 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAME: Pre-Training Video Feature Representations via Anticipation and Memory
Jun 05, 2025Dense video prediction tasks, such as object tracking and semantic segmentation, require video encoders that generate temporally consistent, spatially dense features for every frame. However, existing approaches fall short: image encoders like DINO or CLIP lack temporal awareness, while video models such as VideoMAE underperform compared to image encoders on dense prediction tasks. We address this gap with FRAME, a self-supervised video frame encoder tailored for dense video understanding. FRAME learns to predict current and future DINO patch features from past and present RGB frames, leading to spatially precise and temporally coherent representations. To our knowledge, FRAME is the first video encoder to leverage image-based models for dense prediction while outperforming them on tasks requiring fine-grained visual correspondence. As an auxiliary capability, FRAME aligns its class token with CLIP's semantic space, supporting language-driven tasks such as video classification. We evaluate FRAME across six dense prediction tasks on seven datasets, where it consistently outperforms image encoders and existing self-supervised video models. Despite its versatility, FRAME maintains a compact architecture suitable for a range of downstream applications.
REN: Fast and Efficient Region Encodings from Patch-Based Image Encoders
May 23, 2025



We introduce the Region Encoder Network (REN), a fast and effective model for generating region-based image representations using point prompts. Recent methods combine class-agnostic segmenters (e.g., SAM) with patch-based image encoders (e.g., DINO) to produce compact and effective region representations, but they suffer from high computational cost due to the segmentation step. REN bypasses this bottleneck using a lightweight module that directly generates region tokens, enabling 60x faster token generation with 35x less memory, while also improving token quality. It uses a few cross-attention blocks that take point prompts as queries and features from a patch-based image encoder as keys and values to produce region tokens that correspond to the prompted objects. We train REN with three popular encoders-DINO, DINOv2, and OpenCLIP-and show that it can be extended to other encoders without dedicated training. We evaluate REN on semantic segmentation and retrieval tasks, where it consistently outperforms the original encoders in both performance and compactness, and matches or exceeds SAM-based region methods while being significantly faster. Notably, REN achieves state-of-the-art results on the challenging Ego4D VQ2D benchmark and outperforms proprietary LMMs on Visual Haystacks' single-needle challenge. Code and models are available at: https://github.com/savya08/REN.
Can Self Reported Symptoms Predict Daily COVID-19 Cases?
May 18, 2021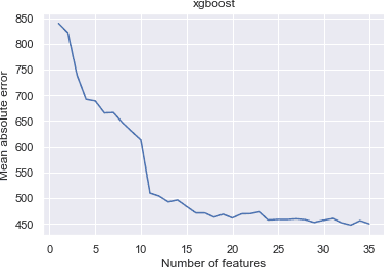
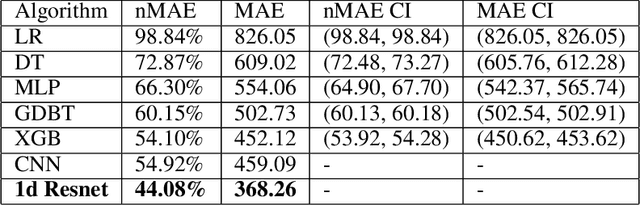
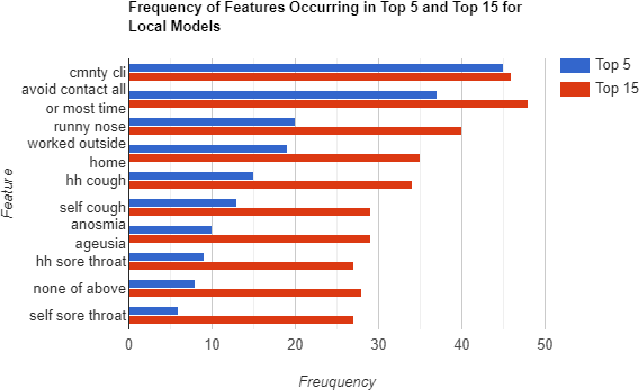

The COVID-19 pandemic has impacted lives and economies across the globe, leading to many deaths. While vaccination is an important intervention, its roll-out is slow and unequal across the globe. Therefore, extensive testing still remains one of the key methods to monitor and contain the virus. Testing on a large scale is expensive and arduous. Hence, we need alternate methods to estimate the number of cases. Online surveys have been shown to be an effective method for data collection amidst the pandemic. In this work, we develop machine learning models to estimate the prevalence of COVID-19 using self-reported symptoms. Our best model predicts the daily cases with a mean absolute error (MAE) of 226.30 (normalized MAE of 27.09%) per state, which demonstrates the possibility of predicting the actual number of confirmed cases by utilizing self-reported symptoms. The models are developed at two levels of data granularity - local models, which are trained at the state level, and a single global model which is trained on the combined data aggregated across all states. Our results indicate a lower error on the local models as opposed to the global model. In addition, we also show that the most important symptoms (features) vary considerably from state to state. This work demonstrates that the models developed on crowd-sourced data, curated via online platforms, can complement the existing epidemiological surveillance infrastructure in a cost-effective manner.