 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDAL: Temporally Interleaved Diffusion and Action Loop for High-Frequency VLA Control
Jan 21, 2026Large-scale Vision-Language-Action (VLA) models offer semantic generalization but suffer from high inference latency, limiting them to low-frequency batch-and-execute paradigm. This frequency mismatch creates an execution blind spot, causing failures in dynamic environments where targets move during the open-loop execution window. We propose TIDAL (Temporally Interleaved Diffusion and Action Loop), a hierarchical framework that decouples semantic reasoning from high-frequency actuation. TIDAL operates as a backbone-agnostic module for diffusion-based VLAs, using a dual-frequency architecture to redistribute the computational budget. Specifically, a low-frequency macro-intent loop caches semantic embeddings, while a high-frequency micro-control loop interleaves single-step flow integration with execution. This design enables approximately 9 Hz control updates on edge hardware (vs. approximately 2.4 Hz baselines) without increasing marginal overhead. To handle the resulting latency shift, we introduce a temporally misaligned training strategy where the policy learns predictive compensation using stale semantic intent alongside real-time proprioception. Additionally, we address the insensitivity of static vision encoders to velocity by incorporating a differential motion predictor. TIDAL is architectural, making it orthogonal to system-level optimizations. Experiments show a 2x performance gain over open-loop baselines in dynamic interception tasks. Despite a marginal regression in static success rates, our approach yields a 4x increase in feedback frequency and extends the effective horizon of semantic embeddings beyond the native action chunk size. Under non-paused inference protocols, TIDAL remains robust where standard baselines fail due to latency.
Neural Augmentation Based Panoramic High Dynamic Range Stitching
Sep 07, 2024



Due to saturated regions of inputting low dynamic range (LDR) images and large intensity changes among the LDR images caused by different exposures, it is challenging to produce an information enriched panoramic LDR image without visual artifacts for a high dynamic range (HDR) scene through stitching multiple geometrically synchronized LDR images with different exposures and pairwise overlapping fields of views (OFOVs). Fortunately, the stitching of such images is innately a perfect scenario for the fusion of a physics-driven approach and a data-driven approach due to their OFOVs. Based on this new insight, a novel neural augmentation based panoramic HDR stitching algorithm is proposed in this paper. The physics-driven approach is built up using the OFOVs. Different exposed images of each view are initially generated by using the physics-driven approach, are then refined by a data-driven approach, and are finally used to produce panoramic LDR images with different exposures. All the panoramic LDR images with different exposures are combined together via a multi-scale exposure fusion algorithm to produce the final panoramic LDR image. Experimental results demonstrate the proposed algorithm outperforms existing panoramic stitching algorithms.
Large Language Models as Automated Aligners for benchmarking Vision-Language Models
Nov 24, 2023



With the advancements in Large Language Models (LLMs), Vision-Language Models (VLMs) have reached a new level of sophistication, showing notable competence in executing intricate cognition and reasoning tasks. However, existing evaluation benchmarks, primarily relying on rigid, hand-crafted datasets to measure task-specific performance, face significant limitations in assessing the alignment of these increasingly anthropomorphic models with human intelligence. In this work, we address the limitations via Auto-Bench, which delves into exploring LLMs as proficient aligners, measuring the alignment between VLMs and human intelligence and value through automatic data curation and assessment. Specifically, for data curation, Auto-Bench utilizes LLMs (e.g., GPT-4) to automatically generate a vast set of question-answer-reasoning triplets via prompting on visual symbolic representations (e.g., captions, object locations, instance relationships, and etc.). The curated data closely matches human intent, owing to the extensive world knowledge embedded in LLMs. Through this pipeline, a total of 28.5K human-verified and 3,504K unfiltered question-answer-reasoning triplets have been curated, covering 4 primary abilities and 16 sub-abilities. We subsequently engage LLMs like GPT-3.5 to serve as judges, implementing the quantitative and qualitative automated assessments to facilitate a comprehensive evaluation of VLMs. Our validation results reveal that LLMs are proficient in both evaluation data curation and model assessment, achieving an average agreement rate of 85%. We envision Auto-Bench as a flexible, scalable, and comprehensive benchmark for evaluating the evolving sophisticated VLMs.
NDDepth: Normal-Distance Assisted Monocular Depth Estimation and Completion
Nov 13, 2023
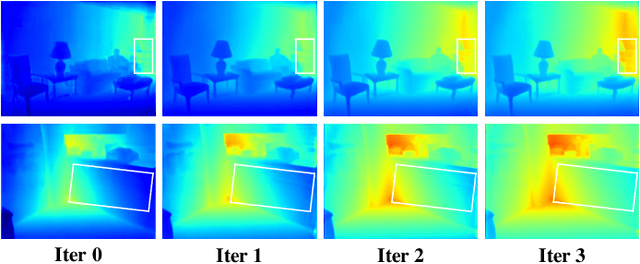


Over the past few years, monocular depth estimation and completion have been paid more and more attention from the computer vision community because of their widespread applications. In this paper, we introduce novel physics (geometry)-driven deep learning frameworks for these two tasks by assuming that 3D scenes are constituted with piece-wise planes. Instead of directly estimating the depth map or completing the sparse depth map, we propose to estimate the surface normal and plane-to-origin distance maps or complete the sparse surface normal and distance maps as intermediate outputs. To this end, we develop a normal-distance head that outputs pixel-level surface normal and distance. Meanwhile, the surface normal and distance maps are regularized by a developed plane-aware consistency constraint, which are then transformed into depth maps. Furthermore, we integrate an additional depth head to strengthen the robustness of the proposed frameworks. Extensive experiments on the NYU-Depth-v2, KITTI and SUN RGB-D datasets demonstrate that our method exceeds in performance prior state-of-the-art monocular depth estimation and completion competitors. The source code will be available at https://github.com/ShuweiShao/NDDepth.
MonoDiffusion: Self-Supervised Monocular Depth Estimation Using Diffusion Model
Nov 13, 2023



Over the past few years, self-supervised monocular depth estimation that does not depend on ground-truth during the training phase has received widespread attention. Most efforts focus on designing different types of network architectures and loss functions or handling edge cases, e.g., occlusion and dynamic objects. In this work, we introduce a novel self-supervised depth estimation framework, dubbed MonoDiffusion, by formulating it as an iterative denoising process. Because the depth ground-truth is unavailable in the training phase, we develop a pseudo ground-truth diffusion process to assist the diffusion in MonoDiffusion. The pseudo ground-truth diffusion gradually adds noise to the depth map generated by a pre-trained teacher model. Moreover,the teacher model allows applying a distillation loss to guide the denoised depth. Further, we develop a masked visual condition mechanism to enhance the denoising ability of model. Extensive experiments are conducted on the KITTI and Make3D datasets and the proposed MonoDiffusion outperforms prior state-of-the-art competitors. The source code will be available at https://github.com/ShuweiShao/MonoDiffusion.
IEBins: Iterative Elastic Bins for Monocular Depth Estimation
Sep 25, 2023



Monocular depth estimation (MDE) is a fundamental topic of geometric computer vision and a core technique for many downstream applications. Recently, several methods reframe the MDE as a classification-regression problem where a linear combination of probabilistic distribution and bin centers is used to predict depth. In this paper, we propose a novel concept of iterative elastic bins (IEBins) for the classification-regression-based MDE. The proposed IEBins aims to search for high-quality depth by progressively optimizing the search range, which involves multiple stages and each stage performs a finer-grained depth search in the target bin on top of its previous stage. To alleviate the possible error accumulation during the iterative process, we utilize a novel elastic target bin to replace the original target bin, the width of which is adjusted elastically based on the depth uncertainty. Furthermore, we develop a dedicated framework composed of a feature extractor and an iterative optimizer that has powerful temporal context modeling capabilities benefiting from the GRU-based architecture. Extensive experiments on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets demonstrate that the proposed method surpasses prior state-of-the-art competitors. The source code is publicly available at https://github.com/ShuweiShao/IEBins.
NDDepth: Normal-Distance Assisted Monocular Depth Estimation
Sep 24, 2023



Monocular depth estimation has drawn widespread attention from the vision community due to its broad applications. In this paper, we propose a novel physics (geometry)-driven deep learning framework for monocular depth estimation by assuming that 3D scenes are constituted by piece-wise planes. Particularly, we introduce a new normal-distance head that outputs pixel-level surface normal and plane-to-origin distance for deriving depth at each position. Meanwhile, the normal and distance are regularized by a developed plane-aware consistency constraint. We further integrate an additional depth head to improve the robustness of the proposed framework. To fully exploit the strengths of these two heads, we develop an effective contrastive iterative refinement module that refines depth in a complementary manner according to the depth uncertainty. Extensive experiments indicate that the proposed method exceeds previous state-of-the-art competitors on the NYU-Depth-v2, KITTI and SUN RGB-D datasets. Notably, it ranks 1st among all submissions on the KITTI depth prediction online benchmark at the submission time.
Vision-Based Traffic Accident Detection and Anticipation: A Survey
Aug 30, 2023



Traffic accident detection and anticipation is an obstinate road safety problem and painstaking efforts have been devoted. With the rapid growth of video data, Vision-based Traffic Accident Detection and Anticipation (named Vision-TAD and Vision-TAA) become the last one-mile problem for safe driving and surveillance safety. However, the long-tailed, unbalanced, highly dynamic, complex, and uncertain properties of traffic accidents form the Out-of-Distribution (OOD) feature for Vision-TAD and Vision-TAA. Current AI development may focus on these OOD but important problems. What has been done for Vision-TAD and Vision-TAA? What direction we should focus on in the future for this problem? A comprehensive survey is important. We present the first survey on Vision-TAD in the deep learning era and the first-ever survey for Vision-TAA. The pros and cons of each research prototype are discussed in detail during the investigation. In addition, we also provide a critical review of 31 publicly available benchmarks and related evaluation metrics. Through this survey, we want to spawn new insights and open possible trends for Vision-TAD and Vision-TAA tasks.
Unlimited Knowledge Distillation for Action Recognition in the Dark
Aug 18, 2023Dark videos often lose essential information, which causes the knowledge learned by networks is not enough to accurately recognize actions. Existing knowledge assembling methods require massive GPU memory to distill the knowledge from multiple teacher models into a student model. In action recognition, this drawback becomes serious due to much computation required by video process. Constrained by limited computation source, these approaches are infeasible. To address this issue, we propose an unlimited knowledge distillation (UKD) in this paper. Compared with existing knowledge assembling methods, our UKD can effectively assemble different knowledge without introducing high GPU memory consumption. Thus, the number of teaching models for distillation is unlimited. With our UKD, the network's learned knowledge can be remarkably enriched. Our experiments show that the single stream network distilled with our UKD even surpasses a two-stream network. Extensive experiments are conducted on the ARID dataset.
Online Unsupervised Video Object Segmentation via Contrastive Motion Clustering
Jun 21, 2023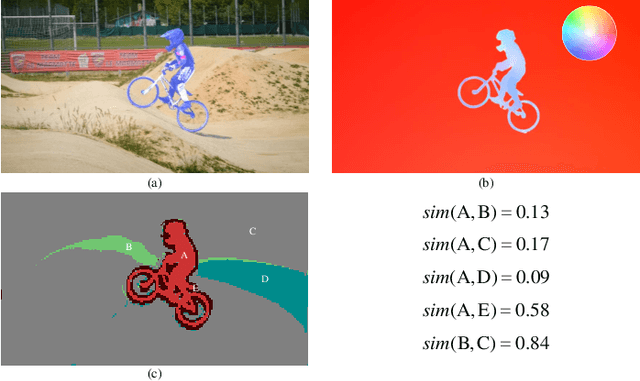
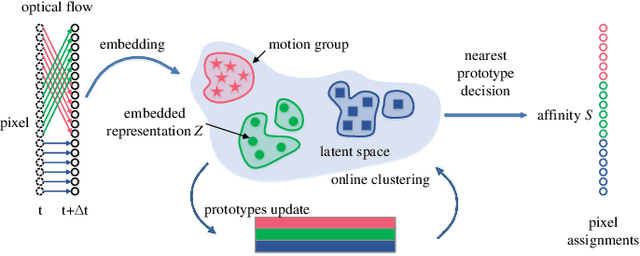
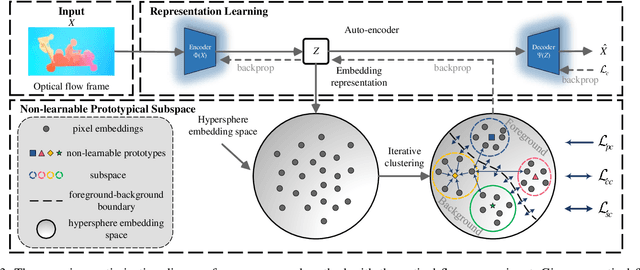
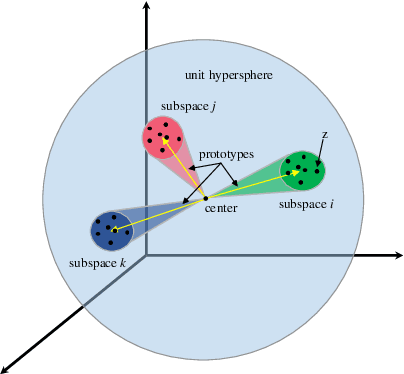
Online unsupervised video object segmentation (UVOS) uses the previous frames as its input to automatically separate the primary object(s) from a streaming video without using any further manual annotation. A major challenge is that the model has no access to the future and must rely solely on the history, i.e., the segmentation mask is predicted from the current frame as soon as it is captured. In this work, a novel contrastive motion clustering algorithm with an optical flow as its input is proposed for the online UVOS by exploiting the common fate principle that visual elements tend to be perceived as a group if they possess the same motion pattern. We build a simple and effective auto-encoder to iteratively summarize non-learnable prototypical bases for the motion pattern, while the bases in turn help learn the representation of the embedding network. Further, a contrastive learning strategy based on a boundary prior is developed to improve foreground and background feature discrimination in the representation learning stage. The proposed algorithm can be optimized on arbitrarily-scale data i.e., frame, clip, dataset) and performed in an online fashion. Experiments on $\textit{DAVIS}_{\textit{16}}$, $\textit{FBMS}$, and $\textit{SegTrackV2}$ datasets show that the accuracy of our method surpasses the previous state-of-the-art (SoTA) online UVOS method by a margin of 0.8%, 2.9%, and 1.1%, respectively. Furthermore, by using an online deep subspace clustering to tackle the motion grouping, our method is able to achieve higher accuracy at $3\times$ faster inference time compared to SoTA online UVOS method, and making a good trade-off between effectiveness and efficiency.