 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPN: Video Provenance Network for Robust Content Attribution
Sep 21, 2021


We present VPN - a content attribution method for recovering provenance information from videos shared online. Platforms, and users, often transform video into different quality, codecs, sizes, shapes, etc. or slightly edit its content such as adding text or emoji, as they are redistributed online. We learn a robust search embedding for matching such video, invariant to these transformations, using full-length or truncated video queries. Once matched against a trusted database of video clips, associated information on the provenance of the clip is presented to the user. We use an inverted index to match temporal chunks of video using late-fusion to combine both visual and audio features. In both cases, features are extracted via a deep neural network trained using contrastive learning on a dataset of original and augmented video clips. We demonstrate high accuracy recall over a corpus of 100,000 videos.
OSCAR-Net: Object-centric Scene Graph Attention for Image Attribution
Aug 07, 2021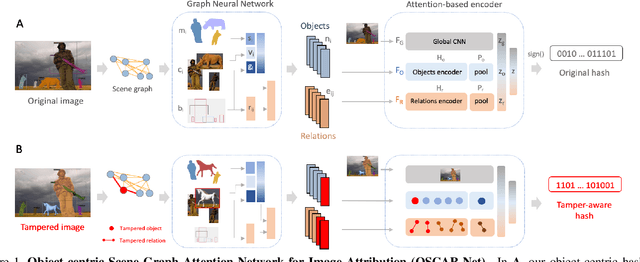
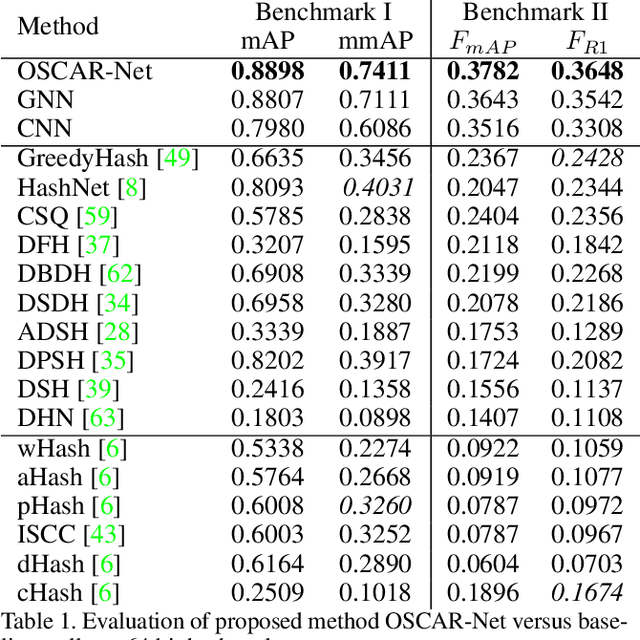

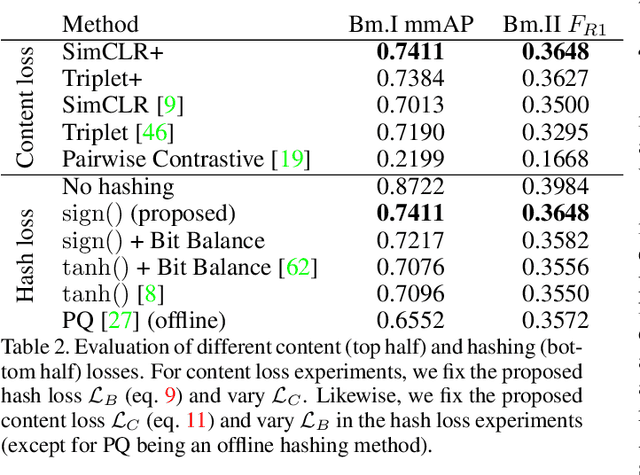
Images tell powerful stories but cannot always be trusted. Matching images back to trusted sources (attribution) enables users to make a more informed judgment of the images they encounter online. We propose a robust image hashing algorithm to perform such matching. Our hash is sensitive to manipulation of subtle, salient visual details that can substantially change the story told by an image. Yet the hash is invariant to benign transformations (changes in quality, codecs, sizes, shapes, etc.) experienced by images during online redistribution. Our key contribution is OSCAR-Net (Object-centric Scene Graph Attention for Image Attribution Network); a robust image hashing model inspired by recent successes of Transformers in the visual domain. OSCAR-Net constructs a scene graph representation that attends to fine-grained changes of every object's visual appearance and their spatial relationships. The network is trained via contrastive learning on a dataset of original and manipulated images yielding a state of the art image hash for content fingerprinting that scales to millions of images.