 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNDDepth: Normal-Distance Assisted Monocular Depth Estimation and Completion
Nov 13, 2023


Over the past few years, monocular depth estimation and completion have been paid more and more attention from the computer vision community because of their widespread applications. In this paper, we introduce novel physics (geometry)-driven deep learning frameworks for these two tasks by assuming that 3D scenes are constituted with piece-wise planes. Instead of directly estimating the depth map or completing the sparse depth map, we propose to estimate the surface normal and plane-to-origin distance maps or complete the sparse surface normal and distance maps as intermediate outputs. To this end, we develop a normal-distance head that outputs pixel-level surface normal and distance. Meanwhile, the surface normal and distance maps are regularized by a developed plane-aware consistency constraint, which are then transformed into depth maps. Furthermore, we integrate an additional depth head to strengthen the robustness of the proposed frameworks. Extensive experiments on the NYU-Depth-v2, KITTI and SUN RGB-D datasets demonstrate that our method exceeds in performance prior state-of-the-art monocular depth estimation and completion competitors. The source code will be available at https://github.com/ShuweiShao/NDDepth.
MonoDiffusion: Self-Supervised Monocular Depth Estimation Using Diffusion Model
Nov 13, 2023



Over the past few years, self-supervised monocular depth estimation that does not depend on ground-truth during the training phase has received widespread attention. Most efforts focus on designing different types of network architectures and loss functions or handling edge cases, e.g., occlusion and dynamic objects. In this work, we introduce a novel self-supervised depth estimation framework, dubbed MonoDiffusion, by formulating it as an iterative denoising process. Because the depth ground-truth is unavailable in the training phase, we develop a pseudo ground-truth diffusion process to assist the diffusion in MonoDiffusion. The pseudo ground-truth diffusion gradually adds noise to the depth map generated by a pre-trained teacher model. Moreover,the teacher model allows applying a distillation loss to guide the denoised depth. Further, we develop a masked visual condition mechanism to enhance the denoising ability of model. Extensive experiments are conducted on the KITTI and Make3D datasets and the proposed MonoDiffusion outperforms prior state-of-the-art competitors. The source code will be available at https://github.com/ShuweiShao/MonoDiffusion.
ALIKED: A Lighter Keypoint and Descriptor Extraction Network via Deformable Transformation
Apr 16, 2023



Image keypoints and descriptors play a crucial role in many visual measurement tasks. In recent years, deep neural networks have been widely used to improve the performance of keypoint and descriptor extraction. However, the conventional convolution operations do not provide the geometric invariance required for the descriptor. To address this issue, we propose the Sparse Deformable Descriptor Head (SDDH), which learns the deformable positions of supporting features for each keypoint and constructs deformable descriptors. Furthermore, SDDH extracts descriptors at sparse keypoints instead of a dense descriptor map, which enables efficient extraction of descriptors with strong expressiveness. In addition, we relax the neural reprojection error (NRE) loss from dense to sparse to train the extracted sparse descriptors. Experimental results show that the proposed network is both efficient and powerful in various visual measurement tasks, including image matching, 3D reconstruction, and visual relocalization.
Constrained Exploration in Reinforcement Learning with Optimality Preservation
Apr 05, 2023



We consider a class of reinforcement-learning systems in which the agent follows a behavior policy to explore a discrete state-action space to find an optimal policy while adhering to some restriction on its behavior. Such restriction may prevent the agent from visiting some state-action pairs, possibly leading to the agent finding only a sub-optimal policy. To address this problem we introduce the concept of constrained exploration with optimality preservation, whereby the exploration behavior of the agent is constrained to meet a specification while the optimality of the (original) unconstrained learning process is preserved. We first establish a feedback-control structure that models the dynamics of the unconstrained learning process. We then extend this structure by adding a supervisor to ensure that the behavior of the agent meets the specification, and establish (for a class of reinforcement-learning problems with a known deterministic environment) a necessary and sufficient condition under which optimality is preserved. This work demonstrates the utility and the prospect of studying reinforcement-learning problems in the context of the theories of discrete-event systems, automata and formal languages.
Sparse LiDAR Assisted Self-supervised Stereo Disparity Estimation
Dec 31, 2021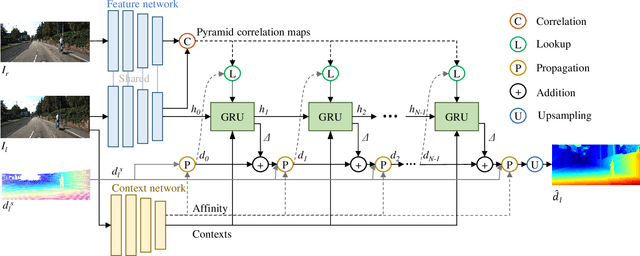
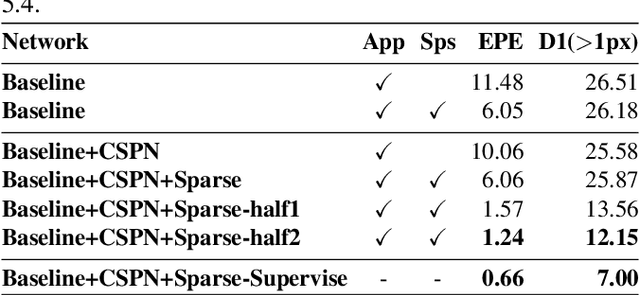
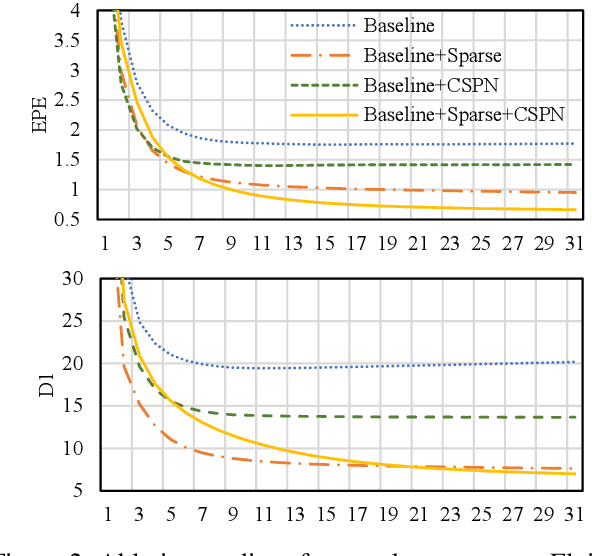
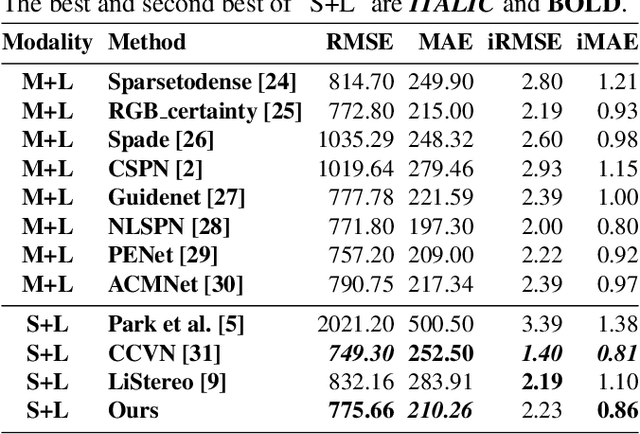
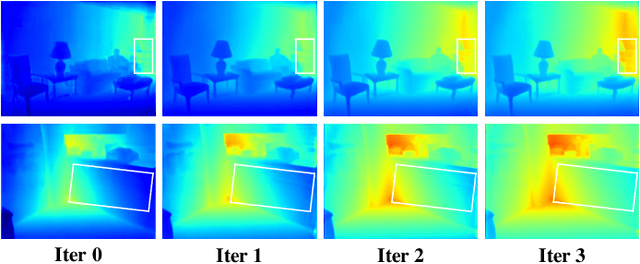
Deep stereo matching has made significant progress in recent years. However, state-of-the-art methods are based on expensive 4D cost volume, which limits their use in real-world applications. To address this issue, 3D correlation maps and iterative disparity updates have been proposed. Regarding that in real-world platforms, such as self-driving cars and robots, the Lidar is usually installed. Thus we further introduce the sparse Lidar point into the iterative updates, which alleviates the burden of network updating the disparity from zero states. Furthermore, we propose training the network in a self-supervised way so that it can be trained on any captured data for better generalization ability. Experiments and comparisons show that the presented method is effective and achieves comparable results with related methods.
ALIKE: Accurate and Lightweight Keypoint Detection and Descriptor Extraction
Dec 06, 2021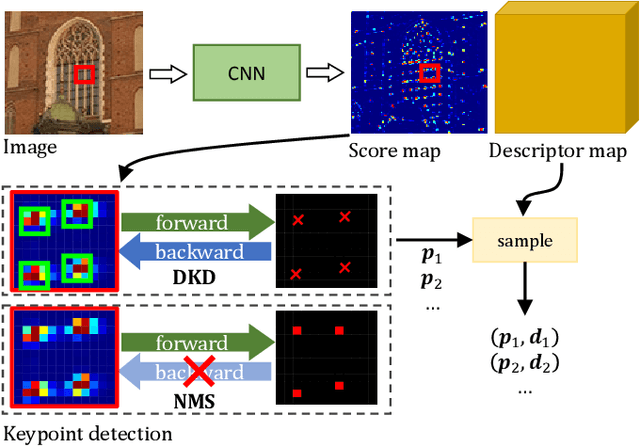
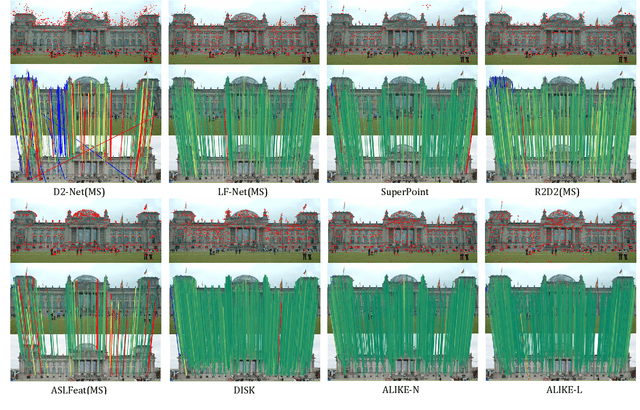
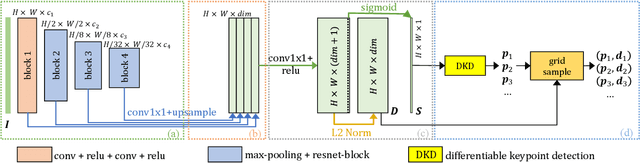
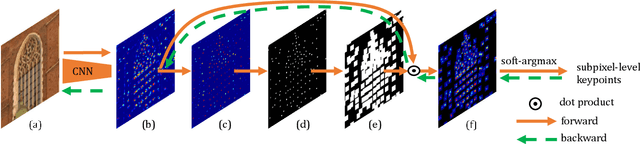
Existing methods detect the keypoints in a non-differentiable way, therefore they can not directly optimize the position of keypoints through back-propagation. To address this issue, we present a differentiable keypoint detection module, which outputs accurate sub-pixel keypoints. The reprojection loss is then proposed to directly optimize these sub-pixel keypoints, and the dispersity peak loss is presented for accurate keypoints regularization. We also extract the descriptors in a sub-pixel way, and they are trained with the stable neural reprojection error loss. Moreover, a lightweight network is designed for keypoint detection and descriptor extraction, which can run at 95 frames per second for 640x480 images on a commercial GPU. On homography estimation, camera pose estimation, and visual (re-)localization tasks, the proposed method achieves equivalent performance with the state-of-the-art approaches, while greatly reduces the inference time.