 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying Classifier(-Free) Guidance From a Classifier-Centric Perspective
Mar 13, 2025Classifier-free guidance has become a staple for conditional generation with denoising diffusion models. However, a comprehensive understanding of classifier-free guidance is still missing. In this work, we carry out an empirical study to provide a fresh perspective on classifier-free guidance. Concretely, instead of solely focusing on classifier-free guidance, we trace back to the root, i.e., classifier guidance, pinpoint the key assumption for the derivation, and conduct a systematic study to understand the role of the classifier. We find that both classifier guidance and classifier-free guidance achieve conditional generation by pushing the denoising diffusion trajectories away from decision boundaries, i.e., areas where conditional information is usually entangled and is hard to learn. Based on this classifier-centric understanding, we propose a generic postprocessing step built upon flow-matching to shrink the gap between the learned distribution for a pre-trained denoising diffusion model and the real data distribution, majorly around the decision boundaries. Experiments on various datasets verify the effectiveness of the proposed approach.
PDC & DM-SFT: A Road for LLM SQL Bug-Fix Enhancing
Nov 11, 2024



Code Large Language Models (Code LLMs), such as Code llama and DeepSeek-Coder, have demonstrated exceptional performance in the code generation tasks. However, most existing models focus on the abilities of generating correct code, but often struggle with bug repair. We introduce a suit of methods to enhance LLM's SQL bug-fixing abilities. The methods are mainly consisted of two parts: A Progressive Dataset Construction (PDC) from scratch and Dynamic Mask Supervised Fine-tuning (DM-SFT). PDC proposes two data expansion methods from the perspectives of breadth first and depth first respectively. DM-SFT introduces an efficient bug-fixing supervised learning approach, which effectively reduce the total training steps and mitigate the "disorientation" in SQL code bug-fixing training. In our evaluation, the code LLM models trained with two methods have exceeds all current best performing model which size is much larger.
NeRFDeformer: NeRF Transformation from a Single View via 3D Scene Flows
Jun 15, 2024We present a method for automatically modifying a NeRF representation based on a single observation of a non-rigid transformed version of the original scene. Our method defines the transformation as a 3D flow, specifically as a weighted linear blending of rigid transformations of 3D anchor points that are defined on the surface of the scene. In order to identify anchor points, we introduce a novel correspondence algorithm that first matches RGB-based pairs, then leverages multi-view information and 3D reprojection to robustly filter false positives in two steps. We also introduce a new dataset for exploring the problem of modifying a NeRF scene through a single observation. Our dataset ( https://github.com/nerfdeformer/nerfdeformer ) contains 113 synthetic scenes leveraging 47 3D assets. We show that our proposed method outperforms NeRF editing methods as well as diffusion-based methods, and we also explore different methods for filtering correspondences.
IllumiNeRF: 3D Relighting without Inverse Rendering
Jun 10, 2024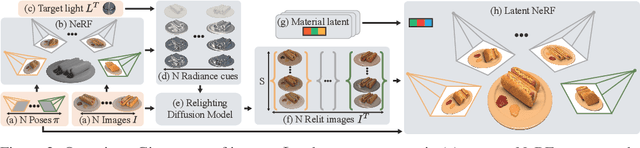



Existing methods for relightable view synthesis -- using a set of images of an object under unknown lighting to recover a 3D representation that can be rendered from novel viewpoints under a target illumination -- are based on inverse rendering, and attempt to disentangle the object geometry, materials, and lighting that explain the input images. Furthermore, this typically involves optimization through differentiable Monte Carlo rendering, which is brittle and computationally-expensive. In this work, we propose a simpler approach: we first relight each input image using an image diffusion model conditioned on lighting and then reconstruct a Neural Radiance Field (NeRF) with these relit images, from which we render novel views under the target lighting. We demonstrate that this strategy is surprisingly competitive and achieves state-of-the-art results on multiple relighting benchmarks. Please see our project page at https://illuminerf.github.io/.
Robust Knowledge Distillation Based on Feature Variance Against Backdoored Teacher Model
Jun 01, 2024



Benefiting from well-trained deep neural networks (DNNs), model compression have captured special attention for computing resource limited equipment, especially edge devices. Knowledge distillation (KD) is one of the widely used compression techniques for edge deployment, by obtaining a lightweight student model from a well-trained teacher model released on public platforms. However, it has been empirically noticed that the backdoor in the teacher model will be transferred to the student model during the process of KD. Although numerous KD methods have been proposed, most of them focus on the distillation of a high-performing student model without robustness consideration. Besides, some research adopts KD techniques as effective backdoor mitigation tools, but they fail to perform model compression at the same time. Consequently, it is still an open problem to well achieve two objectives of robust KD, i.e., student model's performance and backdoor mitigation. To address these issues, we propose RobustKD, a robust knowledge distillation that compresses the model while mitigating backdoor based on feature variance. Specifically, RobustKD distinguishes the previous works in three key aspects: (1) effectiveness: by distilling the feature map of the teacher model after detoxification, the main task performance of the student model is comparable to that of the teacher model; (2) robustness: by reducing the characteristic variance between the teacher model and the student model, it mitigates the backdoor of the student model under backdoored teacher model scenario; (3) generic: RobustKD still has good performance in the face of multiple data models (e.g., WRN 28-4, Pyramid-200) and diverse DNNs (e.g., ResNet50, MobileNet).
GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-Mesh
Apr 11, 2024We introduce GoMAvatar, a novel approach for real-time, memory-efficient, high-quality animatable human modeling. GoMAvatar takes as input a single monocular video to create a digital avatar capable of re-articulation in new poses and real-time rendering from novel viewpoints, while seamlessly integrating with rasterization-based graphics pipelines. Central to our method is the Gaussians-on-Mesh representation, a hybrid 3D model combining rendering quality and speed of Gaussian splatting with geometry modeling and compatibility of deformable meshes. We assess GoMAvatar on ZJU-MoCap data and various YouTube videos. GoMAvatar matches or surpasses current monocular human modeling algorithms in rendering quality and significantly outperforms them in computational efficiency (43 FPS) while being memory-efficient (3.63 MB per subject).
Is Generalized Dynamic Novel View Synthesis from Monocular Videos Possible Today?
Oct 12, 2023



Rendering scenes observed in a monocular video from novel viewpoints is a challenging problem. For static scenes the community has studied both scene-specific optimization techniques, which optimize on every test scene, and generalized techniques, which only run a deep net forward pass on a test scene. In contrast, for dynamic scenes, scene-specific optimization techniques exist, but, to our best knowledge, there is currently no generalized method for dynamic novel view synthesis from a given monocular video. To answer whether generalized dynamic novel view synthesis from monocular videos is possible today, we establish an analysis framework based on existing techniques and work toward the generalized approach. We find a pseudo-generalized process without scene-specific appearance optimization is possible, but geometrically and temporally consistent depth estimates are needed. Despite no scene-specific appearance optimization, the pseudo-generalized approach improves upon some scene-specific methods.
ALIKED: A Lighter Keypoint and Descriptor Extraction Network via Deformable Transformation
Apr 16, 2023Image keypoints and descriptors play a crucial role in many visual measurement tasks. In recent years, deep neural networks have been widely used to improve the performance of keypoint and descriptor extraction. However, the conventional convolution operations do not provide the geometric invariance required for the descriptor. To address this issue, we propose the Sparse Deformable Descriptor Head (SDDH), which learns the deformable positions of supporting features for each keypoint and constructs deformable descriptors. Furthermore, SDDH extracts descriptors at sparse keypoints instead of a dense descriptor map, which enables efficient extraction of descriptors with strong expressiveness. In addition, we relax the neural reprojection error (NRE) loss from dense to sparse to train the extracted sparse descriptors. Experimental results show that the proposed network is both efficient and powerful in various visual measurement tasks, including image matching, 3D reconstruction, and visual relocalization.
Occupancy Planes for Single-view RGB-D Human Reconstruction
Aug 04, 2022
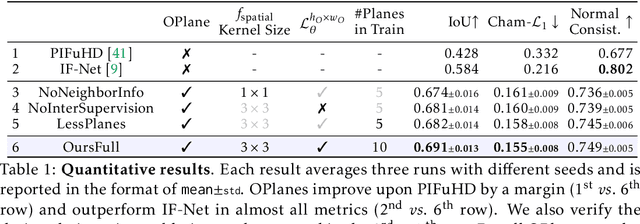
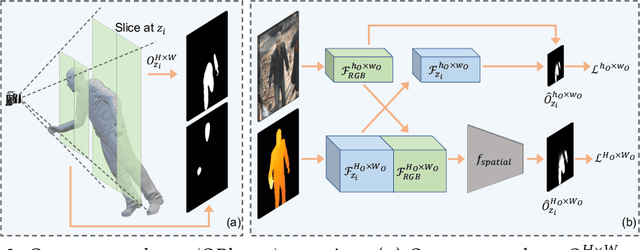
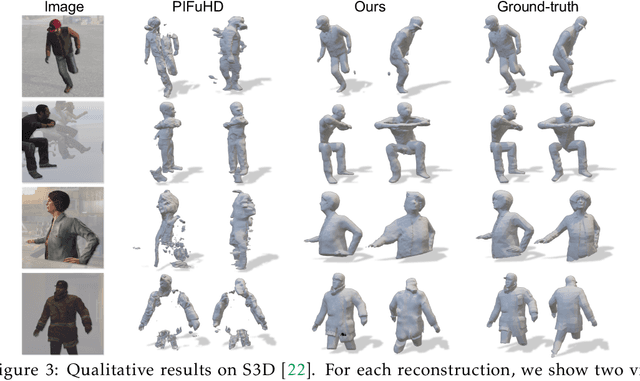
Single-view RGB-D human reconstruction with implicit functions is often formulated as per-point classification. Specifically, a set of 3D locations within the view-frustum of the camera are first projected independently onto the image and a corresponding feature is subsequently extracted for each 3D location. The feature of each 3D location is then used to classify independently whether the corresponding 3D point is inside or outside the observed object. This procedure leads to sub-optimal results because correlations between predictions for neighboring locations are only taken into account implicitly via the extracted features. For more accurate results we propose the occupancy planes (OPlanes) representation, which enables to formulate single-view RGB-D human reconstruction as occupancy prediction on planes which slice through the camera's view frustum. Such a representation provides more flexibility than voxel grids and enables to better leverage correlations than per-point classification. On the challenging S3D data we observe a simple classifier based on the OPlanes representation to yield compelling results, especially in difficult situations with partial occlusions due to other objects and partial visibility, which haven't been addressed by prior work.
Initialization and Alignment for Adversarial Texture Optimization
Jul 28, 2022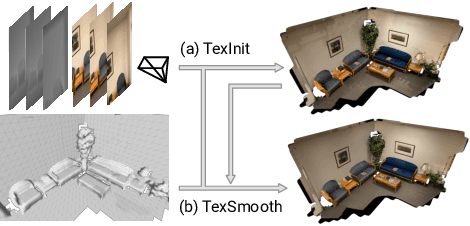
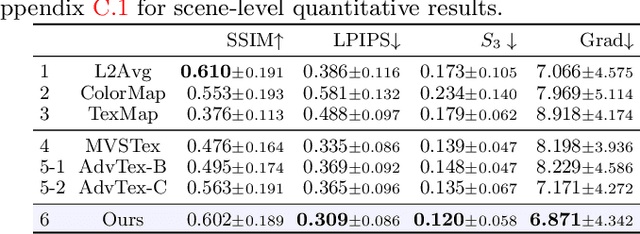

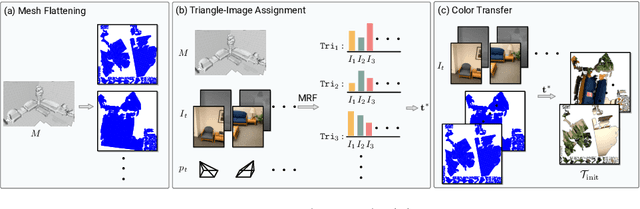
While recovery of geometry from image and video data has received a lot of attention in computer vision, methods to capture the texture for a given geometry are less mature. Specifically, classical methods for texture generation often assume clean geometry and reasonably well-aligned image data. While very recent methods, e.g., adversarial texture optimization, better handle lower-quality data obtained from hand-held devices, we find them to still struggle frequently. To improve robustness, particularly of recent adversarial texture optimization, we develop an explicit initialization and an alignment procedure. It deals with complex geometry due to a robust mapping of the geometry to the texture map and a hard-assignment-based initialization. It deals with misalignment of geometry and images by integrating fast image-alignment into the texture refinement optimization. We demonstrate efficacy of our texture generation on a dataset of 11 scenes with a total of 2807 frames, observing 7.8% and 11.1% relative improvements regarding perceptual and sharpness measurements.