 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Memory Utilization with Effective State-Size
Apr 28, 2025The need to develop a general framework for architecture analysis is becoming increasingly important, given the expanding design space of sequence models. To this end, we draw insights from classical signal processing and control theory, to develop a quantitative measure of \textit{memory utilization}: the internal mechanisms through which a model stores past information to produce future outputs. This metric, which we call \textbf{\textit{effective state-size}} (ESS), is tailored to the fundamental class of systems with \textit{input-invariant} and \textit{input-varying linear operators}, encompassing a variety of computational units such as variants of attention, convolutions, and recurrences. Unlike prior work on memory utilization, which either relies on raw operator visualizations (e.g. attention maps), or simply the total \textit{memory capacity} (i.e. cache size) of a model, our metrics provide highly interpretable and actionable measurements. In particular, we show how ESS can be leveraged to improve initialization strategies, inform novel regularizers and advance the performance-efficiency frontier through model distillation. Furthermore, we demonstrate that the effect of context delimiters (such as end-of-speech tokens) on ESS highlights cross-architectural differences in how large language models utilize their available memory to recall information. Overall, we find that ESS provides valuable insights into the dynamics that dictate memory utilization, enabling the design of more efficient and effective sequence models.
STAR: Synthesis of Tailored Architectures
Nov 26, 2024Iterative improvement of model architectures is fundamental to deep learning: Transformers first enabled scaling, and recent advances in model hybridization have pushed the quality-efficiency frontier. However, optimizing architectures remains challenging and expensive. Current automated or manual approaches fall short, largely due to limited progress in the design of search spaces and due to the simplicity of resulting patterns and heuristics. In this work, we propose a new approach for the synthesis of tailored architectures (STAR). Our approach combines a novel search space based on the theory of linear input-varying systems, supporting a hierarchical numerical encoding into architecture genomes. STAR genomes are automatically refined and recombined with gradient-free, evolutionary algorithms to optimize for multiple model quality and efficiency metrics. Using STAR, we optimize large populations of new architectures, leveraging diverse computational units and interconnection patterns, improving over highly-optimized Transformers and striped hybrid models on the frontier of quality, parameter size, and inference cache for autoregressive language modeling.
Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture
Oct 18, 2023



Machine learning models are increasingly being scaled in both sequence length and model dimension to reach longer contexts and better performance. However, existing architectures such as Transformers scale quadratically along both these axes. We ask: are there performant architectures that can scale sub-quadratically along sequence length and model dimension? We introduce Monarch Mixer (M2), a new architecture that uses the same sub-quadratic primitive along both sequence length and model dimension: Monarch matrices, a simple class of expressive structured matrices that captures many linear transforms, achieves high hardware efficiency on GPUs, and scales sub-quadratically. As a proof of concept, we explore the performance of M2 in three domains: non-causal BERT-style language modeling, ViT-style image classification, and causal GPT-style language modeling. For non-causal BERT-style modeling, M2 matches BERT-base and BERT-large in downstream GLUE quality with up to 27% fewer parameters, and achieves up to 9.1$\times$ higher throughput at sequence length 4K. On ImageNet, M2 outperforms ViT-b by 1% in accuracy, with only half the parameters. Causal GPT-style models introduce a technical challenge: enforcing causality via masking introduces a quadratic bottleneck. To alleviate this bottleneck, we develop a novel theoretical view of Monarch matrices based on multivariate polynomial evaluation and interpolation, which lets us parameterize M2 to be causal while remaining sub-quadratic. Using this parameterization, M2 matches GPT-style Transformers at 360M parameters in pretraining perplexity on The PILE--showing for the first time that it may be possible to match Transformer quality without attention or MLPs.
Simple Hardware-Efficient Long Convolutions for Sequence Modeling
Feb 13, 2023

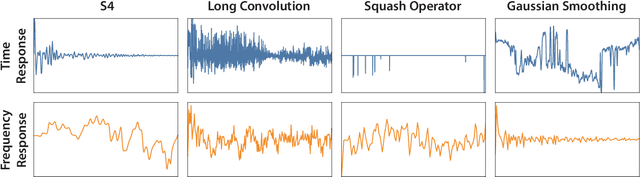

State space models (SSMs) have high performance on long sequence modeling but require sophisticated initialization techniques and specialized implementations for high quality and runtime performance. We study whether a simple alternative can match SSMs in performance and efficiency: directly learning long convolutions over the sequence. We find that a key requirement to achieving high performance is keeping the convolution kernels smooth. We find that simple interventions--such as squashing the kernel weights--result in smooth kernels and recover SSM performance on a range of tasks including the long range arena, image classification, language modeling, and brain data modeling. Next, we develop FlashButterfly, an IO-aware algorithm to improve the runtime performance of long convolutions. FlashButterfly appeals to classic Butterfly decompositions of the convolution to reduce GPU memory IO and increase FLOP utilization. FlashButterfly speeds up convolutions by 2.2$\times$, and allows us to train on Path256, a challenging task with sequence length 64K, where we set state-of-the-art by 29.1 points while training 7.2$\times$ faster than prior work. Lastly, we introduce an extension to FlashButterfly that learns the coefficients of the Butterfly decomposition, increasing expressivity without increasing runtime. Using this extension, we outperform a Transformer on WikiText103 by 0.2 PPL with 30% fewer parameters.
Hungry Hungry Hippos: Towards Language Modeling with State Space Models
Dec 28, 2022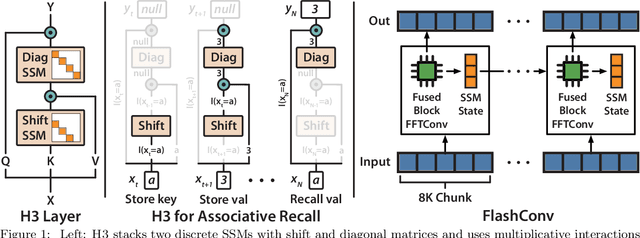



State space models (SSMs) have demonstrated state-of-the-art sequence modeling performance in some modalities, but underperform attention in language modeling. Moreover, despite scaling nearly linearly in sequence length instead of quadratically, SSMs are still slower than Transformers due to poor hardware utilization. In this paper, we make progress on understanding the expressivity gap between SSMs and attention in language modeling, and on reducing the hardware barrier between SSMs and attention. First, we use synthetic language modeling tasks to understand the gap between SSMs and attention. We find that existing SSMs struggle with two capabilities: recalling earlier tokens in the sequence and comparing tokens across the sequence. To understand the impact on language modeling, we propose a new SSM layer, H3, that is explicitly designed for these abilities. H3 matches attention on the synthetic languages and comes within 0.4 PPL of Transformers on OpenWebText. Furthermore, a hybrid 125M-parameter H3-attention model that retains two attention layers surprisingly outperforms Transformers on OpenWebText by 1.0 PPL. Next, to improve the efficiency of training SSMs on modern hardware, we propose FlashConv. FlashConv uses a fused block FFT algorithm to improve efficiency on sequences up to 8K, and introduces a novel state passing algorithm that exploits the recurrent properties of SSMs to scale to longer sequences. FlashConv yields 2$\times$ speedup on the long-range arena benchmark and allows hybrid language models to generate text 1.6$\times$ faster than Transformers. Using FlashConv, we scale hybrid H3-attention language models up to 1.3B parameters on the Pile and find promising initial results, achieving lower perplexity than Transformers and outperforming Transformers in zero- and few-shot learning on a majority of tasks in the SuperGLUE benchmark.
Differentiable programming for functional connectomics
May 31, 2022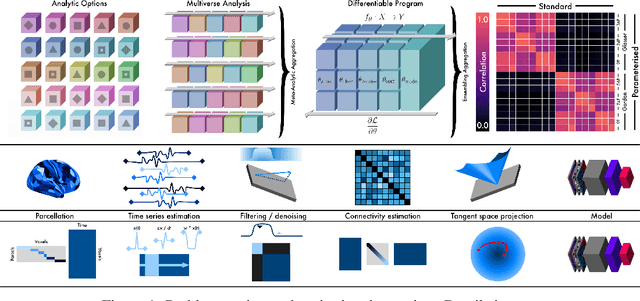

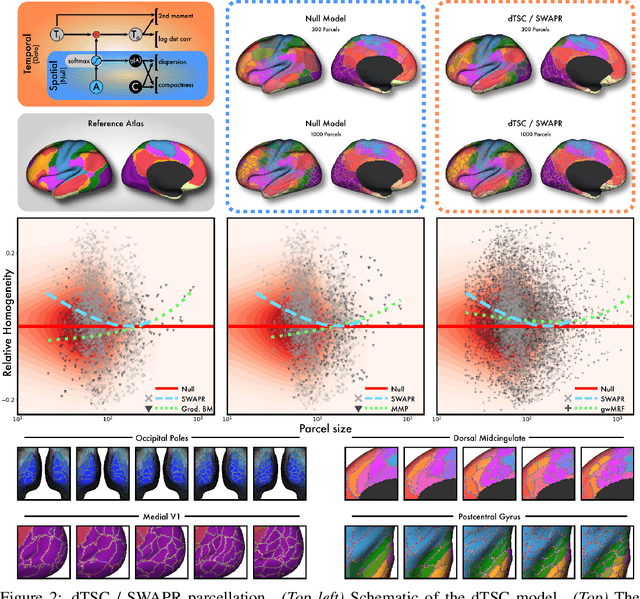
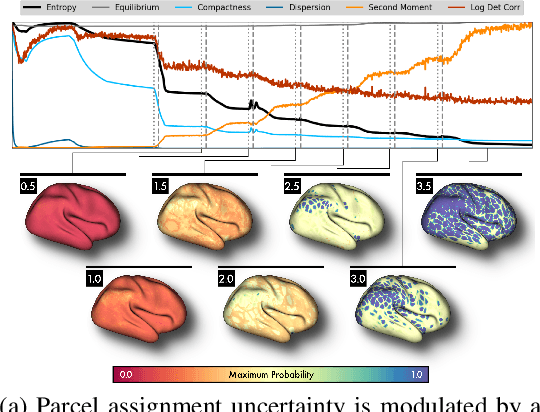
Mapping the functional connectome has the potential to uncover key insights into brain organisation. However, existing workflows for functional connectomics are limited in their adaptability to new data, and principled workflow design is a challenging combinatorial problem. We introduce a new analytic paradigm and software toolbox that implements common operations used in functional connectomics as fully differentiable processing blocks. Under this paradigm, workflow configurations exist as reparameterisations of a differentiable functional that interpolates them. The differentiable program that we envision occupies a niche midway between traditional pipelines and end-to-end neural networks, combining the glass-box tractability and domain knowledge of the former with the amenability to optimisation of the latter. In this preliminary work, we provide a proof of concept for differentiable connectomics, demonstrating the capacity of our processing blocks both to recapitulate canonical knowledge in neuroscience and to make new discoveries in an unsupervised setting. Our differentiable modules are competitive with state-of-the-art methods in problem domains including functional parcellation, denoising, and covariance modelling. Taken together, our results and software demonstrate the promise of differentiable programming for functional connectomics.
Comparing interpretation methods in mental state decoding analyses with deep learning models
May 31, 2022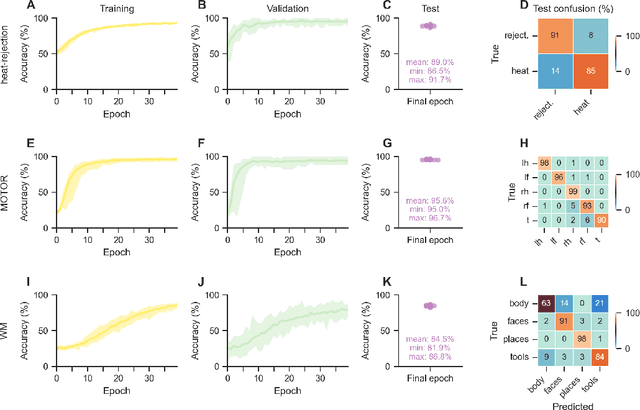
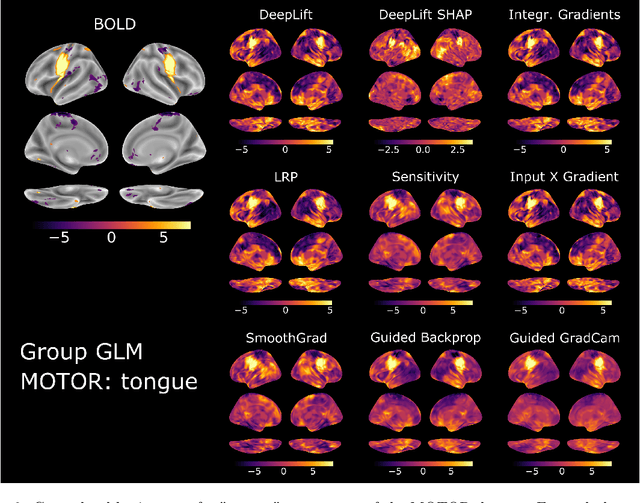
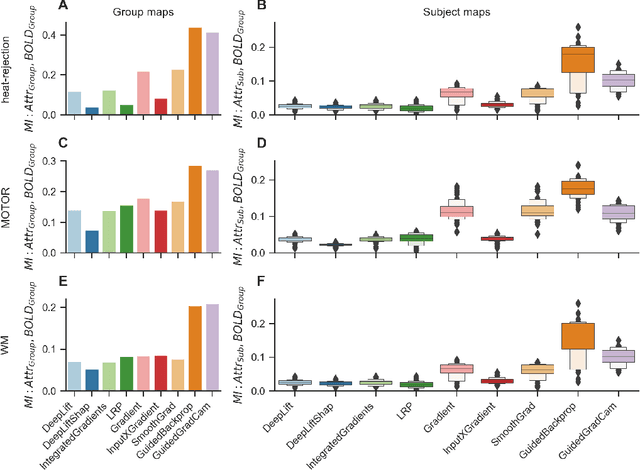
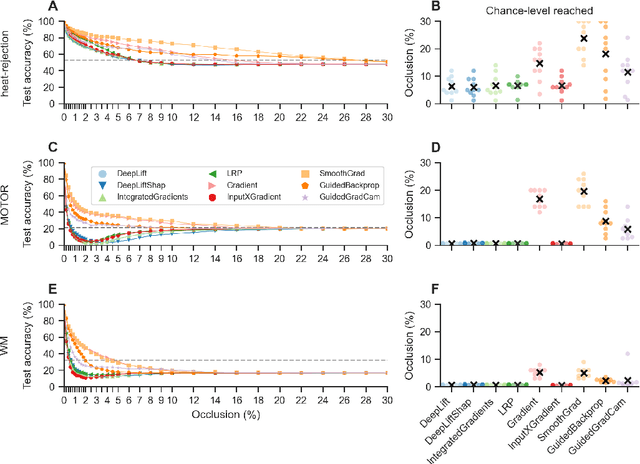
Deep learning (DL) methods find increasing application in mental state decoding, where researchers seek to understand the mapping between mental states (such as accepting or rejecting a gamble) and brain activity, by identifying those brain regions (and networks) whose activity allows to accurately identify (i.e., decode) these states. Once DL models have been trained to accurately decode a set of mental states, neuroimaging researchers often make use of interpretation methods from explainable artificial intelligence research to understand their learned mappings between mental states and brain activity. Here, we compare the explanations of prominent interpretation methods for the mental state decoding decisions of DL models trained on three functional Magnetic Resonance Imaging (fMRI) datasets. We find that interpretation methods that capture the model's decision process well, by producing faithful explanations, generally produce explanations that are less in line with the results of standard analyses of the fMRI data, when compared to the explanations of interpretation methods with less explanation faithfulness. Specifically, we find that interpretation methods that focus on how sensitively a model's decoding decision changes with the values of the input produce explanations that better match with the results of a standard general linear model analysis of the fMRI data, while interpretation methods that focus on identifying the specific contribution of an input feature's value to the decoding decision produce overall more faithful explanations that align less well with the results of standard analyses of the fMRI data.
Evaluating deep transfer learning for whole-brain cognitive decoding
Nov 01, 2021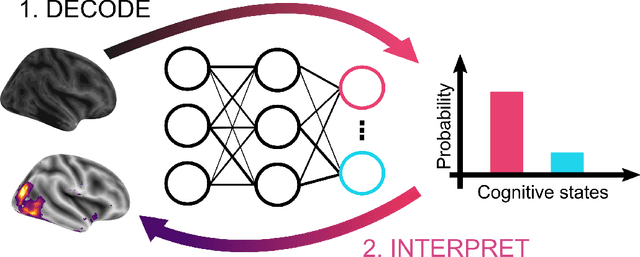
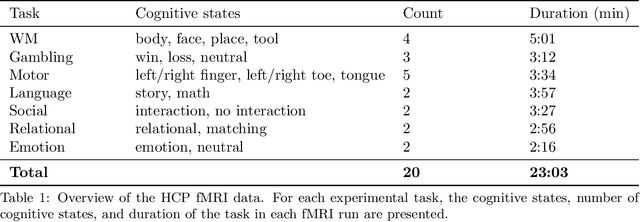
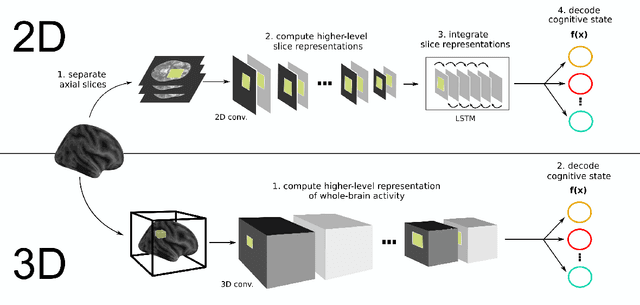
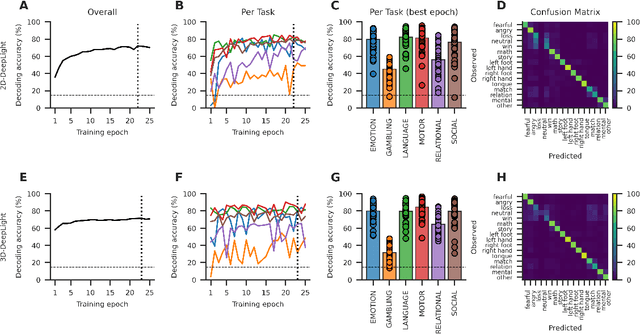
Research in many fields has shown that transfer learning (TL) is well-suited to improve the performance of deep learning (DL) models in datasets with small numbers of samples. This empirical success has triggered interest in the application of TL to cognitive decoding analyses with functional neuroimaging data. Here, we systematically evaluate TL for the application of DL models to the decoding of cognitive states (e.g., viewing images of faces or houses) from whole-brain functional Magnetic Resonance Imaging (fMRI) data. We first pre-train two DL architectures on a large, public fMRI dataset and subsequently evaluate their performance in an independent experimental task and a fully independent dataset. The pre-trained models consistently achieve higher decoding accuracies and generally require less training time and data than model variants that were not pre-trained, clearly underlining the benefits of pre-training. We demonstrate that these benefits arise from the ability of the pre-trained models to reuse many of their learned features when training with new data, providing deeper insights into the mechanisms giving rise to the benefits of pre-training. Yet, we also surface nuanced challenges for whole-brain cognitive decoding with DL models when interpreting the decoding decisions of the pre-trained models, as these have learned to utilize the fMRI data in unforeseen and counterintuitive ways to identify individual cognitive states.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Challenges for cognitive decoding using deep learning methods
Aug 16, 2021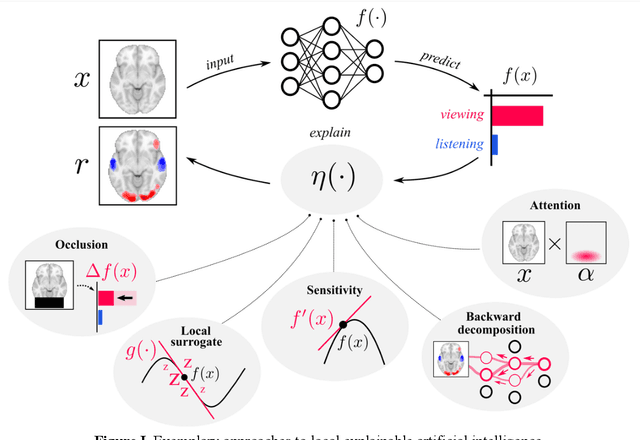
In cognitive decoding, researchers aim to characterize a brain region's representations by identifying the cognitive states (e.g., accepting/rejecting a gamble) that can be identified from the region's activity. Deep learning (DL) methods are highly promising for cognitive decoding, with their unmatched ability to learn versatile representations of complex data. Yet, their widespread application in cognitive decoding is hindered by their general lack of interpretability as well as difficulties in applying them to small datasets and in ensuring their reproducibility and robustness. We propose to approach these challenges by leveraging recent advances in explainable artificial intelligence and transfer learning, while also providing specific recommendations on how to improve the reproducibility and robustness of DL modeling results.