 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Memory Utilization with Effective State-Size
Apr 28, 2025The need to develop a general framework for architecture analysis is becoming increasingly important, given the expanding design space of sequence models. To this end, we draw insights from classical signal processing and control theory, to develop a quantitative measure of \textit{memory utilization}: the internal mechanisms through which a model stores past information to produce future outputs. This metric, which we call \textbf{\textit{effective state-size}} (ESS), is tailored to the fundamental class of systems with \textit{input-invariant} and \textit{input-varying linear operators}, encompassing a variety of computational units such as variants of attention, convolutions, and recurrences. Unlike prior work on memory utilization, which either relies on raw operator visualizations (e.g. attention maps), or simply the total \textit{memory capacity} (i.e. cache size) of a model, our metrics provide highly interpretable and actionable measurements. In particular, we show how ESS can be leveraged to improve initialization strategies, inform novel regularizers and advance the performance-efficiency frontier through model distillation. Furthermore, we demonstrate that the effect of context delimiters (such as end-of-speech tokens) on ESS highlights cross-architectural differences in how large language models utilize their available memory to recall information. Overall, we find that ESS provides valuable insights into the dynamics that dictate memory utilization, enabling the design of more efficient and effective sequence models.
State-Free Inference of State-Space Models: The Transfer Function Approach
May 10, 2024We approach designing a state-space model for deep learning applications through its dual representation, the transfer function, and uncover a highly efficient sequence parallel inference algorithm that is state-free: unlike other proposed algorithms, state-free inference does not incur any significant memory or computational cost with an increase in state size. We achieve this using properties of the proposed frequency domain transfer function parametrization, which enables direct computation of its corresponding convolutional kernel's spectrum via a single Fast Fourier Transform. Our experimental results across multiple sequence lengths and state sizes illustrates, on average, a 35% training speed improvement over S4 layers -- parametrized in time-domain -- on the Long Range Arena benchmark, while delivering state-of-the-art downstream performances over other attention-free approaches. Moreover, we report improved perplexity in language modeling over a long convolutional Hyena baseline, by simply introducing our transfer function parametrization. Our code is available at https://github.com/ruke1ire/RTF.
Laughing Hyena Distillery: Extracting Compact Recurrences From Convolutions
Oct 28, 2023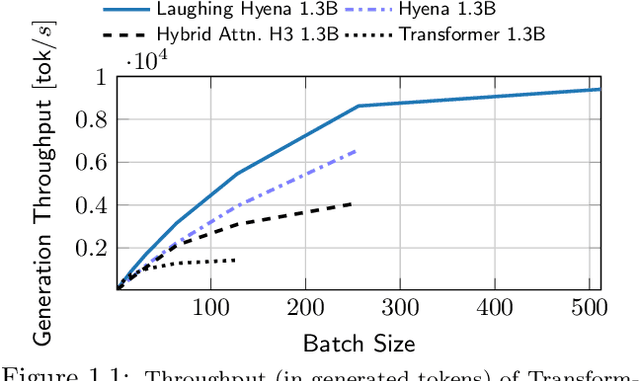
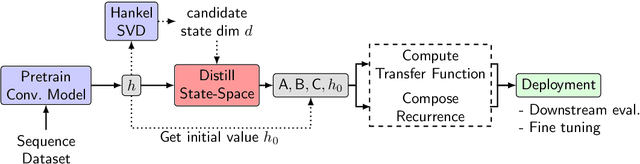
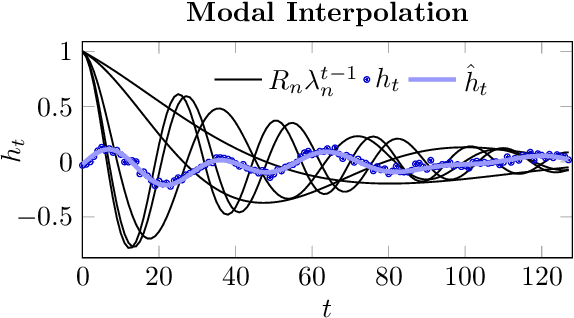
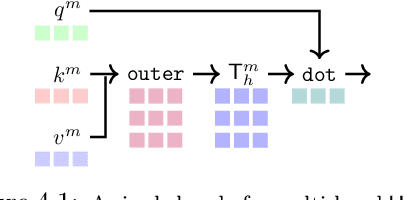
Recent advances in attention-free sequence models rely on convolutions as alternatives to the attention operator at the core of Transformers. In particular, long convolution sequence models have achieved state-of-the-art performance in many domains, but incur a significant cost during auto-regressive inference workloads -- naively requiring a full pass (or caching of activations) over the input sequence for each generated token -- similarly to attention-based models. In this paper, we seek to enable $\mathcal O(1)$ compute and memory cost per token in any pre-trained long convolution architecture to reduce memory footprint and increase throughput during generation. Concretely, our methods consist in extracting low-dimensional linear state-space models from each convolution layer, building upon rational interpolation and model-order reduction techniques. We further introduce architectural improvements to convolution-based layers such as Hyena: by weight-tying the filters across channels into heads, we achieve higher pre-training quality and reduce the number of filters to be distilled. The resulting model achieves 10x higher throughput than Transformers and 1.5x higher than Hyena at 1.3B parameters, without any loss in quality after distillation.