 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Design and Scaling of Hybrid Architectures
Mar 26, 2024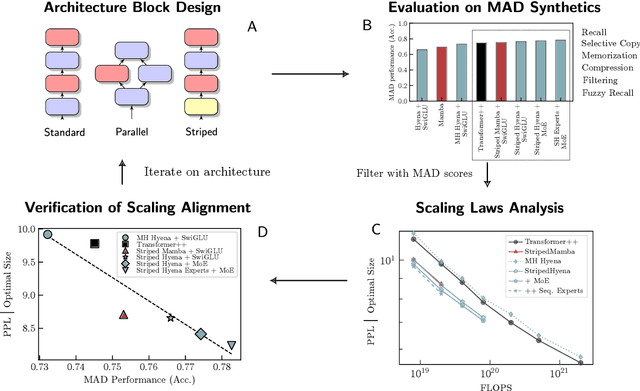

The development of deep learning architectures is a resource-demanding process, due to a vast design space, long prototyping times, and high compute costs associated with at-scale model training and evaluation. We set out to simplify this process by grounding it in an end-to-end mechanistic architecture design (MAD) pipeline, encompassing small-scale capability unit tests predictive of scaling laws. Through a suite of synthetic token manipulation tasks such as compression and recall, designed to probe capabilities, we identify and test new hybrid architectures constructed from a variety of computational primitives. We experimentally validate the resulting architectures via an extensive compute-optimal and a new state-optimal scaling law analysis, training over 500 language models between 70M to 7B parameters. Surprisingly, we find MAD synthetics to correlate with compute-optimal perplexity, enabling accurate evaluation of new architectures via isolated proxy tasks. The new architectures found via MAD, based on simple ideas such as hybridization and sparsity, outperform state-of-the-art Transformer, convolutional, and recurrent architectures (Transformer++, Hyena, Mamba) in scaling, both at compute-optimal budgets and in overtrained regimes. Overall, these results provide evidence that performance on curated synthetic tasks can be predictive of scaling laws, and that an optimal architecture should leverage specialized layers via a hybrid topology.
FlashFFTConv: Efficient Convolutions for Long Sequences with Tensor Cores
Nov 10, 2023



Convolution models with long filters have demonstrated state-of-the-art reasoning abilities in many long-sequence tasks but lag behind the most optimized Transformers in wall-clock time. A major bottleneck is the Fast Fourier Transform (FFT)--which allows long convolutions to run in $O(N logN)$ time in sequence length $N$ but has poor hardware utilization. In this paper, we study how to optimize the FFT convolution. We find two key bottlenecks: the FFT does not effectively use specialized matrix multiply units, and it incurs expensive I/O between layers of the memory hierarchy. In response, we propose FlashFFTConv. FlashFFTConv uses a matrix decomposition that computes the FFT using matrix multiply units and enables kernel fusion for long sequences, reducing I/O. We also present two sparse convolution algorithms--1) partial convolutions and 2) frequency-sparse convolutions--which can be implemented simply by skipping blocks in the matrix decomposition, enabling further opportunities for memory and compute savings. FlashFFTConv speeds up exact FFT convolutions by up to 7.93$\times$ over PyTorch and achieves up to 4.4$\times$ speedup end-to-end. Given the same compute budget, FlashFFTConv allows Hyena-GPT-s to achieve 2.3 points better perplexity on the PILE and M2-BERT-base to achieve 3.3 points higher GLUE score--matching models with twice the parameter count. FlashFFTConv also achieves 96.1% accuracy on Path-512, a high-resolution vision task where no model had previously achieved better than 50%. Furthermore, partial convolutions enable longer-sequence models--yielding the first DNA model that can process the longest human genes (2.3M base pairs)--and frequency-sparse convolutions speed up pretrained models while maintaining or improving model quality.
HyenaDNA: Long-Range Genomic Sequence Modeling at Single Nucleotide Resolution
Jun 27, 2023Genomic (DNA) sequences encode an enormous amount of information for gene regulation and protein synthesis. Similar to natural language models, researchers have proposed foundation models in genomics to learn generalizable features from unlabeled genome data that can then be fine-tuned for downstream tasks such as identifying regulatory elements. Due to the quadratic scaling of attention, previous Transformer-based genomic models have used 512 to 4k tokens as context (<0.001% of the human genome), significantly limiting the modeling of long-range interactions in DNA. In addition, these methods rely on tokenizers to aggregate meaningful DNA units, losing single nucleotide resolution where subtle genetic variations can completely alter protein function via single nucleotide polymorphisms (SNPs). Recently, Hyena, a large language model based on implicit convolutions was shown to match attention in quality while allowing longer context lengths and lower time complexity. Leveraging Hyenas new long-range capabilities, we present HyenaDNA, a genomic foundation model pretrained on the human reference genome with context lengths of up to 1 million tokens at the single nucleotide-level, an up to 500x increase over previous dense attention-based models. HyenaDNA scales sub-quadratically in sequence length (training up to 160x faster than Transformer), uses single nucleotide tokens, and has full global context at each layer. We explore what longer context enables - including the first use of in-context learning in genomics for simple adaptation to novel tasks without updating pretrained model weights. On fine-tuned benchmarks from the Nucleotide Transformer, HyenaDNA reaches state-of-the-art (SotA) on 12 of 17 datasets using a model with orders of magnitude less parameters and pretraining data. On the GenomicBenchmarks, HyenaDNA surpasses SotA on all 8 datasets on average by +9 accuracy points.
Hyena Hierarchy: Towards Larger Convolutional Language Models
Mar 06, 2023


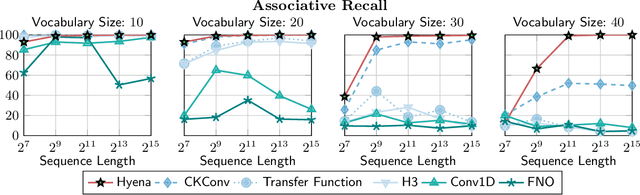
Recent advances in deep learning have relied heavily on the use of large Transformers due to their ability to learn at scale. However, the core building block of Transformers, the attention operator, exhibits quadratic cost in sequence length, limiting the amount of context accessible. Existing subquadratic methods based on low-rank and sparse approximations need to be combined with dense attention layers to match Transformers, indicating a gap in capability. In this work, we propose Hyena, a subquadratic drop-in replacement for attention constructed by interleaving implicitly parametrized long convolutions and data-controlled gating. In recall and reasoning tasks on sequences of thousands to hundreds of thousands of tokens, Hyena improves accuracy by more than 50 points over operators relying on state-spaces and other implicit and explicit methods, matching attention-based models. We set a new state-of-the-art for dense-attention-free architectures on language modeling in standard datasets (WikiText103 and The Pile), reaching Transformer quality with a 20% reduction in training compute required at sequence length 2K. Hyena operators are twice as fast as highly optimized attention at sequence length 8K, and 100x faster at sequence length 64K.
Simple Hardware-Efficient Long Convolutions for Sequence Modeling
Feb 13, 2023

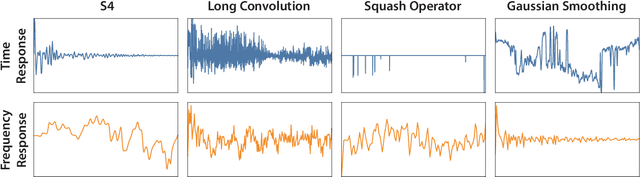

State space models (SSMs) have high performance on long sequence modeling but require sophisticated initialization techniques and specialized implementations for high quality and runtime performance. We study whether a simple alternative can match SSMs in performance and efficiency: directly learning long convolutions over the sequence. We find that a key requirement to achieving high performance is keeping the convolution kernels smooth. We find that simple interventions--such as squashing the kernel weights--result in smooth kernels and recover SSM performance on a range of tasks including the long range arena, image classification, language modeling, and brain data modeling. Next, we develop FlashButterfly, an IO-aware algorithm to improve the runtime performance of long convolutions. FlashButterfly appeals to classic Butterfly decompositions of the convolution to reduce GPU memory IO and increase FLOP utilization. FlashButterfly speeds up convolutions by 2.2$\times$, and allows us to train on Path256, a challenging task with sequence length 64K, where we set state-of-the-art by 29.1 points while training 7.2$\times$ faster than prior work. Lastly, we introduce an extension to FlashButterfly that learns the coefficients of the Butterfly decomposition, increasing expressivity without increasing runtime. Using this extension, we outperform a Transformer on WikiText103 by 0.2 PPL with 30% fewer parameters.
S4ND: Modeling Images and Videos as Multidimensional Signals Using State Spaces
Oct 14, 2022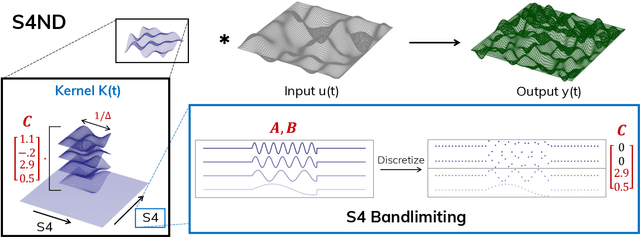
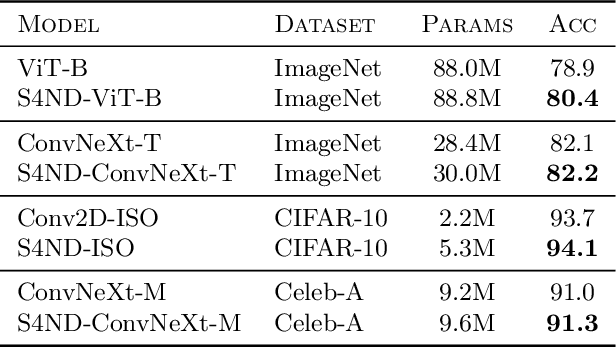
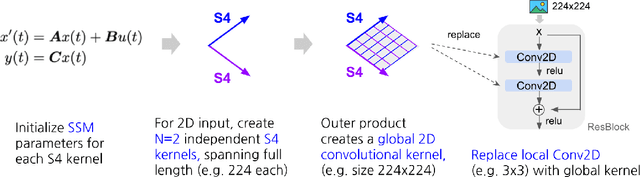
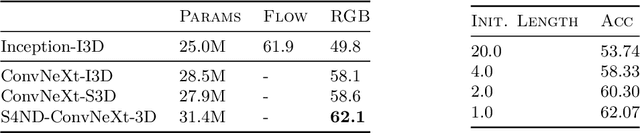
Visual data such as images and videos are typically modeled as discretizations of inherently continuous, multidimensional signals. Existing continuous-signal models attempt to exploit this fact by modeling the underlying signals of visual (e.g., image) data directly. However, these models have not yet been able to achieve competitive performance on practical vision tasks such as large-scale image and video classification. Building on a recent line of work on deep state space models (SSMs), we propose S4ND, a new multidimensional SSM layer that extends the continuous-signal modeling ability of SSMs to multidimensional data including images and videos. We show that S4ND can model large-scale visual data in $1$D, $2$D, and $3$D as continuous multidimensional signals and demonstrates strong performance by simply swapping Conv2D and self-attention layers with S4ND layers in existing state-of-the-art models. On ImageNet-1k, S4ND exceeds the performance of a Vision Transformer baseline by $1.5\%$ when training with a $1$D sequence of patches, and matches ConvNeXt when modeling images in $2$D. For videos, S4ND improves on an inflated $3$D ConvNeXt in activity classification on HMDB-51 by $4\%$. S4ND implicitly learns global, continuous convolutional kernels that are resolution invariant by construction, providing an inductive bias that enables generalization across multiple resolutions. By developing a simple bandlimiting modification to S4 to overcome aliasing, S4ND achieves strong zero-shot (unseen at training time) resolution performance, outperforming a baseline Conv2D by $40\%$ on CIFAR-10 when trained on $8 \times 8$ and tested on $32 \times 32$ images. When trained with progressive resizing, S4ND comes within $\sim 1\%$ of a high-resolution model while training $22\%$ faster.
Continual Reinforcement Learning with TELLA
Aug 08, 2022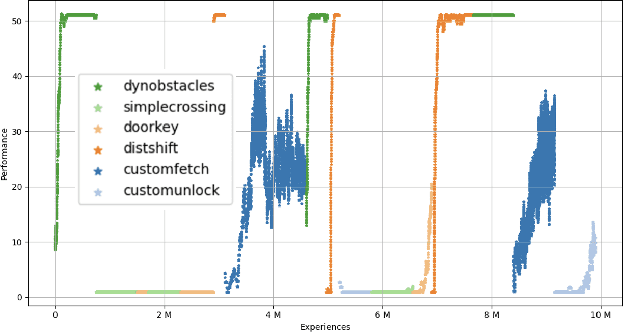
Training reinforcement learning agents that continually learn across multiple environments is a challenging problem. This is made more difficult by a lack of reproducible experiments and standard metrics for comparing different continual learning approaches. To address this, we present TELLA, a tool for the Test and Evaluation of Lifelong Learning Agents. TELLA provides specified, reproducible curricula to lifelong learning agents while logging detailed data for evaluation and standardized analysis. Researchers can define and share their own curricula over various learning environments or run against a curriculum created under the DARPA Lifelong Learning Machines (L2M) Program.
Lifelong Learning Metrics
Jan 20, 2022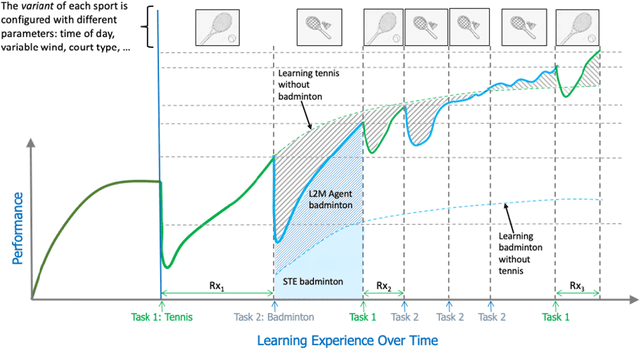
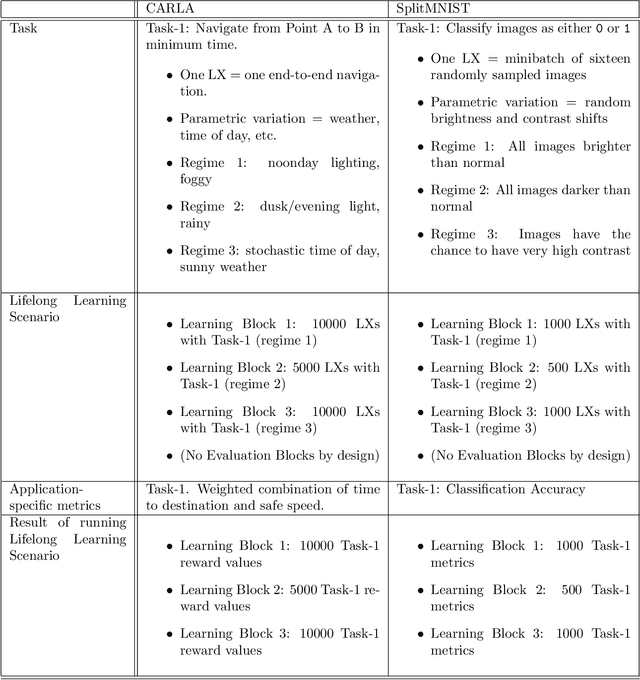
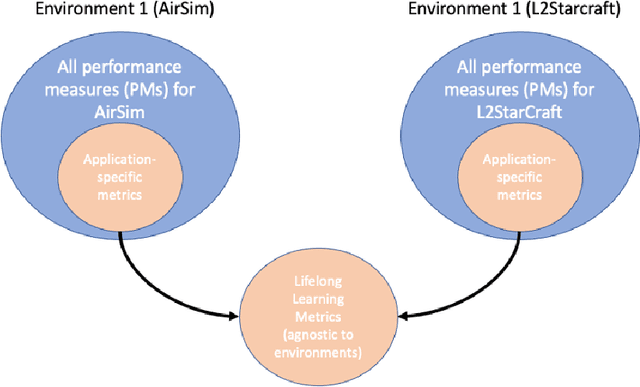
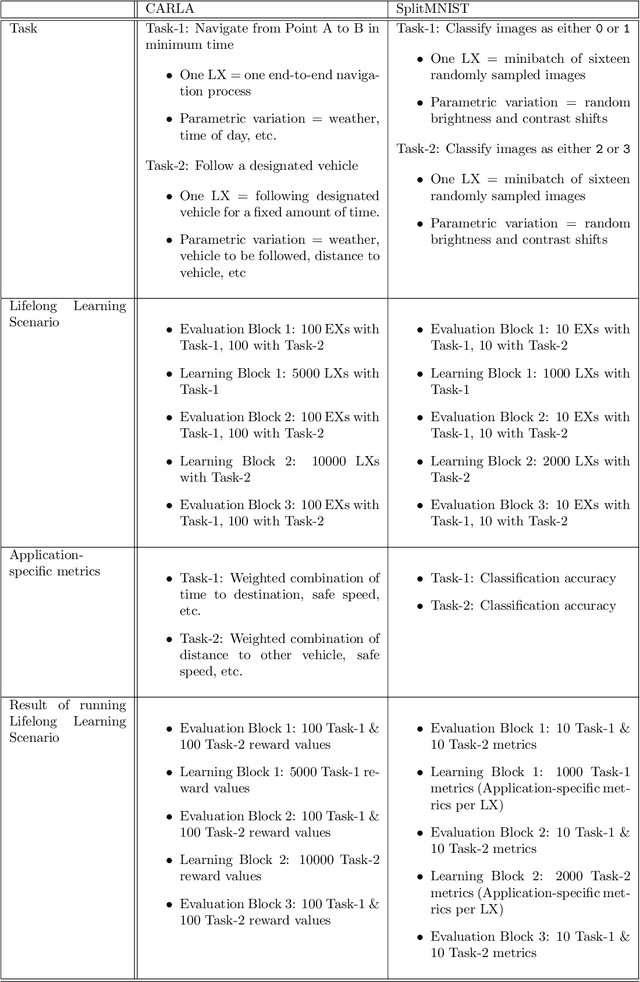
The DARPA Lifelong Learning Machines (L2M) program seeks to yield advances in artificial intelligence (AI) systems so that they are capable of learning (and improving) continuously, leveraging data on one task to improve performance on another, and doing so in a computationally sustainable way. Performers on this program developed systems capable of performing a diverse range of functions, including autonomous driving, real-time strategy, and drone simulation. These systems featured a diverse range of characteristics (e.g., task structure, lifetime duration), and an immediate challenge faced by the program's testing and evaluation team was measuring system performance across these different settings. This document, developed in close collaboration with DARPA and the program performers, outlines a formalism for constructing and characterizing the performance of agents performing lifelong learning scenarios.
OSCAR-Net: Object-centric Scene Graph Attention for Image Attribution
Aug 07, 2021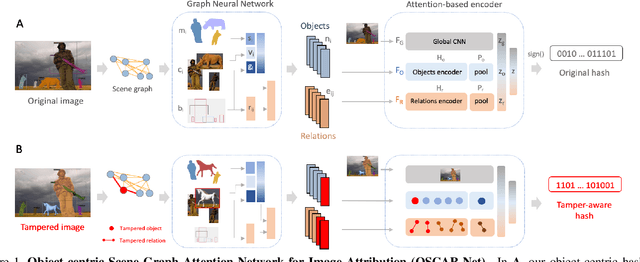
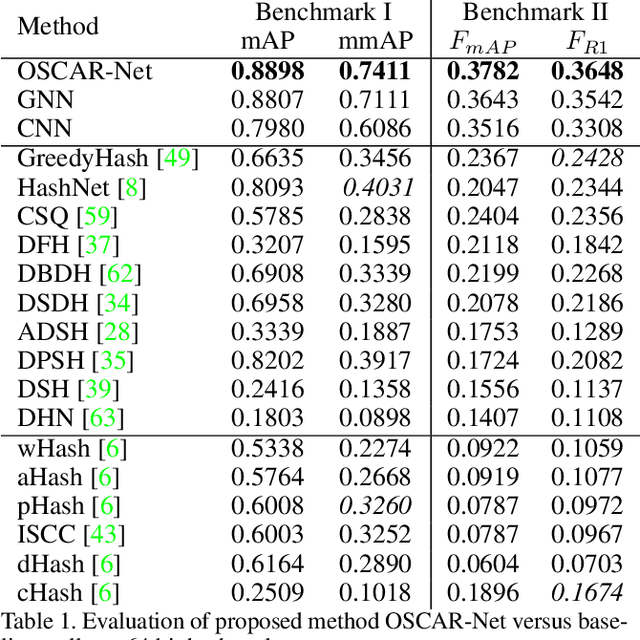

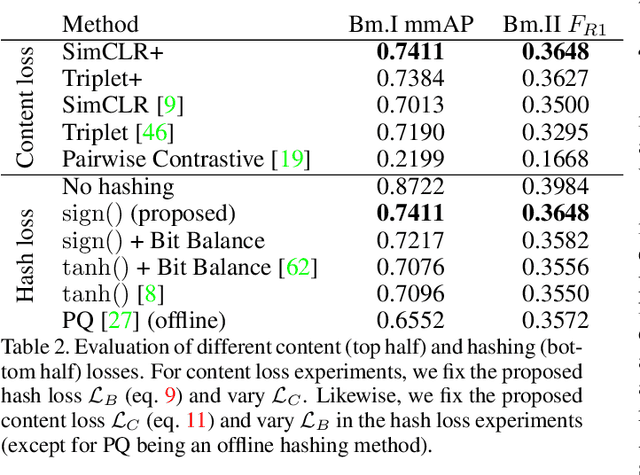
Images tell powerful stories but cannot always be trusted. Matching images back to trusted sources (attribution) enables users to make a more informed judgment of the images they encounter online. We propose a robust image hashing algorithm to perform such matching. Our hash is sensitive to manipulation of subtle, salient visual details that can substantially change the story told by an image. Yet the hash is invariant to benign transformations (changes in quality, codecs, sizes, shapes, etc.) experienced by images during online redistribution. Our key contribution is OSCAR-Net (Object-centric Scene Graph Attention for Image Attribution Network); a robust image hashing model inspired by recent successes of Transformers in the visual domain. OSCAR-Net constructs a scene graph representation that attends to fine-grained changes of every object's visual appearance and their spatial relationships. The network is trained via contrastive learning on a dataset of original and manipulated images yielding a state of the art image hash for content fingerprinting that scales to millions of images.