 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Combination and Singular Spectrum Analysis Based Remote Photoplethysmography Pulse Extraction in Low-light Environments
Mar 04, 2025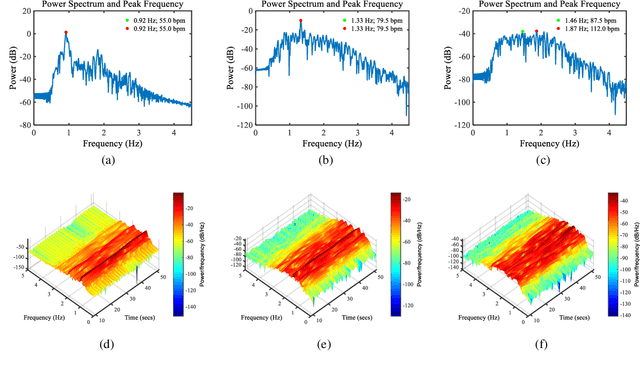
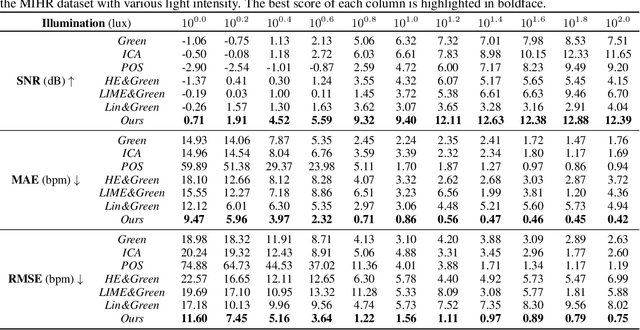
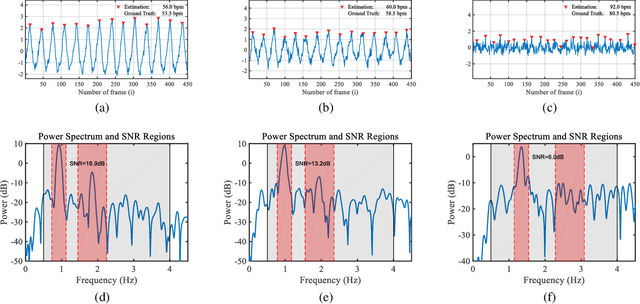
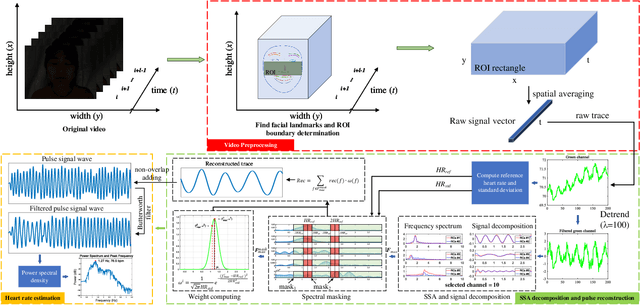
Camera-based vital signs monitoring in recent years has attracted more and more researchers and the results are promising. However, a few research works focus on heart rate extraction under extremely low illumination environments. In this paper, we propose a novel framework for remote heart rate estimation under low-light conditions. This method uses singular spectrum analysis (SSA) to decompose the filtered signal into several reconstructed components. A spectral masking algorithm is utilized to refine the preliminary candidate components on the basis of a reference heart rate. The contributive components are fused into the final pulse signal. To evaluate the performance of our framework in low-light conditions, the proposed approach is tested on a large-scale multi-illumination HR dataset (named MIHR). The test results verify that the proposed method has stronger robustness to low illumination than state-of-the-art methods, effectively improving the signal-to-noise ratio and heart rate estimation precision. We further perform experiments on the PUlse RatE detection (PURE) dataset which is recorded under normal light conditions to demonstrate the generalization of our method. The experiment results show that our method can stably detect pulse rate and achieve comparative results. The proposed method pioneers a new solution to the remote heart rate estimation in low-light conditions.
IEBins: Iterative Elastic Bins for Monocular Depth Estimation
Sep 25, 2023



Monocular depth estimation (MDE) is a fundamental topic of geometric computer vision and a core technique for many downstream applications. Recently, several methods reframe the MDE as a classification-regression problem where a linear combination of probabilistic distribution and bin centers is used to predict depth. In this paper, we propose a novel concept of iterative elastic bins (IEBins) for the classification-regression-based MDE. The proposed IEBins aims to search for high-quality depth by progressively optimizing the search range, which involves multiple stages and each stage performs a finer-grained depth search in the target bin on top of its previous stage. To alleviate the possible error accumulation during the iterative process, we utilize a novel elastic target bin to replace the original target bin, the width of which is adjusted elastically based on the depth uncertainty. Furthermore, we develop a dedicated framework composed of a feature extractor and an iterative optimizer that has powerful temporal context modeling capabilities benefiting from the GRU-based architecture. Extensive experiments on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets demonstrate that the proposed method surpasses prior state-of-the-art competitors. The source code is publicly available at https://github.com/ShuweiShao/IEBins.
NDDepth: Normal-Distance Assisted Monocular Depth Estimation
Sep 24, 2023



Monocular depth estimation has drawn widespread attention from the vision community due to its broad applications. In this paper, we propose a novel physics (geometry)-driven deep learning framework for monocular depth estimation by assuming that 3D scenes are constituted by piece-wise planes. Particularly, we introduce a new normal-distance head that outputs pixel-level surface normal and plane-to-origin distance for deriving depth at each position. Meanwhile, the normal and distance are regularized by a developed plane-aware consistency constraint. We further integrate an additional depth head to improve the robustness of the proposed framework. To fully exploit the strengths of these two heads, we develop an effective contrastive iterative refinement module that refines depth in a complementary manner according to the depth uncertainty. Extensive experiments indicate that the proposed method exceeds previous state-of-the-art competitors on the NYU-Depth-v2, KITTI and SUN RGB-D datasets. Notably, it ranks 1st among all submissions on the KITTI depth prediction online benchmark at the submission time.
Online Unsupervised Video Object Segmentation via Contrastive Motion Clustering
Jun 21, 2023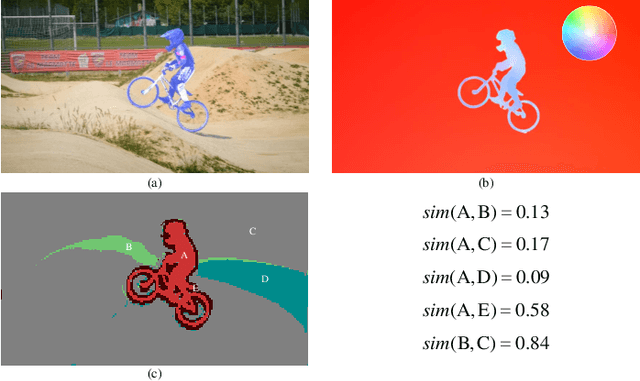
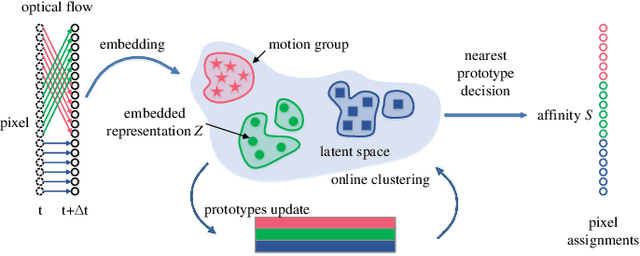
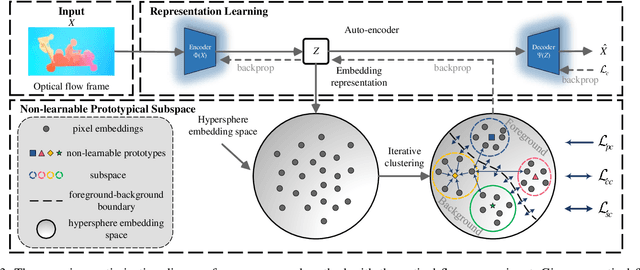
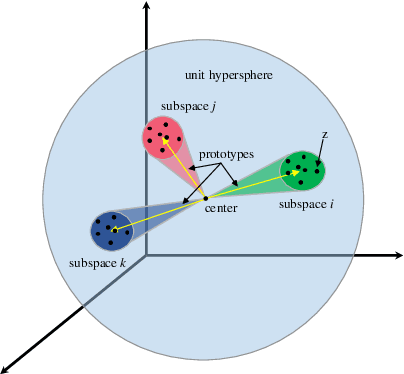
Online unsupervised video object segmentation (UVOS) uses the previous frames as its input to automatically separate the primary object(s) from a streaming video without using any further manual annotation. A major challenge is that the model has no access to the future and must rely solely on the history, i.e., the segmentation mask is predicted from the current frame as soon as it is captured. In this work, a novel contrastive motion clustering algorithm with an optical flow as its input is proposed for the online UVOS by exploiting the common fate principle that visual elements tend to be perceived as a group if they possess the same motion pattern. We build a simple and effective auto-encoder to iteratively summarize non-learnable prototypical bases for the motion pattern, while the bases in turn help learn the representation of the embedding network. Further, a contrastive learning strategy based on a boundary prior is developed to improve foreground and background feature discrimination in the representation learning stage. The proposed algorithm can be optimized on arbitrarily-scale data i.e., frame, clip, dataset) and performed in an online fashion. Experiments on $\textit{DAVIS}_{\textit{16}}$, $\textit{FBMS}$, and $\textit{SegTrackV2}$ datasets show that the accuracy of our method surpasses the previous state-of-the-art (SoTA) online UVOS method by a margin of 0.8%, 2.9%, and 1.1%, respectively. Furthermore, by using an online deep subspace clustering to tackle the motion grouping, our method is able to achieve higher accuracy at $3\times$ faster inference time compared to SoTA online UVOS method, and making a good trade-off between effectiveness and efficiency.
ALIKED: A Lighter Keypoint and Descriptor Extraction Network via Deformable Transformation
Apr 16, 2023



Image keypoints and descriptors play a crucial role in many visual measurement tasks. In recent years, deep neural networks have been widely used to improve the performance of keypoint and descriptor extraction. However, the conventional convolution operations do not provide the geometric invariance required for the descriptor. To address this issue, we propose the Sparse Deformable Descriptor Head (SDDH), which learns the deformable positions of supporting features for each keypoint and constructs deformable descriptors. Furthermore, SDDH extracts descriptors at sparse keypoints instead of a dense descriptor map, which enables efficient extraction of descriptors with strong expressiveness. In addition, we relax the neural reprojection error (NRE) loss from dense to sparse to train the extracted sparse descriptors. Experimental results show that the proposed network is both efficient and powerful in various visual measurement tasks, including image matching, 3D reconstruction, and visual relocalization.
Image Enhancement for Remote Photoplethysmography in a Low-Light Environment
Mar 16, 2023


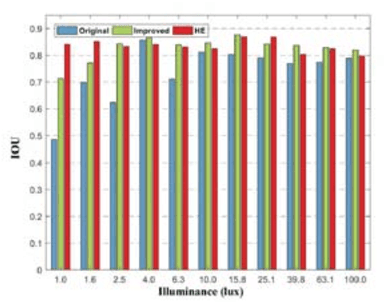
With the improvement of sensor technology and significant algorithmic advances, the accuracy of remote heart rate monitoring technology has been significantly improved. Despite of the significant algorithmic advances, the performance of rPPG algorithm can degrade in the long-term, high-intensity continuous work occurred in evenings or insufficient light environments. One of the main challenges is that the lost facial details and low contrast cause the failure of detection and tracking. Also, insufficient lighting in video capturing hurts the quality of physiological signal. In this paper, we collect a large-scale dataset that was designed for remote heart rate estimation recorded with various illumination variations to evaluate the performance of the rPPG algorithm (Green, ICA, and POS). We also propose a low-light enhancement solution (technical solution) for remote heart rate estimation under the low-light condition. Using collected dataset, we found 1) face detection algorithm cannot detect faces in video captured in low light conditions; 2) A decrease in the amplitude of the pulsatile signal will lead to the noise signal to be in the dominant position; and 3) the chrominance-based method suffers from the limitation in the assumption about skin-tone will not hold, and Green and ICA method receive less influence than POS in dark illuminance environment. The proposed solution for rPPG process is effective to detect and improve the signal-to-noise ratio and precision of the pulsatile signal.
Self-Supervised Monocular Depth Estimation with Self-Reference Distillation and Disparity Offset Refinement
Feb 20, 2023

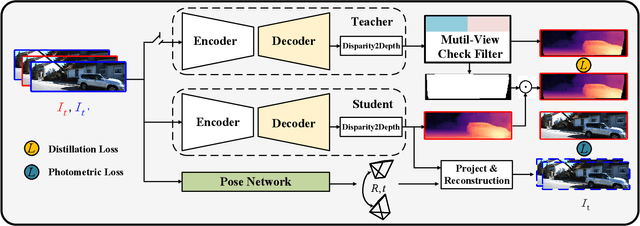
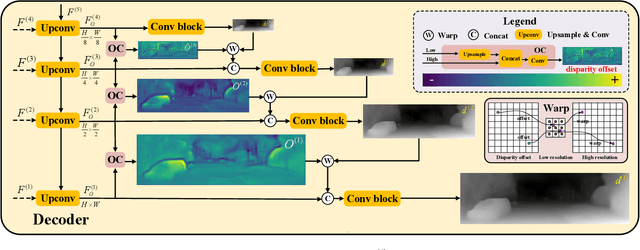
Monocular depth estimation plays a fundamental role in computer vision. Due to the costly acquisition of depth ground truth, self-supervised methods that leverage adjacent frames to establish a supervisory signal have emerged as the most promising paradigms. In this work, we propose two novel ideas to improve self-supervised monocular depth estimation: 1) self-reference distillation and 2) disparity offset refinement. Specifically, we use a parameter-optimized model as the teacher updated as the training epochs to provide additional supervision during the training process. The teacher model has the same structure as the student model, with weights inherited from the historical student model. In addition, a multiview check is introduced to filter out the outliers produced by the teacher model. Furthermore, we leverage the contextual consistency between high-scale and low-scale features to obtain multiscale disparity offsets, which are used to refine the disparity output incrementally by aligning disparity information at different scales. The experimental results on the KITTI and Make3D datasets show that our method outperforms previous state-of-the-art competitors.
Real-time Local Feature with Global Visual Information Enhancement
Nov 20, 2022



Local feature provides compact and invariant image representation for various visual tasks. Current deep learning-based local feature algorithms always utilize convolution neural network (CNN) architecture with limited receptive field. Besides, even with high-performance GPU devices, the computational efficiency of local features cannot be satisfactory. In this paper, we tackle such problems by proposing a CNN-based local feature algorithm. The proposed method introduces a global enhancement module to fuse global visual clues in a light-weight network, and then optimizes the network by novel deep reinforcement learning scheme from the perspective of local feature matching task. Experiments on the public benchmarks demonstrate that the proposal can achieve considerable robustness against visual interference and meanwhile run in real time.
SMUDLP: Self-Teaching Multi-Frame Unsupervised Endoscopic Depth Estimation with Learnable Patchmatch
May 30, 2022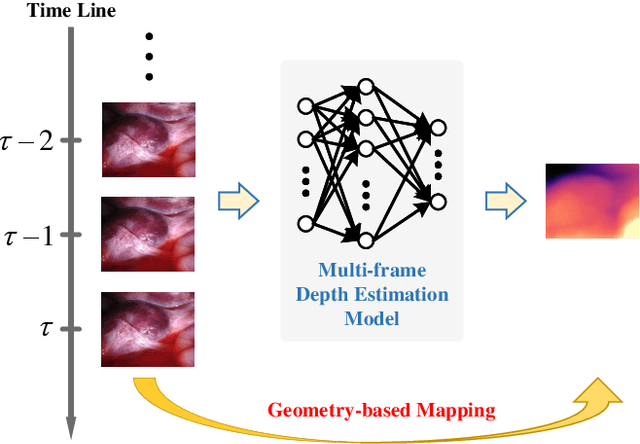
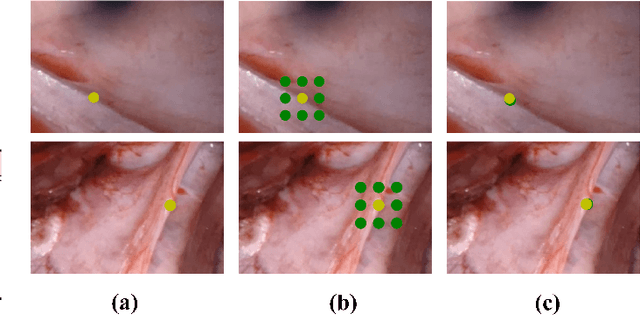


Unsupervised monocular trained depth estimation models make use of adjacent frames as a supervisory signal during the training phase. However, temporally correlated frames are also available at inference time for many clinical applications, e.g., surgical navigation. The vast majority of monocular systems do not exploit this valuable signal that could be deployed to enhance the depth estimates. Those that do, achieve only limited gains due to the unique challenges in endoscopic scenes, such as low and homogeneous textures and inter-frame brightness fluctuations. In this work, we present SMUDLP, a novel and unsupervised paradigm for multi-frame monocular endoscopic depth estimation. The SMUDLP integrates a learnable patchmatch module to adaptively increase the discriminative ability in low-texture and homogeneous-texture regions, and enforces cross-teaching and self-teaching consistencies to provide efficacious regularizations towards brightness fluctuations. Our detailed experiments on both SCARED and Hamlyn datasets indicate that the SMUDLP exceeds state-of-the-art competitors by a large margin, including those that use single or multiple frames at inference time. The source code and trained models will be publicly available upon the acceptance.
Implicit Motion-Compensated Network for Unsupervised Video Object Segmentation
Apr 06, 2022



Unsupervised video object segmentation (UVOS) aims at automatically separating the primary foreground object(s) from the background in a video sequence. Existing UVOS methods either lack robustness when there are visually similar surroundings (appearance-based) or suffer from deterioration in the quality of their predictions because of dynamic background and inaccurate flow (flow-based). To overcome the limitations, we propose an implicit motion-compensated network (IMCNet) combining complementary cues ($\textit{i.e.}$, appearance and motion) with aligned motion information from the adjacent frames to the current frame at the feature level without estimating optical flows. The proposed IMCNet consists of an affinity computing module (ACM), an attention propagation module (APM), and a motion compensation module (MCM). The light-weight ACM extracts commonality between neighboring input frames based on appearance features. The APM then transmits global correlation in a top-down manner. Through coarse-to-fine iterative inspiring, the APM will refine object regions from multiple resolutions so as to efficiently avoid losing details. Finally, the MCM aligns motion information from temporally adjacent frames to the current frame which achieves implicit motion compensation at the feature level. We perform extensive experiments on $\textit{DAVIS}_{\textit{16}}$ and $\textit{YouTube-Objects}$. Our network achieves favorable performance while running at a faster speed compared to the state-of-the-art methods.