 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Than the Final Answer: Improving Visual Extraction and Logical Consistency in Vision-Language Models
Dec 13, 2025Reinforcement learning from verifiable rewards (RLVR) has recently been extended from text-only LLMs to vision-language models (VLMs) to elicit long-chain multimodal reasoning. However, RLVR-trained VLMs still exhibit two persistent failure modes: inaccurate visual extraction (missing or hallucinating details) and logically inconsistent chains-of-thought, largely because verifiable signals supervise only the final answer. We propose PeRL-VL (Perception and Reasoning Learning for Vision-Language Models), a decoupled framework that separately improves visual perception and textual reasoning on top of RLVR. For perception, PeRL-VL introduces a VLM-based description reward that scores the model's self-generated image descriptions for faithfulness and sufficiency. For reasoning, PeRL-VL adds a text-only Reasoning SFT stage on logic-rich chain-of-thought data, enhancing coherence and logical consistency independently of vision. Across diverse multimodal benchmarks, PeRL-VL improves average Pass@1 accuracy from 63.3% (base Qwen2.5-VL-7B) to 68.8%, outperforming standard RLVR, text-only reasoning SFT, and naive multimodal distillation from GPT-4o.
FRAME: Pre-Training Video Feature Representations via Anticipation and Memory
Jun 05, 2025Dense video prediction tasks, such as object tracking and semantic segmentation, require video encoders that generate temporally consistent, spatially dense features for every frame. However, existing approaches fall short: image encoders like DINO or CLIP lack temporal awareness, while video models such as VideoMAE underperform compared to image encoders on dense prediction tasks. We address this gap with FRAME, a self-supervised video frame encoder tailored for dense video understanding. FRAME learns to predict current and future DINO patch features from past and present RGB frames, leading to spatially precise and temporally coherent representations. To our knowledge, FRAME is the first video encoder to leverage image-based models for dense prediction while outperforming them on tasks requiring fine-grained visual correspondence. As an auxiliary capability, FRAME aligns its class token with CLIP's semantic space, supporting language-driven tasks such as video classification. We evaluate FRAME across six dense prediction tasks on seven datasets, where it consistently outperforms image encoders and existing self-supervised video models. Despite its versatility, FRAME maintains a compact architecture suitable for a range of downstream applications.
MAGNET: Augmenting Generative Decoders with Representation Learning and Infilling Capabilities
Jan 15, 2025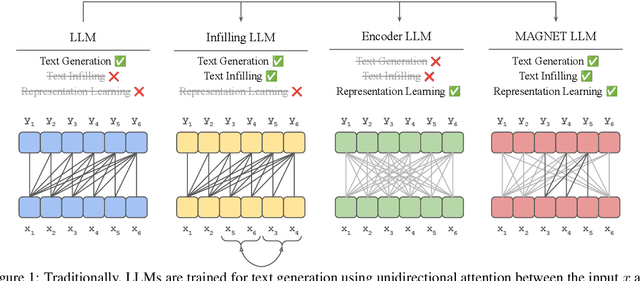
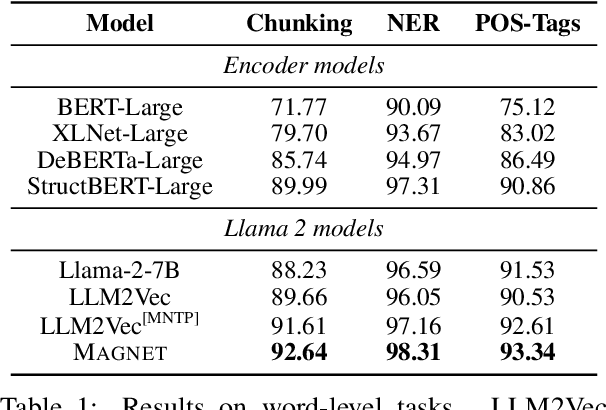
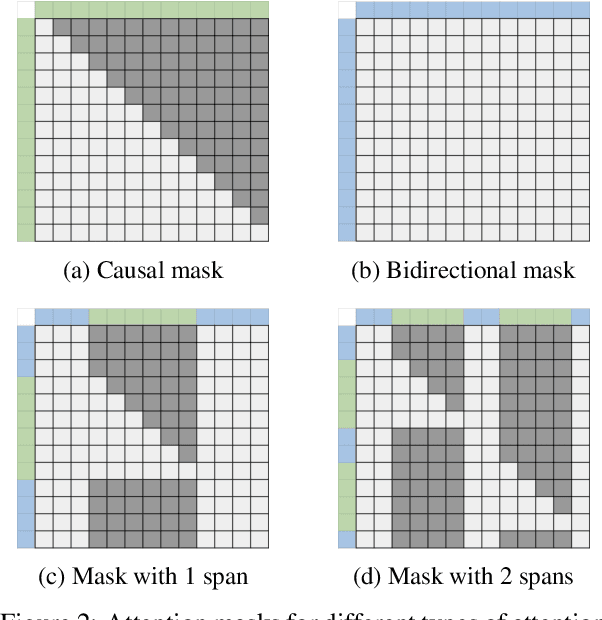
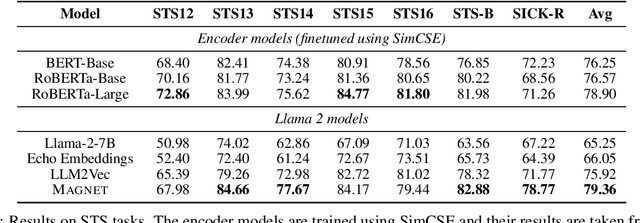
While originally designed for unidirectional generative modeling, decoder-only large language models (LLMs) are increasingly being adapted for bidirectional modeling. However, unidirectional and bidirectional models are typically trained separately with distinct objectives (generation and representation learning, respectively). This separation overlooks the opportunity for developing a more versatile language model and for these objectives to complement each other. In this work, we introduce MAGNET, an adaptation of decoder-only LLMs that enhances their ability to generate robust representations and infill missing text spans, while preserving their knowledge and text generation capabilities. MAGNET employs three self-supervised training objectives and introduces an attention mechanism that combines bidirectional and causal attention, enabling unified training across all objectives. Our results demonstrate that LLMs adapted with MAGNET (1) surpass strong text encoders on token-level and sentence-level representation learning tasks, (2) generate contextually appropriate text infills by leveraging future context, (3) retain the ability for open-ended text generation without exhibiting repetition problem, and (4) preserve the knowledge gained by the LLM during pretraining.
Sync from the Sea: Retrieving Alignable Videos from Large-Scale Datasets
Sep 02, 2024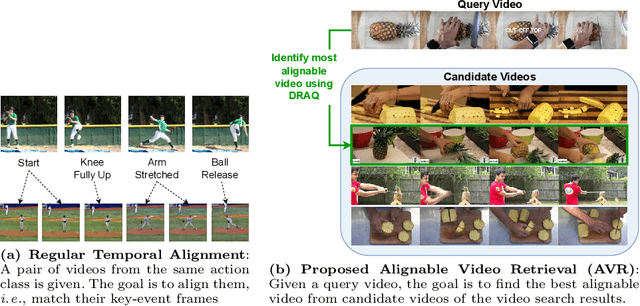

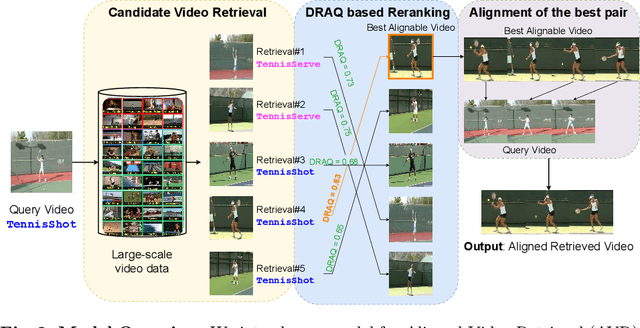

Temporal video alignment aims to synchronize the key events like object interactions or action phase transitions in two videos. Such methods could benefit various video editing, processing, and understanding tasks. However, existing approaches operate under the restrictive assumption that a suitable video pair for alignment is given, significantly limiting their broader applicability. To address this, we re-pose temporal alignment as a search problem and introduce the task of Alignable Video Retrieval (AVR). Given a query video, our approach can identify well-alignable videos from a large collection of clips and temporally synchronize them to the query. To achieve this, we make three key contributions: 1) we introduce DRAQ, a video alignability indicator to identify and re-rank the best alignable video from a set of candidates; 2) we propose an effective and generalizable frame-level video feature design to improve the alignment performance of several off-the-shelf feature representations, and 3) we propose a novel benchmark and evaluation protocol for AVR using cycle-consistency metrics. Our experiments on 3 datasets, including large-scale Kinetics700, demonstrate the effectiveness of our approach in identifying alignable video pairs from diverse datasets. Project Page: https://daveishan.github.io/avr-webpage/.
FINEMATCH: Aspect-based Fine-grained Image and Text Mismatch Detection and Correction
Apr 23, 2024

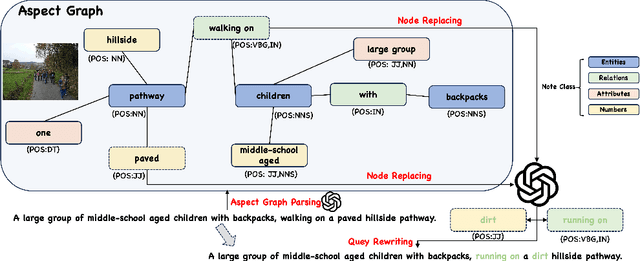
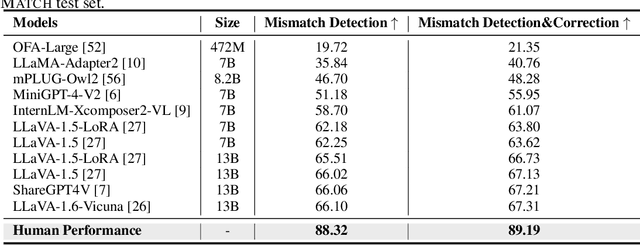
Recent progress in large-scale pre-training has led to the development of advanced vision-language models (VLMs) with remarkable proficiency in comprehending and generating multimodal content. Despite the impressive ability to perform complex reasoning for VLMs, current models often struggle to effectively and precisely capture the compositional information on both the image and text sides. To address this, we propose FineMatch, a new aspect-based fine-grained text and image matching benchmark, focusing on text and image mismatch detection and correction. This benchmark introduces a novel task for boosting and evaluating the VLMs' compositionality for aspect-based fine-grained text and image matching. In this task, models are required to identify mismatched aspect phrases within a caption, determine the aspect's class, and propose corrections for an image-text pair that may contain between 0 and 3 mismatches. To evaluate the models' performance on this new task, we propose a new evaluation metric named ITM-IoU for which our experiments show a high correlation to human evaluation. In addition, we also provide a comprehensive experimental analysis of existing mainstream VLMs, including fully supervised learning and in-context learning settings. We have found that models trained on FineMatch demonstrate enhanced proficiency in detecting fine-grained text and image mismatches. Moreover, models (e.g., GPT-4V, Gemini Pro Vision) with strong abilities to perform multimodal in-context learning are not as skilled at fine-grained compositional image and text matching analysis. With FineMatch, we are able to build a system for text-to-image generation hallucination detection and correction.
Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
Apr 05, 2024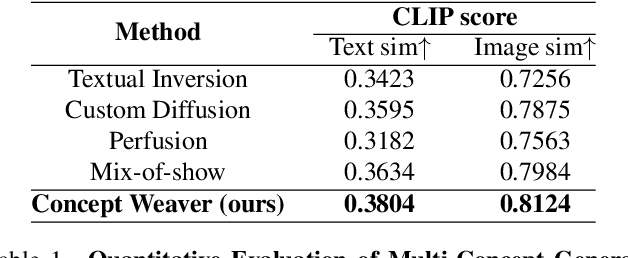
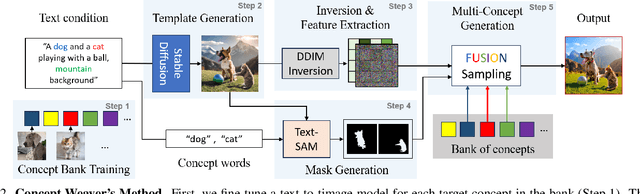
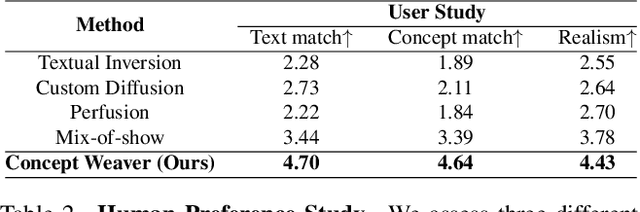
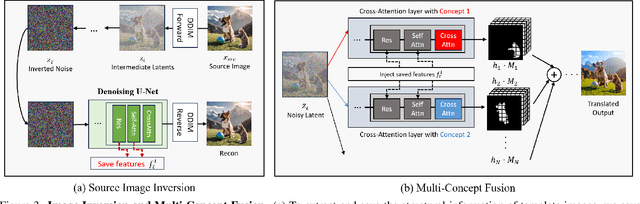
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.
No More Shortcuts: Realizing the Potential of Temporal Self-Supervision
Dec 20, 2023Self-supervised approaches for video have shown impressive results in video understanding tasks. However, unlike early works that leverage temporal self-supervision, current state-of-the-art methods primarily rely on tasks from the image domain (e.g., contrastive learning) that do not explicitly promote the learning of temporal features. We identify two factors that limit existing temporal self-supervision: 1) tasks are too simple, resulting in saturated training performance, and 2) we uncover shortcuts based on local appearance statistics that hinder the learning of high-level features. To address these issues, we propose 1) a more challenging reformulation of temporal self-supervision as frame-level (rather than clip-level) recognition tasks and 2) an effective augmentation strategy to mitigate shortcuts. Our model extends a representation of single video frames, pre-trained through contrastive learning, with a transformer that we train through temporal self-supervision. We demonstrate experimentally that our more challenging frame-level task formulations and the removal of shortcuts drastically improve the quality of features learned through temporal self-supervision. The generalization capability of our self-supervised video method is evidenced by its state-of-the-art performance in a wide range of high-level semantic tasks, including video retrieval, action classification, and video attribute recognition (such as object and scene identification), as well as low-level temporal correspondence tasks like video object segmentation and pose tracking. Additionally, we show that the video representations learned through our method exhibit increased robustness to the input perturbations.
DECORAIT -- DECentralized Opt-in/out Registry for AI Training
Sep 25, 2023
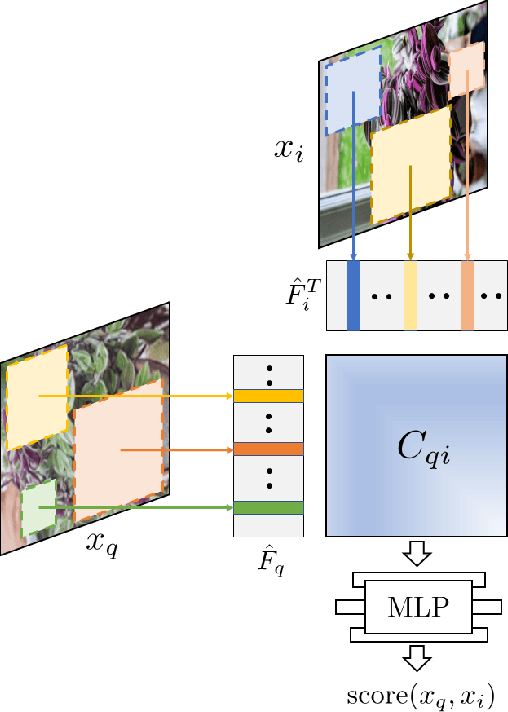
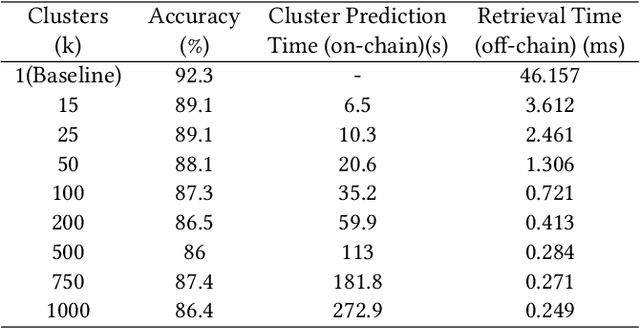
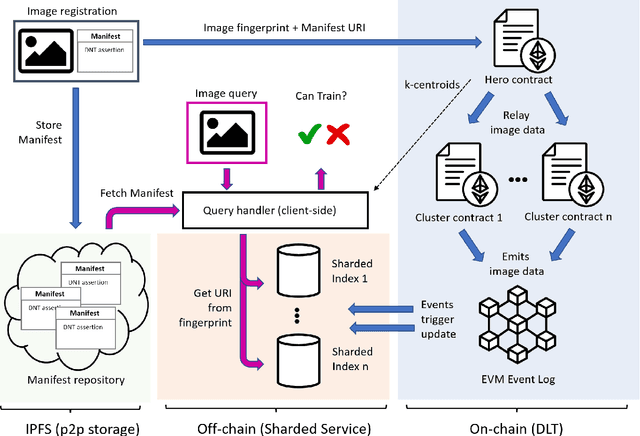
We present DECORAIT; a decentralized registry through which content creators may assert their right to opt in or out of AI training as well as receive reward for their contributions. Generative AI (GenAI) enables images to be synthesized using AI models trained on vast amounts of data scraped from public sources. Model and content creators who may wish to share their work openly without sanctioning its use for training are thus presented with a data governance challenge. Further, establishing the provenance of GenAI training data is important to creatives to ensure fair recognition and reward for their such use. We report a prototype of DECORAIT, which explores hierarchical clustering and a combination of on/off-chain storage to create a scalable decentralized registry to trace the provenance of GenAI training data in order to determine training consent and reward creatives who contribute that data. DECORAIT combines distributed ledger technology (DLT) with visual fingerprinting, leveraging the emerging C2PA (Coalition for Content Provenance and Authenticity) standard to create a secure, open registry through which creatives may express consent and data ownership for GenAI.
Meta-Personalizing Vision-Language Models to Find Named Instances in Video
Jun 16, 2023Large-scale vision-language models (VLM) have shown impressive results for language-guided search applications. While these models allow category-level queries, they currently struggle with personalized searches for moments in a video where a specific object instance such as ``My dog Biscuit'' appears. We present the following three contributions to address this problem. First, we describe a method to meta-personalize a pre-trained VLM, i.e., learning how to learn to personalize a VLM at test time to search in video. Our method extends the VLM's token vocabulary by learning novel word embeddings specific to each instance. To capture only instance-specific features, we represent each instance embedding as a combination of shared and learned global category features. Second, we propose to learn such personalization without explicit human supervision. Our approach automatically identifies moments of named visual instances in video using transcripts and vision-language similarity in the VLM's embedding space. Finally, we introduce This-Is-My, a personal video instance retrieval benchmark. We evaluate our approach on This-Is-My and DeepFashion2 and show that we obtain a 15% relative improvement over the state of the art on the latter dataset.
EKILA: Synthetic Media Provenance and Attribution for Generative Art
Apr 10, 2023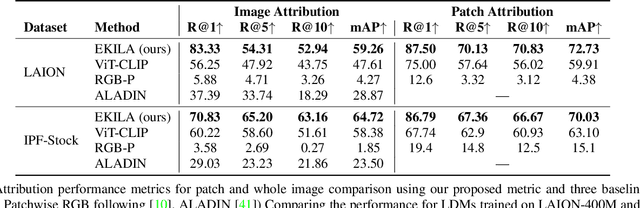
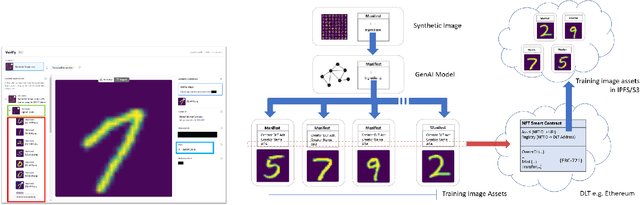
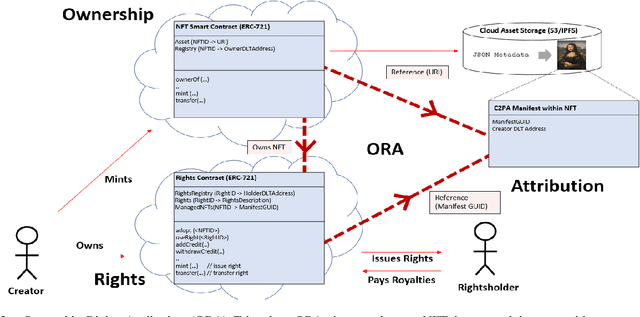

We present EKILA; a decentralized framework that enables creatives to receive recognition and reward for their contributions to generative AI (GenAI). EKILA proposes a robust visual attribution technique and combines this with an emerging content provenance standard (C2PA) to address the problem of synthetic image provenance -- determining the generative model and training data responsible for an AI-generated image. Furthermore, EKILA extends the non-fungible token (NFT) ecosystem to introduce a tokenized representation for rights, enabling a triangular relationship between the asset's Ownership, Rights, and Attribution (ORA). Leveraging the ORA relationship enables creators to express agency over training consent and, through our attribution model, to receive apportioned credit, including royalty payments for the use of their assets in GenAI.