 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrism: Efficient Test-Time Scaling via Hierarchical Search and Self-Verification for Discrete Diffusion Language Models
Feb 02, 2026Inference-time compute has re-emerged as a practical way to improve LLM reasoning. Most test-time scaling (TTS) algorithms rely on autoregressive decoding, which is ill-suited to discrete diffusion language models (dLLMs) due to their parallel decoding over the entire sequence. As a result, developing effective and efficient TTS methods to unlock dLLMs' full generative potential remains an underexplored challenge. To address this, we propose Prism (Pruning, Remasking, and Integrated Self-verification Method), an efficient TTS framework for dLLMs that (i) performs Hierarchical Trajectory Search (HTS) which dynamically prunes and reallocates compute in an early-to-mid denoising window, (ii) introduces Local branching with partial remasking to explore diverse implementations while preserving high-confidence tokens, and (iii) replaces external verifiers with Self-Verified Feedback (SVF) obtained via self-evaluation prompts on intermediate completions. Across four mathematical reasoning and code generation benchmarks on three dLLMs, including LLaDA 8B Instruct, Dream 7B Instruct, and LLaDA 2.0-mini, our Prism achieves a favorable performance-efficiency trade-off, matching best-of-N performance with substantially fewer function evaluations (NFE). The code is released at https://github.com/viiika/Prism.
A Human-Oriented Cooperative Driving Approach: Integrating Driving Intention, State, and Conflict
Dec 29, 2025Human-vehicle cooperative driving serves as a vital bridge to fully autonomous driving by improving driving flexibility and gradually building driver trust and acceptance of autonomous technology. To establish more natural and effective human-vehicle interaction, we propose a Human-Oriented Cooperative Driving (HOCD) approach that primarily minimizes human-machine conflict by prioritizing driver intention and state. In implementation, we take both tactical and operational levels into account to ensure seamless human-vehicle cooperation. At the tactical level, we design an intention-aware trajectory planning method, using intention consistency cost as the core metric to evaluate the trajectory and align it with driver intention. At the operational level, we develop a control authority allocation strategy based on reinforcement learning, optimizing the policy through a designed reward function to achieve consistency between driver state and authority allocation. The results of simulation and human-in-the-loop experiments demonstrate that our proposed approach not only aligns with driver intention in trajectory planning but also ensures a reasonable authority allocation. Compared to other cooperative driving approaches, the proposed HOCD approach significantly enhances driving performance and mitigates human-machine conflict.The code is available at https://github.com/i-Qin/HOCD.
COVLM-RL: Critical Object-Oriented Reasoning for Autonomous Driving Using VLM-Guided Reinforcement Learning
Dec 10, 2025End-to-end autonomous driving frameworks face persistent challenges in generalization, training efficiency, and interpretability. While recent methods leverage Vision-Language Models (VLMs) through supervised learning on large-scale datasets to improve reasoning, they often lack robustness in novel scenarios. Conversely, reinforcement learning (RL)-based approaches enhance adaptability but remain data-inefficient and lack transparent decision-making. % contribution To address these limitations, we propose COVLM-RL, a novel end-to-end driving framework that integrates Critical Object-oriented (CO) reasoning with VLM-guided RL. Specifically, we design a Chain-of-Thought (CoT) prompting strategy that enables the VLM to reason over critical traffic elements and generate high-level semantic decisions, effectively transforming multi-view visual inputs into structured semantic decision priors. These priors reduce the input dimensionality and inject task-relevant knowledge into the RL loop, accelerating training and improving policy interpretability. However, bridging high-level semantic guidance with continuous low-level control remains non-trivial. To this end, we introduce a consistency loss that encourages alignment between the VLM's semantic plans and the RL agent's control outputs, enhancing interpretability and training stability. Experiments conducted in the CARLA simulator demonstrate that COVLM-RL significantly improves the success rate by 30\% in trained driving environments and by 50\% in previously unseen environments, highlighting its strong generalization capability.
IC-Mapper: Instance-Centric Spatio-Temporal Modeling for Online Vectorized Map Construction
Mar 05, 2025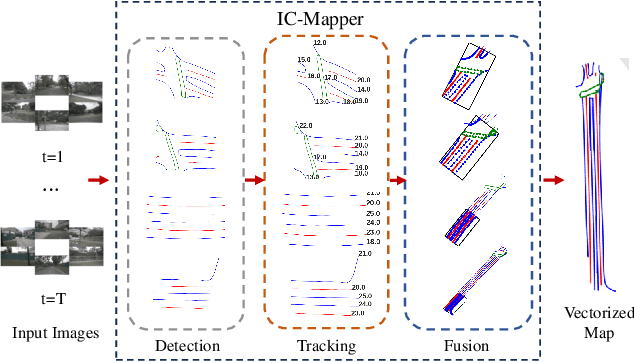
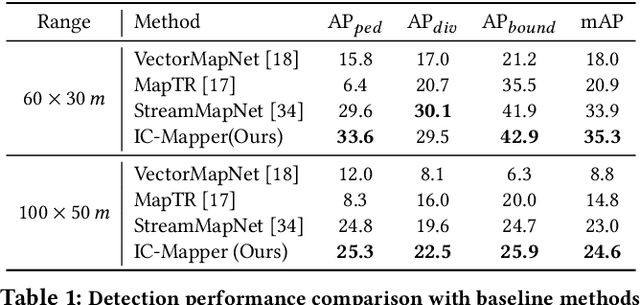

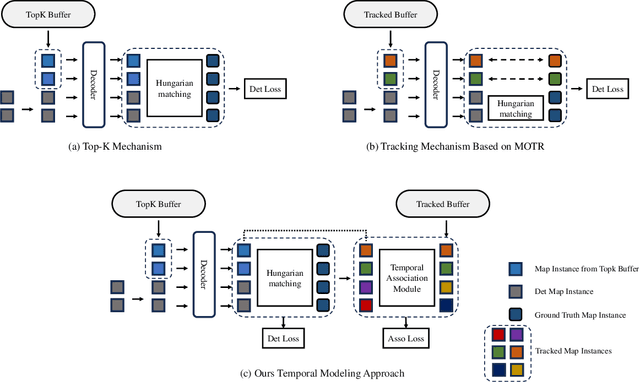
Online vector map construction based on visual data can bypass the processes of data collection, post-processing, and manual annotation required by traditional map construction, which significantly enhances map-building efficiency. However, existing work treats the online mapping task as a local range perception task, overlooking the spatial scalability required for map construction. We propose IC-Mapper, an instance-centric online mapping framework, which comprises two primary components: 1) Instance-centric temporal association module: For the detection queries of adjacent frames, we measure them in both feature and geometric dimensions to obtain the matching correspondence between instances across frames. 2) Instance-centric spatial fusion module: We perform point sampling on the historical global map from a spatial dimension and integrate it with the detection results of instances corresponding to the current frame to achieve real-time expansion and update of the map. Based on the nuScenes dataset, we evaluate our approach on detection, tracking, and global mapping metrics. Experimental results demonstrate the superiority of IC-Mapper against other state-of-the-art methods. Code will be released on https://github.com/Brickzhuantou/IC-Mapper.
Redundant Queries in DETR-Based 3D Detection Methods: Unnecessary and Prunable
Dec 03, 2024



Query-based models are extensively used in 3D object detection tasks, with a wide range of pre-trained checkpoints readily available online. However, despite their popularity, these models often require an excessive number of object queries, far surpassing the actual number of objects to detect. The redundant queries result in unnecessary computational and memory costs. In this paper, we find that not all queries contribute equally -- a significant portion of queries have a much smaller impact compared to others. Based on this observation, we propose an embarrassingly simple approach called \bd{G}radually \bd{P}runing \bd{Q}ueries (GPQ), which prunes queries incrementally based on their classification scores. It is straightforward to implement in any query-based method, as it can be seamlessly integrated as a fine-tuning step using an existing checkpoint after training. With GPQ, users can easily generate multiple models with fewer queries, starting from a checkpoint with an excessive number of queries. Experiments on various advanced 3D detectors show that GPQ effectively reduces redundant queries while maintaining performance. Using our method, model inference on desktop GPUs can be accelerated by up to 1.31x. Moreover, after deployment on edge devices, it achieves up to a 67.86\% reduction in FLOPs and a 76.38\% decrease in inference time. The code will be available at \url{https://github.com/iseri27/Gpq}.
HeightMapNet: Explicit Height Modeling for End-to-End HD Map Learning
Nov 03, 2024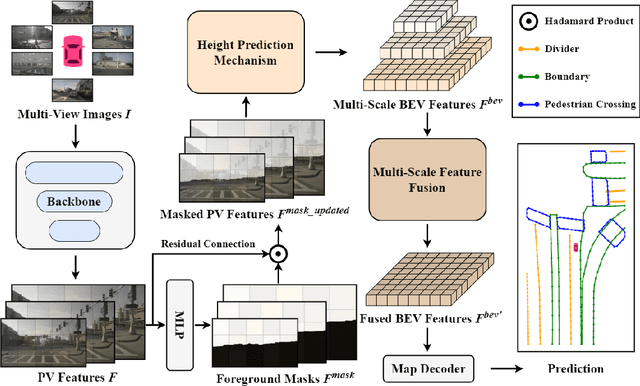

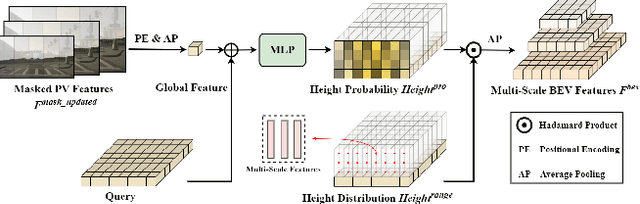

Recent advances in high-definition (HD) map construction from surround-view images have highlighted their cost-effectiveness in deployment. However, prevailing techniques often fall short in accurately extracting and utilizing road features, as well as in the implementation of view transformation. In response, we introduce HeightMapNet, a novel framework that establishes a dynamic relationship between image features and road surface height distributions. By integrating height priors, our approach refines the accuracy of Bird's-Eye-View (BEV) features beyond conventional methods. HeightMapNet also introduces a foreground-background separation network that sharply distinguishes between critical road elements and extraneous background components, enabling precise focus on detailed road micro-features. Additionally, our method leverages multi-scale features within the BEV space, optimally utilizing spatial geometric information to boost model performance. HeightMapNet has shown exceptional results on the challenging nuScenes and Argoverse 2 datasets, outperforming several widely recognized approaches. The code will be available at \url{https://github.com/adasfag/HeightMapNet/}.
Abductive Ego-View Accident Video Understanding for Safe Driving Perception
Mar 01, 2024
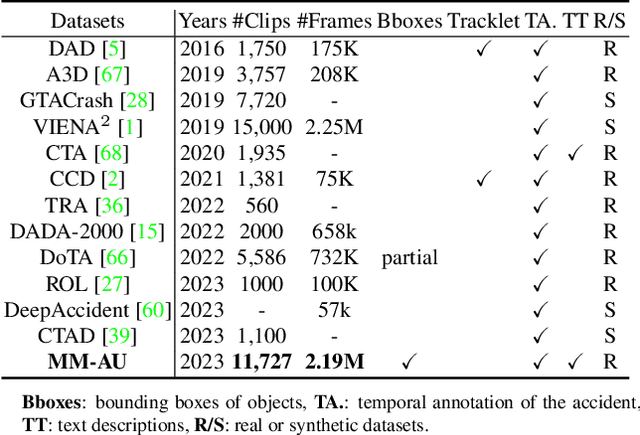
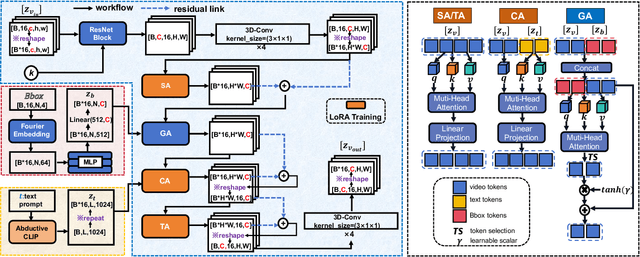
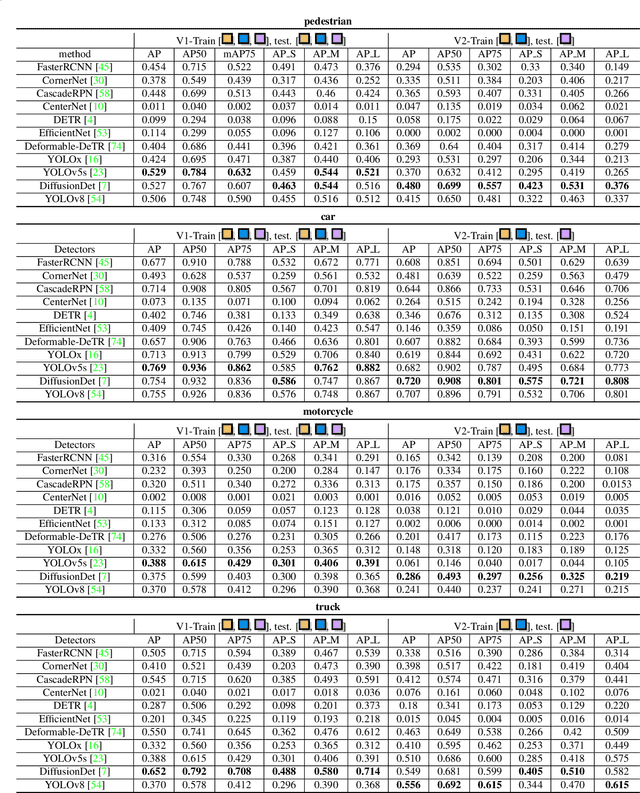
We present MM-AU, a novel dataset for Multi-Modal Accident video Understanding. MM-AU contains 11,727 in-the-wild ego-view accident videos, each with temporally aligned text descriptions. We annotate over 2.23 million object boxes and 58,650 pairs of video-based accident reasons, covering 58 accident categories. MM-AU supports various accident understanding tasks, particularly multimodal video diffusion to understand accident cause-effect chains for safe driving. With MM-AU, we present an Abductive accident Video understanding framework for Safe Driving perception (AdVersa-SD). AdVersa-SD performs video diffusion via an Object-Centric Video Diffusion (OAVD) method which is driven by an abductive CLIP model. This model involves a contrastive interaction loss to learn the pair co-occurrence of normal, near-accident, accident frames with the corresponding text descriptions, such as accident reasons, prevention advice, and accident categories. OAVD enforces the causal region learning while fixing the content of the original frame background in video generation, to find the dominant cause-effect chain for certain accidents. Extensive experiments verify the abductive ability of AdVersa-SD and the superiority of OAVD against the state-of-the-art diffusion models. Additionally, we provide careful benchmark evaluations for object detection and accident reason answering since AdVersa-SD relies on precise object and accident reason information.
Vehicle Behavior Prediction by Episodic-Memory Implanted NDT
Feb 13, 2024



In autonomous driving, predicting the behavior (turning left, stopping, etc.) of target vehicles is crucial for the self-driving vehicle to make safe decisions and avoid accidents. Existing deep learning-based methods have shown excellent and accurate performance, but the black-box nature makes it untrustworthy to apply them in practical use. In this work, we explore the interpretability of behavior prediction of target vehicles by an Episodic Memory implanted Neural Decision Tree (abbrev. eMem-NDT). The structure of eMem-NDT is constructed by hierarchically clustering the text embedding of vehicle behavior descriptions. eMem-NDT is a neural-backed part of a pre-trained deep learning model by changing the soft-max layer of the deep model to eMem-NDT, for grouping and aligning the memory prototypes of the historical vehicle behavior features in training data on a neural decision tree. Each leaf node of eMem-NDT is modeled by a neural network for aligning the behavior memory prototypes. By eMem-NDT, we infer each instance in behavior prediction of vehicles by bottom-up Memory Prototype Matching (MPM) (searching the appropriate leaf node and the links to the root node) and top-down Leaf Link Aggregation (LLA) (obtaining the probability of future behaviors of vehicles for certain instances). We validate eMem-NDT on BLVD and LOKI datasets, and the results show that our model can obtain a superior performance to other methods with clear explainability. The code is available at https://github.com/JWFangit/eMem-NDT.
Vision-Based Traffic Accident Detection and Anticipation: A Survey
Aug 30, 2023



Traffic accident detection and anticipation is an obstinate road safety problem and painstaking efforts have been devoted. With the rapid growth of video data, Vision-based Traffic Accident Detection and Anticipation (named Vision-TAD and Vision-TAA) become the last one-mile problem for safe driving and surveillance safety. However, the long-tailed, unbalanced, highly dynamic, complex, and uncertain properties of traffic accidents form the Out-of-Distribution (OOD) feature for Vision-TAD and Vision-TAA. Current AI development may focus on these OOD but important problems. What has been done for Vision-TAD and Vision-TAA? What direction we should focus on in the future for this problem? A comprehensive survey is important. We present the first survey on Vision-TAD in the deep learning era and the first-ever survey for Vision-TAA. The pros and cons of each research prototype are discussed in detail during the investigation. In addition, we also provide a critical review of 31 publicly available benchmarks and related evaluation metrics. Through this survey, we want to spawn new insights and open possible trends for Vision-TAD and Vision-TAA tasks.
Gated Driver Attention Predictor
Aug 01, 2023Driver attention prediction implies the intention understanding of where the driver intends to go and what object the driver concerned about, which commonly provides a driving task-guided traffic scene understanding. Some recent works explore driver attention prediction in critical or accident scenarios and find a positive role in helping accident prediction, while the promotion ability is constrained by the prediction accuracy of driver attention maps. In this work, we explore the network connection gating mechanism for driver attention prediction (Gate-DAP). Gate-DAP aims to learn the importance of different spatial, temporal, and modality information in driving scenarios with various road types, occasions, and light and weather conditions. The network connection gating in Gate-DAP consists of a spatial encoding network gating, long-short-term memory network gating, and information type gating modules. Each connection gating operation is plug-and-play and can be flexibly assembled, which makes the architecture of Gate-DAP transparent for evaluating different spatial, temporal, and information types for driver attention prediction. Evaluations on DADA-2000 and BDDA datasets verify the superiority of the proposed method with the comparison with state-of-the-art approaches. The code is available on https://github.com/JWFangit/Gate-DAP.