 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpliHuMoN: Simplifying Human Motion Prediction
Mar 04, 2026Human motion prediction combines the tasks of trajectory forecasting and human pose prediction. For each of the two tasks, specialized models have been developed. Combining these models for holistic human motion prediction is non-trivial, and recent methods have struggled to compete on established benchmarks for individual tasks. To address this, we propose a simple yet effective transformer-based model for human motion prediction. The model employs a stack of self-attention modules to effectively capture both spatial dependencies within a pose and temporal relationships across a motion sequence. This simple, streamlined, end-to-end model is sufficiently versatile to handle pose-only, trajectory-only, and combined prediction tasks without task-specific modifications. We demonstrate that this approach achieves state-of-the-art results across all tasks through extensive experiments on a wide range of benchmark datasets, including Human3.6M, AMASS, ETH-UCY, and 3DPW.
VideoSketcher: Video Models Prior Enable Versatile Sequential Sketch Generation
Feb 17, 2026Sketching is inherently a sequential process, in which strokes are drawn in a meaningful order to explore and refine ideas. However, most generative models treat sketches as static images, overlooking the temporal structure that underlies creative drawing. We present a data-efficient approach for sequential sketch generation that adapts pretrained text-to-video diffusion models to generate sketching processes. Our key insight is that large language models and video diffusion models offer complementary strengths for this task: LLMs provide semantic planning and stroke ordering, while video diffusion models serve as strong renderers that produce high-quality, temporally coherent visuals. We leverage this by representing sketches as short videos in which strokes are progressively drawn on a blank canvas, guided by text-specified ordering instructions. We introduce a two-stage fine-tuning strategy that decouples the learning of stroke ordering from the learning of sketch appearance. Stroke ordering is learned using synthetic shape compositions with controlled temporal structure, while visual appearance is distilled from as few as seven manually authored sketching processes that capture both global drawing order and the continuous formation of individual strokes. Despite the extremely limited amount of human-drawn sketch data, our method generates high-quality sequential sketches that closely follow text-specified orderings while exhibiting rich visual detail. We further demonstrate the flexibility of our approach through extensions such as brush style conditioning and autoregressive sketch generation, enabling additional controllability and interactive, collaborative drawing.
Bridging Diffusion Models and 3D Representations: A 3D Consistent Super-Resolution Framework
Aug 06, 2025We propose 3D Super Resolution (3DSR), a novel 3D Gaussian-splatting-based super-resolution framework that leverages off-the-shelf diffusion-based 2D super-resolution models. 3DSR encourages 3D consistency across views via the use of an explicit 3D Gaussian-splatting-based scene representation. This makes the proposed 3DSR different from prior work, such as image upsampling or the use of video super-resolution, which either don't consider 3D consistency or aim to incorporate 3D consistency implicitly. Notably, our method enhances visual quality without additional fine-tuning, ensuring spatial coherence within the reconstructed scene. We evaluate 3DSR on MipNeRF360 and LLFF data, demonstrating that it produces high-resolution results that are visually compelling, while maintaining structural consistency in 3D reconstructions. Code will be released.
REN: Fast and Efficient Region Encodings from Patch-Based Image Encoders
May 23, 2025



We introduce the Region Encoder Network (REN), a fast and effective model for generating region-based image representations using point prompts. Recent methods combine class-agnostic segmenters (e.g., SAM) with patch-based image encoders (e.g., DINO) to produce compact and effective region representations, but they suffer from high computational cost due to the segmentation step. REN bypasses this bottleneck using a lightweight module that directly generates region tokens, enabling 60x faster token generation with 35x less memory, while also improving token quality. It uses a few cross-attention blocks that take point prompts as queries and features from a patch-based image encoder as keys and values to produce region tokens that correspond to the prompted objects. We train REN with three popular encoders-DINO, DINOv2, and OpenCLIP-and show that it can be extended to other encoders without dedicated training. We evaluate REN on semantic segmentation and retrieval tasks, where it consistently outperforms the original encoders in both performance and compactness, and matches or exceeds SAM-based region methods while being significantly faster. Notably, REN achieves state-of-the-art results on the challenging Ego4D VQ2D benchmark and outperforms proprietary LMMs on Visual Haystacks' single-needle challenge. Code and models are available at: https://github.com/savya08/REN.
The Curse of Conditions: Analyzing and Improving Optimal Transport for Conditional Flow-Based Generation
Mar 13, 2025



Minibatch optimal transport coupling straightens paths in unconditional flow matching. This leads to computationally less demanding inference as fewer integration steps and less complex numerical solvers can be employed when numerically solving an ordinary differential equation at test time. However, in the conditional setting, minibatch optimal transport falls short. This is because the default optimal transport mapping disregards conditions, resulting in a conditionally skewed prior distribution during training. In contrast, at test time, we have no access to the skewed prior, and instead sample from the full, unbiased prior distribution. This gap between training and testing leads to a subpar performance. To bridge this gap, we propose conditional optimal transport C^2OT that adds a conditional weighting term in the cost matrix when computing the optimal transport assignment. Experiments demonstrate that this simple fix works with both discrete and continuous conditions in 8gaussians-to-moons, CIFAR-10, ImageNet-32x32, and ImageNet-256x256. Our method performs better overall compared to the existing baselines across different function evaluation budgets. Code is available at https://hkchengrex.github.io/C2OT
Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
Dec 19, 2024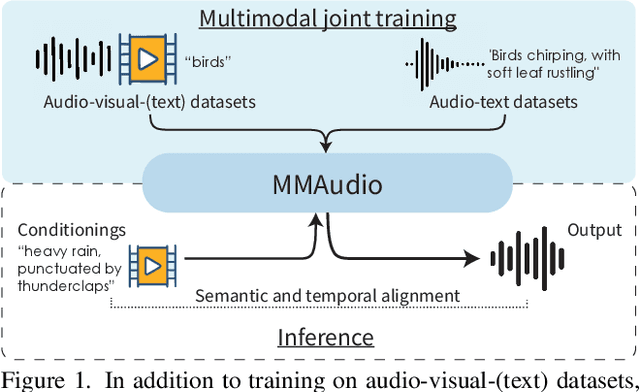
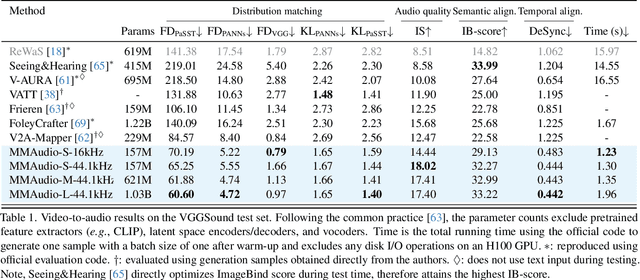
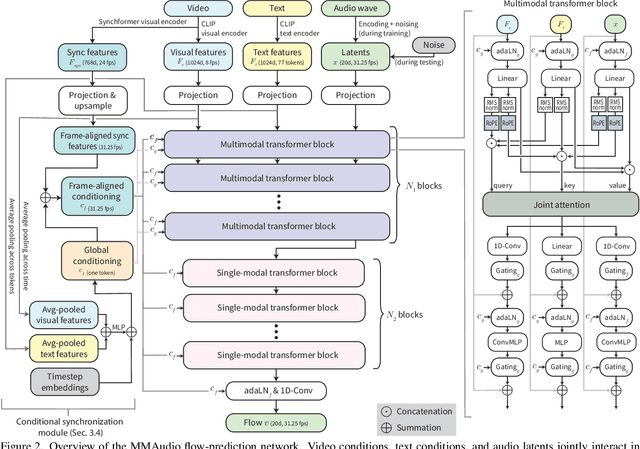
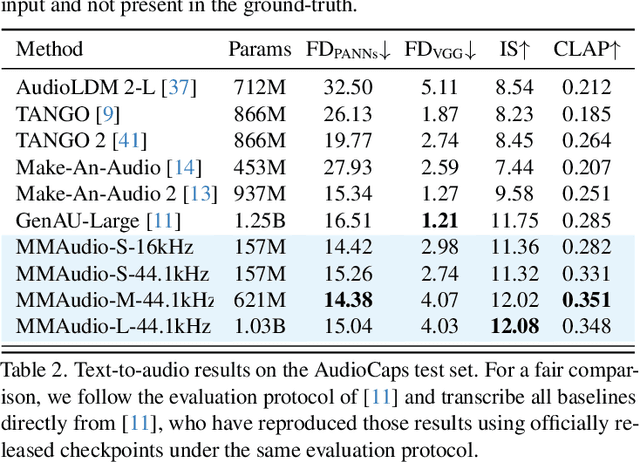
We propose to synthesize high-quality and synchronized audio, given video and optional text conditions, using a novel multimodal joint training framework MMAudio. In contrast to single-modality training conditioned on (limited) video data only, MMAudio is jointly trained with larger-scale, readily available text-audio data to learn to generate semantically aligned high-quality audio samples. Additionally, we improve audio-visual synchrony with a conditional synchronization module that aligns video conditions with audio latents at the frame level. Trained with a flow matching objective, MMAudio achieves new video-to-audio state-of-the-art among public models in terms of audio quality, semantic alignment, and audio-visual synchronization, while having a low inference time (1.23s to generate an 8s clip) and just 157M parameters. MMAudio also achieves surprisingly competitive performance in text-to-audio generation, showing that joint training does not hinder single-modality performance. Code and demo are available at: https://hkchengrex.github.io/MMAudio
MV-DUSt3R+: Single-Stage Scene Reconstruction from Sparse Views In 2 Seconds
Dec 09, 2024
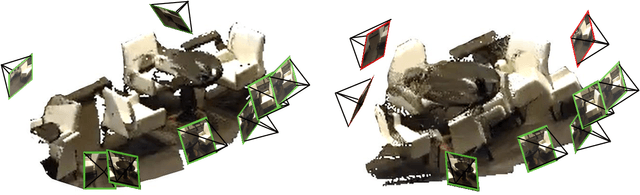
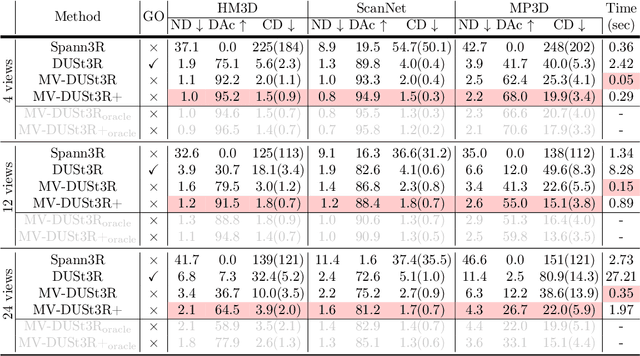
Recent sparse multi-view scene reconstruction advances like DUSt3R and MASt3R no longer require camera calibration and camera pose estimation. However, they only process a pair of views at a time to infer pixel-aligned pointmaps. When dealing with more than two views, a combinatorial number of error prone pairwise reconstructions are usually followed by an expensive global optimization, which often fails to rectify the pairwise reconstruction errors. To handle more views, reduce errors, and improve inference time, we propose the fast single-stage feed-forward network MV-DUSt3R. At its core are multi-view decoder blocks which exchange information across any number of views while considering one reference view. To make our method robust to reference view selection, we further propose MV-DUSt3R+, which employs cross-reference-view blocks to fuse information across different reference view choices. To further enable novel view synthesis, we extend both by adding and jointly training Gaussian splatting heads. Experiments on multi-view stereo reconstruction, multi-view pose estimation, and novel view synthesis confirm that our methods improve significantly upon prior art. Code will be released.
RELOCATE: A Simple Training-Free Baseline for Visual Query Localization Using Region-Based Representations
Dec 02, 2024We present RELOCATE, a simple training-free baseline designed to perform the challenging task of visual query localization in long videos. To eliminate the need for task-specific training and efficiently handle long videos, RELOCATE leverages a region-based representation derived from pretrained vision models. At a high level, it follows the classic object localization approach: (1) identify all objects in each video frame, (2) compare the objects with the given query and select the most similar ones, and (3) perform bidirectional tracking to get a spatio-temporal response. However, we propose some key enhancements to handle small objects, cluttered scenes, partial visibility, and varying appearances. Notably, we refine the selected objects for accurate localization and generate additional visual queries to capture visual variations. We evaluate RELOCATE on the challenging Ego4D Visual Query 2D Localization dataset, establishing a new baseline that outperforms prior task-specific methods by 49% (relative improvement) in spatio-temporal average precision.
On Inductive Biases That Enable Generalization of Diffusion Transformers
Oct 28, 2024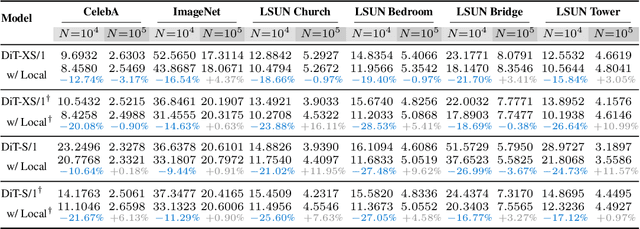
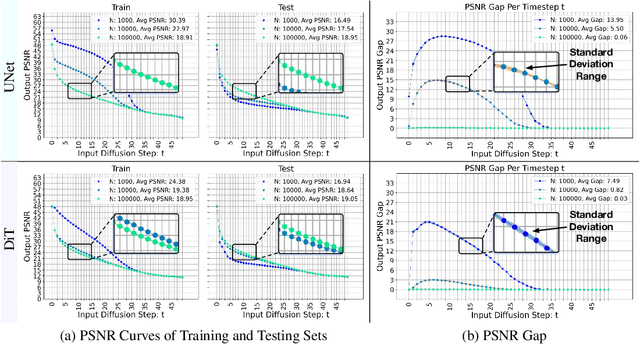
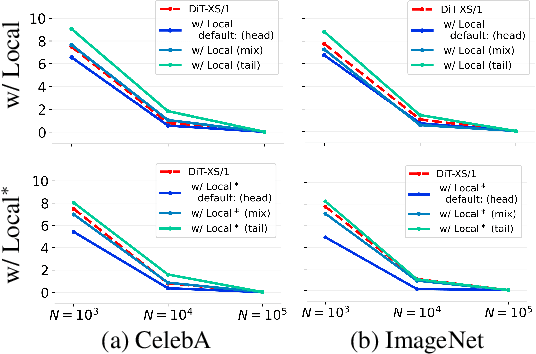
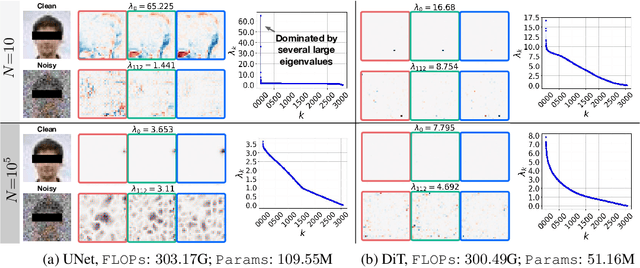
Recent work studying the generalization of diffusion models with UNet-based denoisers reveals inductive biases that can be expressed via geometry-adaptive harmonic bases. However, in practice, more recent denoising networks are often based on transformers, e.g., the diffusion transformer (DiT). This raises the question: do transformer-based denoising networks exhibit inductive biases that can also be expressed via geometry-adaptive harmonic bases? To our surprise, we find that this is not the case. This discrepancy motivates our search for the inductive bias that can lead to good generalization in DiT models. Investigating the pivotal attention modules of a DiT, we find that locality of attention maps are closely associated with generalization. To verify this finding, we modify the generalization of a DiT by restricting its attention windows. We inject local attention windows to a DiT and observe an improvement in generalization. Furthermore, we empirically find that both the placement and the effective attention size of these local attention windows are crucial factors. Experimental results on the CelebA, ImageNet, and LSUN datasets show that strengthening the inductive bias of a DiT can improve both generalization and generation quality when less training data is available. Source code will be released publicly upon paper publication. Project page: dit-generalization.github.io/.
Pixel-Aligned Multi-View Generation with Depth Guided Decoder
Aug 26, 2024
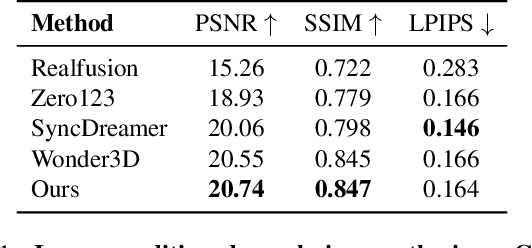
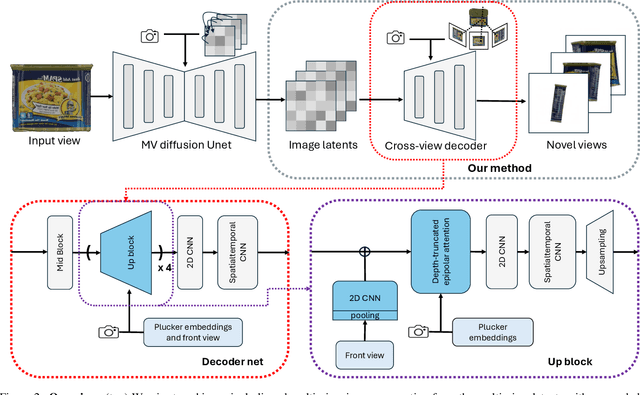

The task of image-to-multi-view generation refers to generating novel views of an instance from a single image. Recent methods achieve this by extending text-to-image latent diffusion models to multi-view version, which contains an VAE image encoder and a U-Net diffusion model. Specifically, these generation methods usually fix VAE and finetune the U-Net only. However, the significant downscaling of the latent vectors computed from the input images and independent decoding leads to notable pixel-level misalignment across multiple views. To address this, we propose a novel method for pixel-level image-to-multi-view generation. Unlike prior work, we incorporate attention layers across multi-view images in the VAE decoder of a latent video diffusion model. Specifically, we introduce a depth-truncated epipolar attention, enabling the model to focus on spatially adjacent regions while remaining memory efficient. Applying depth-truncated attn is challenging during inference as the ground-truth depth is usually difficult to obtain and pre-trained depth estimation models is hard to provide accurate depth. Thus, to enhance the generalization to inaccurate depth when ground truth depth is missing, we perturb depth inputs during training. During inference, we employ a rapid multi-view to 3D reconstruction approach, NeuS, to obtain coarse depth for the depth-truncated epipolar attention. Our model enables better pixel alignment across multi-view images. Moreover, we demonstrate the efficacy of our approach in improving downstream multi-view to 3D reconstruction tasks.