 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human-Oriented Cooperative Driving Approach: Integrating Driving Intention, State, and Conflict
Dec 29, 2025Human-vehicle cooperative driving serves as a vital bridge to fully autonomous driving by improving driving flexibility and gradually building driver trust and acceptance of autonomous technology. To establish more natural and effective human-vehicle interaction, we propose a Human-Oriented Cooperative Driving (HOCD) approach that primarily minimizes human-machine conflict by prioritizing driver intention and state. In implementation, we take both tactical and operational levels into account to ensure seamless human-vehicle cooperation. At the tactical level, we design an intention-aware trajectory planning method, using intention consistency cost as the core metric to evaluate the trajectory and align it with driver intention. At the operational level, we develop a control authority allocation strategy based on reinforcement learning, optimizing the policy through a designed reward function to achieve consistency between driver state and authority allocation. The results of simulation and human-in-the-loop experiments demonstrate that our proposed approach not only aligns with driver intention in trajectory planning but also ensures a reasonable authority allocation. Compared to other cooperative driving approaches, the proposed HOCD approach significantly enhances driving performance and mitigates human-machine conflict.The code is available at https://github.com/i-Qin/HOCD.
COVLM-RL: Critical Object-Oriented Reasoning for Autonomous Driving Using VLM-Guided Reinforcement Learning
Dec 10, 2025End-to-end autonomous driving frameworks face persistent challenges in generalization, training efficiency, and interpretability. While recent methods leverage Vision-Language Models (VLMs) through supervised learning on large-scale datasets to improve reasoning, they often lack robustness in novel scenarios. Conversely, reinforcement learning (RL)-based approaches enhance adaptability but remain data-inefficient and lack transparent decision-making. % contribution To address these limitations, we propose COVLM-RL, a novel end-to-end driving framework that integrates Critical Object-oriented (CO) reasoning with VLM-guided RL. Specifically, we design a Chain-of-Thought (CoT) prompting strategy that enables the VLM to reason over critical traffic elements and generate high-level semantic decisions, effectively transforming multi-view visual inputs into structured semantic decision priors. These priors reduce the input dimensionality and inject task-relevant knowledge into the RL loop, accelerating training and improving policy interpretability. However, bridging high-level semantic guidance with continuous low-level control remains non-trivial. To this end, we introduce a consistency loss that encourages alignment between the VLM's semantic plans and the RL agent's control outputs, enhancing interpretability and training stability. Experiments conducted in the CARLA simulator demonstrate that COVLM-RL significantly improves the success rate by 30\% in trained driving environments and by 50\% in previously unseen environments, highlighting its strong generalization capability.
V2X-DG: Domain Generalization for Vehicle-to-Everything Cooperative Perception
Mar 19, 2025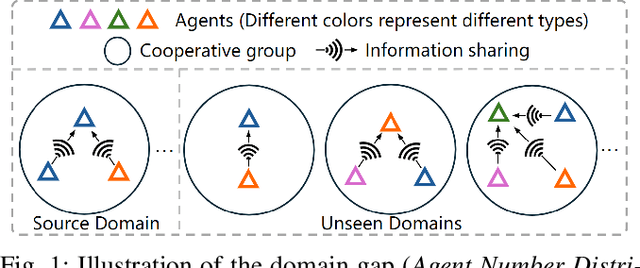
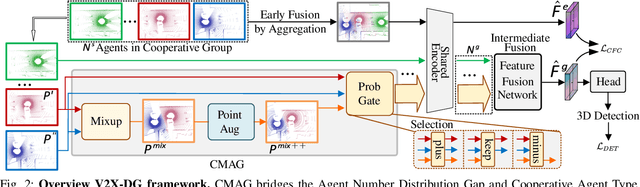
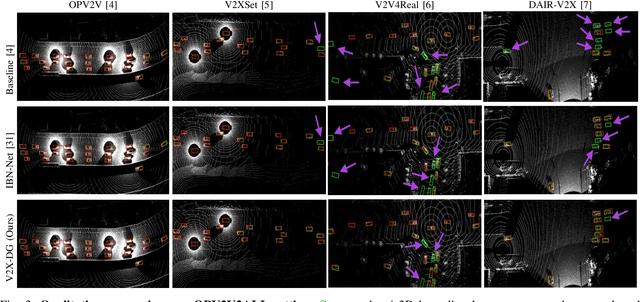

LiDAR-based Vehicle-to-Everything (V2X) cooperative perception has demonstrated its impact on the safety and effectiveness of autonomous driving. Since current cooperative perception algorithms are trained and tested on the same dataset, the generalization ability of cooperative perception systems remains underexplored. This paper is the first work to study the Domain Generalization problem of LiDAR-based V2X cooperative perception (V2X-DG) for 3D detection based on four widely-used open source datasets: OPV2V, V2XSet, V2V4Real and DAIR-V2X. Our research seeks to sustain high performance not only within the source domain but also across other unseen domains, achieved solely through training on source domain. To this end, we propose Cooperative Mixup Augmentation based Generalization (CMAG) to improve the model generalization capability by simulating the unseen cooperation, which is designed compactly for the domain gaps in cooperative perception. Furthermore, we propose a constraint for the regularization of the robust generalized feature representation learning: Cooperation Feature Consistency (CFC), which aligns the intermediately fused features of the generalized cooperation by CMAG and the early fused features of the original cooperation in source domain. Extensive experiments demonstrate that our approach achieves significant performance gains when generalizing to other unseen datasets while it also maintains strong performance on the source dataset.
Accelerate 3D Object Detection Models via Zero-Shot Attention Key Pruning
Mar 11, 2025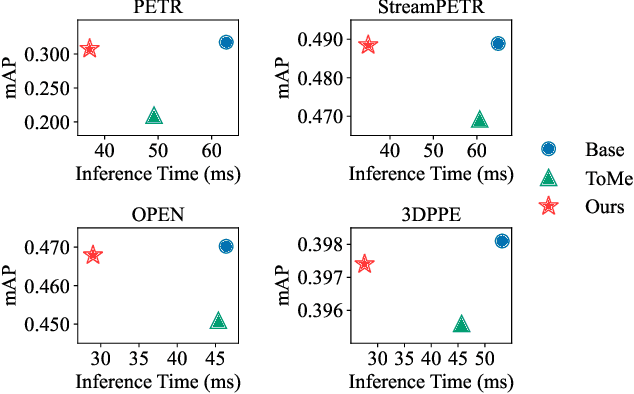
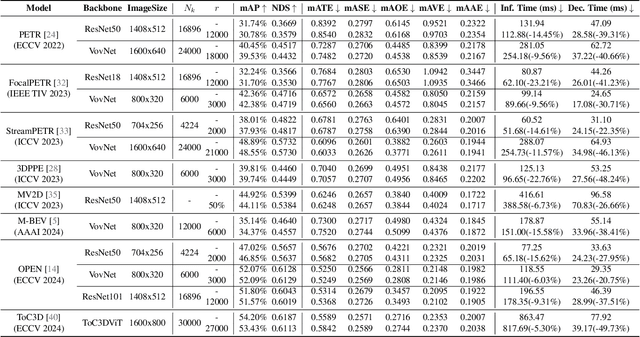
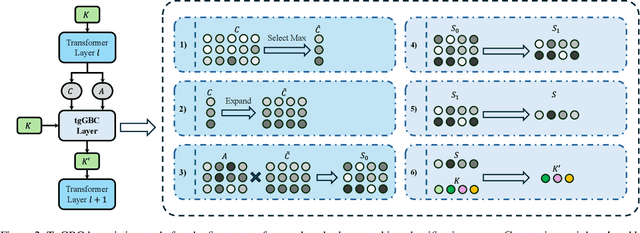
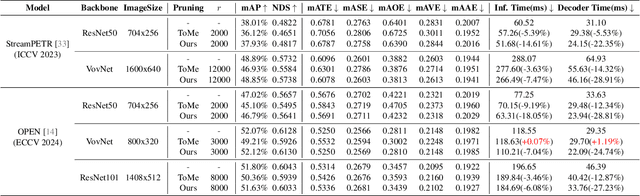
Query-based methods with dense features have demonstrated remarkable success in 3D object detection tasks. However, the computational demands of these models, particularly with large image sizes and multiple transformer layers, pose significant challenges for efficient running on edge devices. Existing pruning and distillation methods either need retraining or are designed for ViT models, which are hard to migrate to 3D detectors. To address this issue, we propose a zero-shot runtime pruning method for transformer decoders in 3D object detection models. The method, termed tgGBC (trim keys gradually Guided By Classification scores), systematically trims keys in transformer modules based on their importance. We expand the classification score to multiply it with the attention map to get the importance score of each key and then prune certain keys after each transformer layer according to their importance scores. Our method achieves a 1.99x speedup in the transformer decoder of the latest ToC3D model, with only a minimal performance loss of less than 1%. Interestingly, for certain models, our method even enhances their performance. Moreover, we deploy 3D detectors with tgGBC on an edge device, further validating the effectiveness of our method. The code can be found at https://github.com/iseri27/tg_gbc.
IC-Mapper: Instance-Centric Spatio-Temporal Modeling for Online Vectorized Map Construction
Mar 05, 2025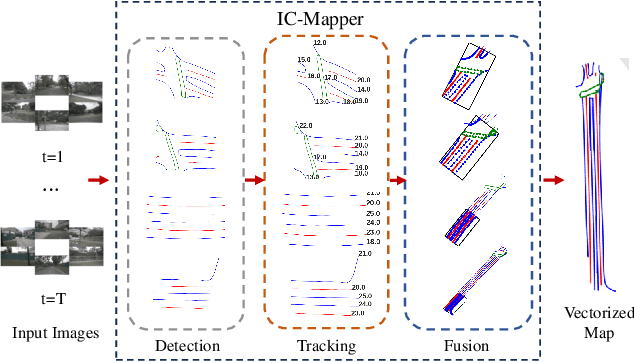
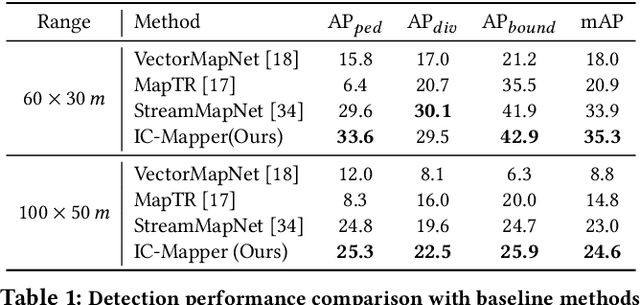

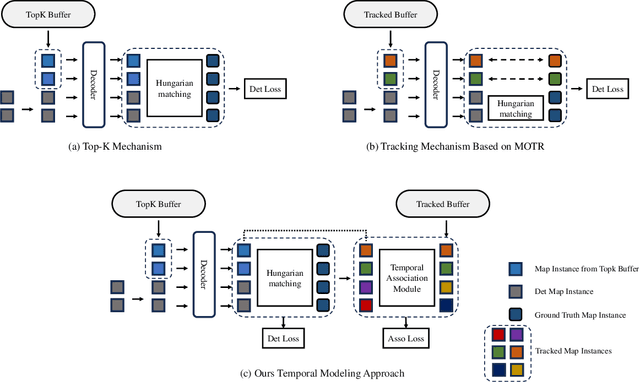
Online vector map construction based on visual data can bypass the processes of data collection, post-processing, and manual annotation required by traditional map construction, which significantly enhances map-building efficiency. However, existing work treats the online mapping task as a local range perception task, overlooking the spatial scalability required for map construction. We propose IC-Mapper, an instance-centric online mapping framework, which comprises two primary components: 1) Instance-centric temporal association module: For the detection queries of adjacent frames, we measure them in both feature and geometric dimensions to obtain the matching correspondence between instances across frames. 2) Instance-centric spatial fusion module: We perform point sampling on the historical global map from a spatial dimension and integrate it with the detection results of instances corresponding to the current frame to achieve real-time expansion and update of the map. Based on the nuScenes dataset, we evaluate our approach on detection, tracking, and global mapping metrics. Experimental results demonstrate the superiority of IC-Mapper against other state-of-the-art methods. Code will be released on https://github.com/Brickzhuantou/IC-Mapper.
Monocular Lane Detection Based on Deep Learning: A Survey
Nov 26, 2024



Lane detection plays an important role in autonomous driving perception systems. As deep learning algorithms gain popularity, monocular lane detection methods based on deep learning have demonstrated superior performance and emerged as a key research direction in autonomous driving perception. The core design of these algorithmic frameworks can be summarized as follows: (1) Task paradigm, focusing on lane instance-level discrimination; (2) Lane modeling, representing lanes as a set of learnable parameters in the neural network; (3) Global context supplementation, enhancing the detection of obscure lanes; (4) Perspective effect elimination, providing 3D lanes usable for downstream applications. From these perspectives, this paper presents a comprehensive overview of existing methods, encompassing both the increasingly mature 2D lane detection approaches and the developing 3D lane detection works. For a relatively fair comparison, in addition to comparing the performance of mainstream methods on different benchmarks, their inference speed is also investigated under a unified setting. Moreover, we present some extended works on lane detection, including multi-task perception, video lane detection, online high-definition map construction, and lane topology reasoning, to offer readers a comprehensive roadmap for the evolution of lane detection. Finally, we point out some potential future research directions in this field. We exhaustively collect the papers and codes of existing works at https://github.com/Core9724/Awesome-Lane-Detection and will keep tracing the research.
HeightMapNet: Explicit Height Modeling for End-to-End HD Map Learning
Nov 03, 2024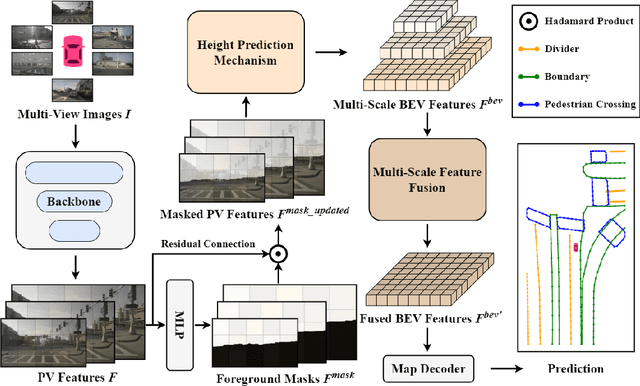

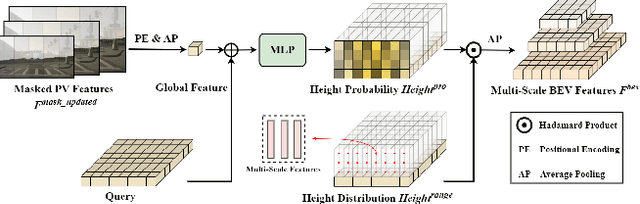

Recent advances in high-definition (HD) map construction from surround-view images have highlighted their cost-effectiveness in deployment. However, prevailing techniques often fall short in accurately extracting and utilizing road features, as well as in the implementation of view transformation. In response, we introduce HeightMapNet, a novel framework that establishes a dynamic relationship between image features and road surface height distributions. By integrating height priors, our approach refines the accuracy of Bird's-Eye-View (BEV) features beyond conventional methods. HeightMapNet also introduces a foreground-background separation network that sharply distinguishes between critical road elements and extraneous background components, enabling precise focus on detailed road micro-features. Additionally, our method leverages multi-scale features within the BEV space, optimally utilizing spatial geometric information to boost model performance. HeightMapNet has shown exceptional results on the challenging nuScenes and Argoverse 2 datasets, outperforming several widely recognized approaches. The code will be available at \url{https://github.com/adasfag/HeightMapNet/}.
EVD4UAV: An Altitude-Sensitive Benchmark to Evade Vehicle Detection in UAV
Mar 08, 2024



Vehicle detection in Unmanned Aerial Vehicle (UAV) captured images has wide applications in aerial photography and remote sensing. There are many public benchmark datasets proposed for the vehicle detection and tracking in UAV images. Recent studies show that adding an adversarial patch on objects can fool the well-trained deep neural networks based object detectors, posing security concerns to the downstream tasks. However, the current public UAV datasets might ignore the diverse altitudes, vehicle attributes, fine-grained instance-level annotation in mostly side view with blurred vehicle roof, so none of them is good to study the adversarial patch based vehicle detection attack problem. In this paper, we propose a new dataset named EVD4UAV as an altitude-sensitive benchmark to evade vehicle detection in UAV with 6,284 images and 90,886 fine-grained annotated vehicles. The EVD4UAV dataset has diverse altitudes (50m, 70m, 90m), vehicle attributes (color, type), fine-grained annotation (horizontal and rotated bounding boxes, instance-level mask) in top view with clear vehicle roof. One white-box and two black-box patch based attack methods are implemented to attack three classic deep neural networks based object detectors on EVD4UAV. The experimental results show that these representative attack methods could not achieve the robust altitude-insensitive attack performance.
Abductive Ego-View Accident Video Understanding for Safe Driving Perception
Mar 01, 2024
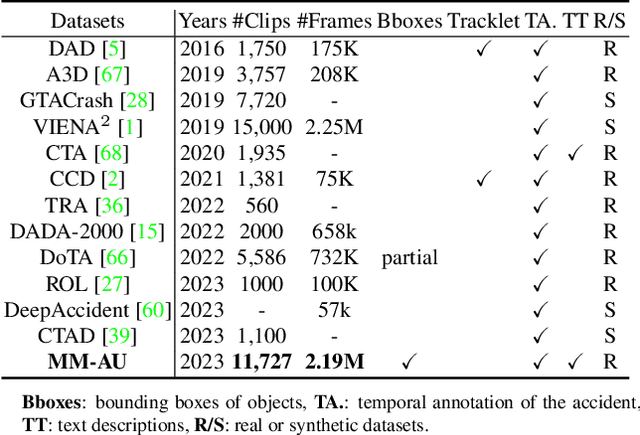
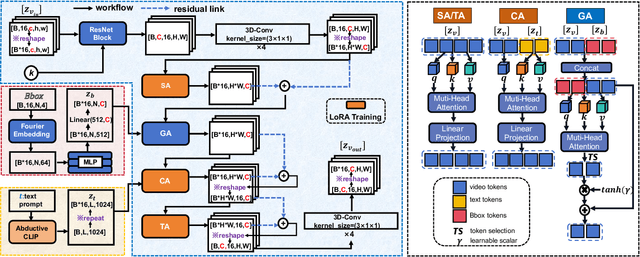
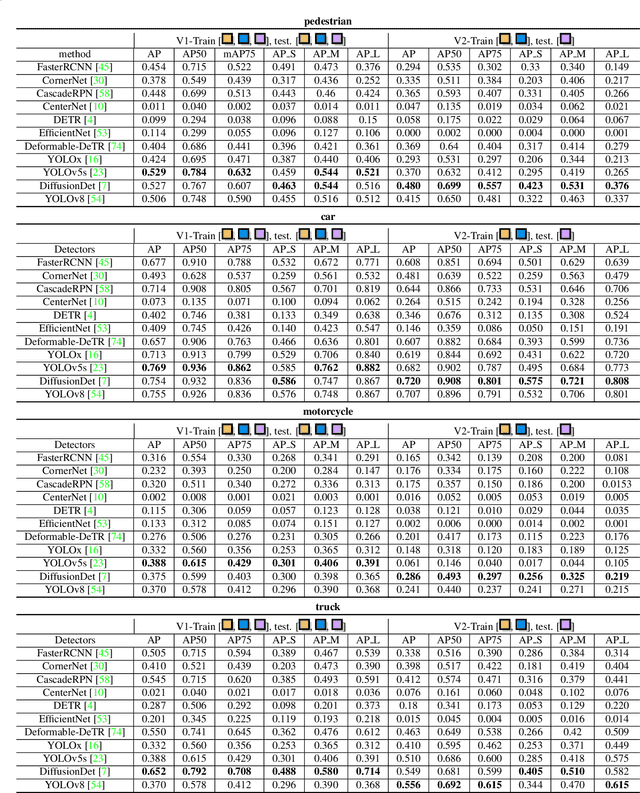
We present MM-AU, a novel dataset for Multi-Modal Accident video Understanding. MM-AU contains 11,727 in-the-wild ego-view accident videos, each with temporally aligned text descriptions. We annotate over 2.23 million object boxes and 58,650 pairs of video-based accident reasons, covering 58 accident categories. MM-AU supports various accident understanding tasks, particularly multimodal video diffusion to understand accident cause-effect chains for safe driving. With MM-AU, we present an Abductive accident Video understanding framework for Safe Driving perception (AdVersa-SD). AdVersa-SD performs video diffusion via an Object-Centric Video Diffusion (OAVD) method which is driven by an abductive CLIP model. This model involves a contrastive interaction loss to learn the pair co-occurrence of normal, near-accident, accident frames with the corresponding text descriptions, such as accident reasons, prevention advice, and accident categories. OAVD enforces the causal region learning while fixing the content of the original frame background in video generation, to find the dominant cause-effect chain for certain accidents. Extensive experiments verify the abductive ability of AdVersa-SD and the superiority of OAVD against the state-of-the-art diffusion models. Additionally, we provide careful benchmark evaluations for object detection and accident reason answering since AdVersa-SD relies on precise object and accident reason information.
Vehicle Behavior Prediction by Episodic-Memory Implanted NDT
Feb 13, 2024



In autonomous driving, predicting the behavior (turning left, stopping, etc.) of target vehicles is crucial for the self-driving vehicle to make safe decisions and avoid accidents. Existing deep learning-based methods have shown excellent and accurate performance, but the black-box nature makes it untrustworthy to apply them in practical use. In this work, we explore the interpretability of behavior prediction of target vehicles by an Episodic Memory implanted Neural Decision Tree (abbrev. eMem-NDT). The structure of eMem-NDT is constructed by hierarchically clustering the text embedding of vehicle behavior descriptions. eMem-NDT is a neural-backed part of a pre-trained deep learning model by changing the soft-max layer of the deep model to eMem-NDT, for grouping and aligning the memory prototypes of the historical vehicle behavior features in training data on a neural decision tree. Each leaf node of eMem-NDT is modeled by a neural network for aligning the behavior memory prototypes. By eMem-NDT, we infer each instance in behavior prediction of vehicles by bottom-up Memory Prototype Matching (MPM) (searching the appropriate leaf node and the links to the root node) and top-down Leaf Link Aggregation (LLA) (obtaining the probability of future behaviors of vehicles for certain instances). We validate eMem-NDT on BLVD and LOKI datasets, and the results show that our model can obtain a superior performance to other methods with clear explainability. The code is available at https://github.com/JWFangit/eMem-NDT.