 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Memory Utilization with Effective State-Size
Apr 28, 2025The need to develop a general framework for architecture analysis is becoming increasingly important, given the expanding design space of sequence models. To this end, we draw insights from classical signal processing and control theory, to develop a quantitative measure of \textit{memory utilization}: the internal mechanisms through which a model stores past information to produce future outputs. This metric, which we call \textbf{\textit{effective state-size}} (ESS), is tailored to the fundamental class of systems with \textit{input-invariant} and \textit{input-varying linear operators}, encompassing a variety of computational units such as variants of attention, convolutions, and recurrences. Unlike prior work on memory utilization, which either relies on raw operator visualizations (e.g. attention maps), or simply the total \textit{memory capacity} (i.e. cache size) of a model, our metrics provide highly interpretable and actionable measurements. In particular, we show how ESS can be leveraged to improve initialization strategies, inform novel regularizers and advance the performance-efficiency frontier through model distillation. Furthermore, we demonstrate that the effect of context delimiters (such as end-of-speech tokens) on ESS highlights cross-architectural differences in how large language models utilize their available memory to recall information. Overall, we find that ESS provides valuable insights into the dynamics that dictate memory utilization, enabling the design of more efficient and effective sequence models.
Anomaly Triplet-Net: Progress Recognition Model Using Deep Metric Learning Considering Occlusion for Manual Assembly Work
Jan 07, 2025In this paper, a progress recognition method consider occlusion using deep metric learning is proposed to visualize the product assembly process in a factory. First, the target assembly product is detected from images acquired from a fixed-point camera installed in the factory using a deep learning-based object detection method. Next, the detection area is cropped from the image. Finally, by using a classification method based on deep metric learning on the cropped image, the progress of the product assembly work is estimated as a rough progress step. As a specific progress estimation model, we propose an Anomaly Triplet-Net that adds anomaly samples to Triplet Loss for progress estimation considering occlusion. In experiments, an 82.9% success rate is achieved for the progress estimation method using Anomaly Triplet-Net. We also experimented with the practicality of the sequence of detection, cropping, and progression estimation, and confirmed the effectiveness of the overall system.
* This paper has been peer-reviewed, revised, and published in Advanced Robotics
State-Free Inference of State-Space Models: The Transfer Function Approach
May 10, 2024We approach designing a state-space model for deep learning applications through its dual representation, the transfer function, and uncover a highly efficient sequence parallel inference algorithm that is state-free: unlike other proposed algorithms, state-free inference does not incur any significant memory or computational cost with an increase in state size. We achieve this using properties of the proposed frequency domain transfer function parametrization, which enables direct computation of its corresponding convolutional kernel's spectrum via a single Fast Fourier Transform. Our experimental results across multiple sequence lengths and state sizes illustrates, on average, a 35% training speed improvement over S4 layers -- parametrized in time-domain -- on the Long Range Arena benchmark, while delivering state-of-the-art downstream performances over other attention-free approaches. Moreover, we report improved perplexity in language modeling over a long convolutional Hyena baseline, by simply introducing our transfer function parametrization. Our code is available at https://github.com/ruke1ire/RTF.
Expandable YOLO: 3D Object Detection from RGB-D Images
Jun 26, 2020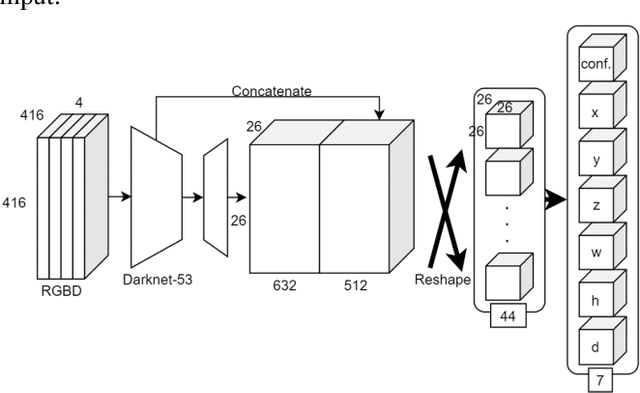


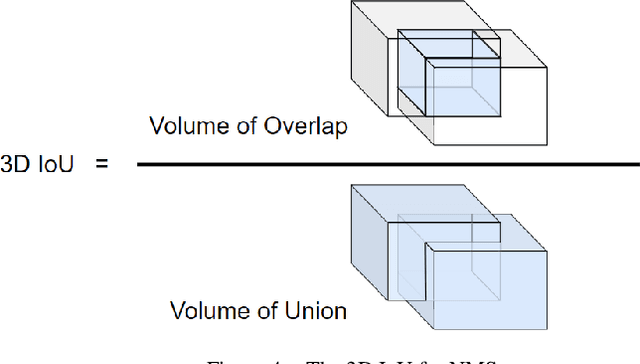
This paper aims at constructing a light-weight object detector that inputs a depth and a color image from a stereo camera. Specifically, by extending the network architecture of YOLOv3 to 3D in the middle, it is possible to output in the depth direction. In addition, Intersection over Uninon (IoU) in 3D space is introduced to confirm the accuracy of region extraction results. In the field of deep learning, object detectors that use distance information as input are actively studied for utilizing automated driving. However, the conventional detector has a large network structure, and the real-time property is impaired. The effectiveness of the detector constructed as described above is verified using datasets. As a result of this experiment, the proposed model is able to output 3D bounding boxes and detect people whose part of the body is hidden. Further, the processing speed of the model is 44.35 fps.