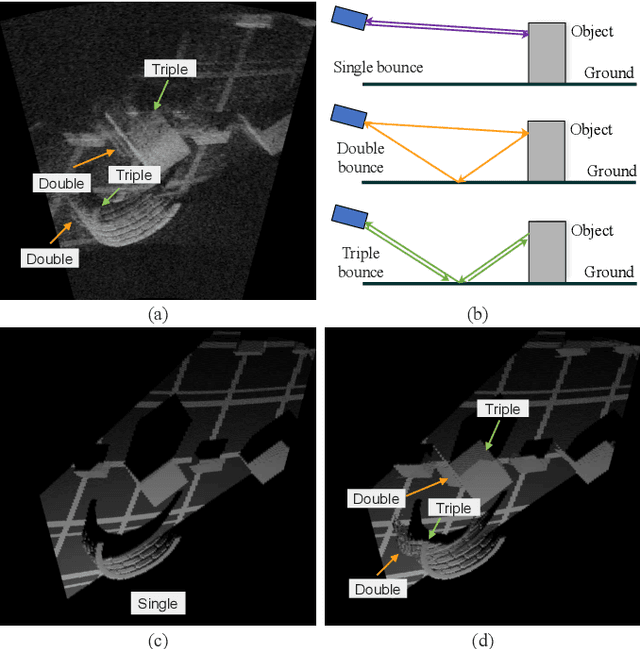

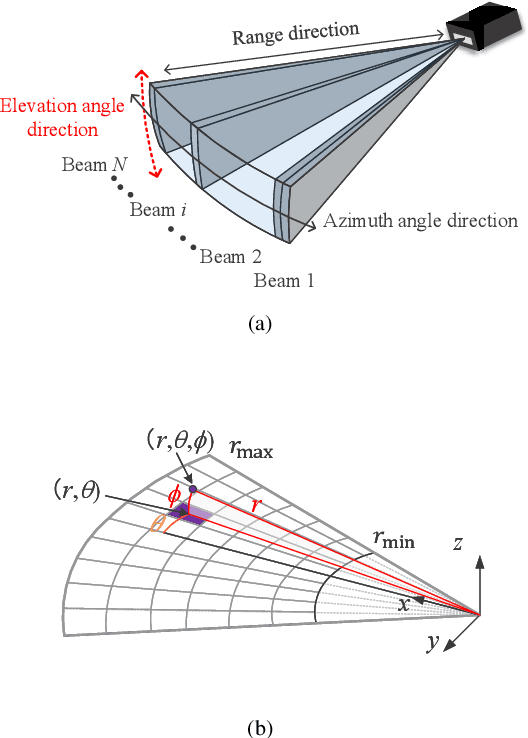
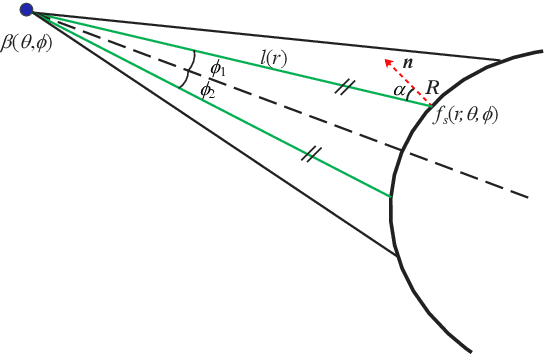
Imaging sonar produces clear images in underwater environments, independent of water turbidity and lighting conditions. The next generation 2D forward looking sonars are compact in size and able to generate high-resolution images which facilitate underwater robotics research. Considering the difficulties and expenses of implementing experiments in underwater environments, tremendous work has been focused on sonar image simulation. However, sonar artifacts like multi-path reflection were not sufficiently discussed, which cannot be ignored in water tank environments. In this paper, we focus on the influence of echoes from the flat ground. We propose a method to simulate the ground echo effect physically in acoustic images. We model the multi-bounce situations using the single-bounce framework for computation efficiency. We compare the real image captured in the water tank with the synthetic images to validate the proposed methods.
Learning Pseudo Front Depth for 2D Forward-Looking Sonar-based Multi-view Stereo
Jul 30, 2022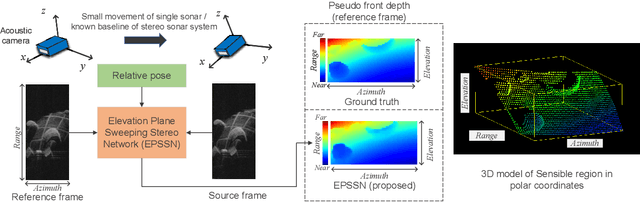
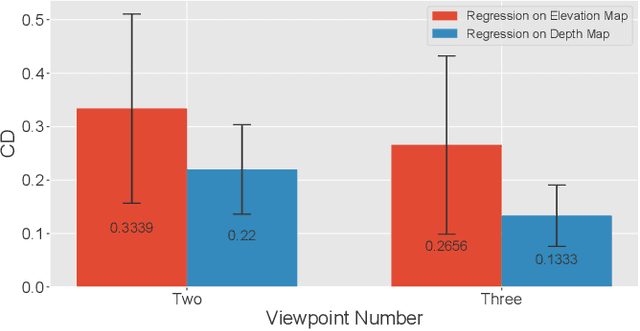
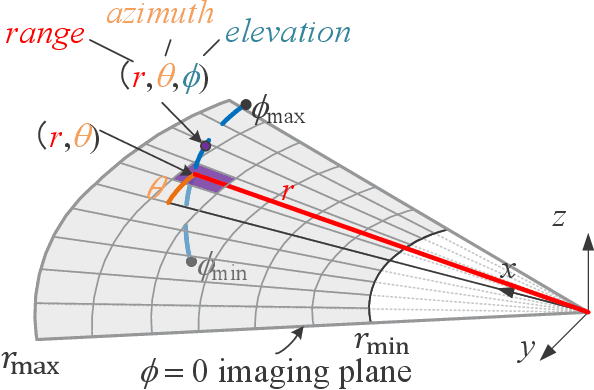
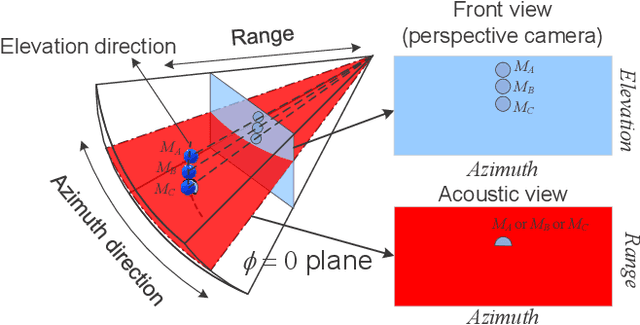
Retrieving the missing dimension information in acoustic images from 2D forward-looking sonar is a well-known problem in the field of underwater robotics. There are works attempting to retrieve 3D information from a single image which allows the robot to generate 3D maps with fly-through motion. However, owing to the unique image formulation principle, estimating 3D information from a single image faces severe ambiguity problems. Classical methods of multi-view stereo can avoid the ambiguity problems, but may require a large number of viewpoints to generate an accurate model. In this work, we propose a novel learning-based multi-view stereo method to estimate 3D information. To better utilize the information from multiple frames, an elevation plane sweeping method is proposed to generate the depth-azimuth-elevation cost volume. The volume after regularization can be considered as a probabilistic volumetric representation of the target. Instead of performing regression on the elevation angles, we use pseudo front depth from the cost volume to represent the 3D information which can avoid the 2D-3D problem in acoustic imaging. High-accuracy results can be generated with only two or three images. Synthetic datasets were generated to simulate various underwater targets. We also built the first real dataset with accurate ground truth in a large scale water tank. Experimental results demonstrate the superiority of our method, compared to other state-of-the-art methods.
Efficient Video Deblurring Guided by Motion Magnitude
Jul 27, 2022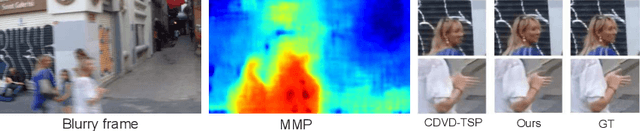


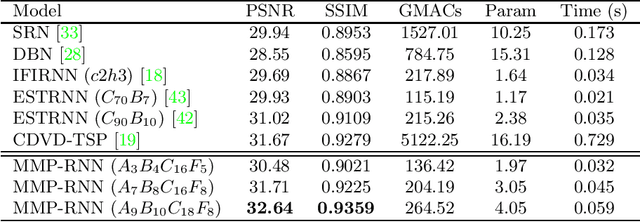
Video deblurring is a highly under-constrained problem due to the spatially and temporally varying blur. An intuitive approach for video deblurring includes two steps: a) detecting the blurry region in the current frame; b) utilizing the information from clear regions in adjacent frames for current frame deblurring. To realize this process, our idea is to detect the pixel-wise blur level of each frame and combine it with video deblurring. To this end, we propose a novel framework that utilizes the motion magnitude prior (MMP) as guidance for efficient deep video deblurring. Specifically, as the pixel movement along its trajectory during the exposure time is positively correlated to the level of motion blur, we first use the average magnitude of optical flow from the high-frequency sharp frames to generate the synthetic blurry frames and their corresponding pixel-wise motion magnitude maps. We then build a dataset including the blurry frame and MMP pairs. The MMP is then learned by a compact CNN by regression. The MMP consists of both spatial and temporal blur level information, which can be further integrated into an efficient recurrent neural network (RNN) for video deblurring. We conduct intensive experiments to validate the effectiveness of the proposed methods on the public datasets.
ReIL: A Framework for Reinforced Intervention-based Imitation Learning
Mar 29, 2022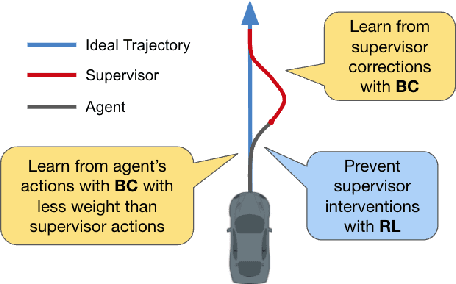
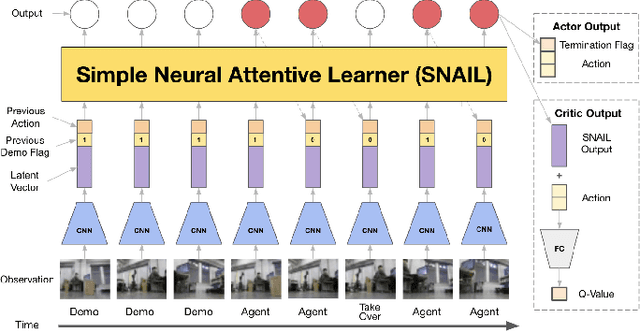


Compared to traditional imitation learning methods such as DAgger and DART, intervention-based imitation offers a more convenient and sample efficient data collection process to users. In this paper, we introduce Reinforced Intervention-based Learning (ReIL), a framework consisting of a general intervention-based learning algorithm and a multi-task imitation learning model aimed at enabling non-expert users to train agents in real environments with little supervision or fine tuning. ReIL achieves this with an algorithm that combines the advantages of imitation learning and reinforcement learning and a model capable of concurrently processing demonstrations, past experience, and current observations. Experimental results from real world mobile robot navigation challenges indicate that ReIL learns rapidly from sparse supervisor corrections without suffering deterioration in performance that is characteristic of supervised learning-based methods such as HG-Dagger and IWR. The results also demonstrate that in contrast to other intervention-based methods such as IARL and EGPO, ReIL can utilize an arbitrary reward function for training without any additional heuristics.