 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuangMing-Explorer: A Four-Legged Robot Platform for Autonomous Exploration in General Environments
Dec 17, 2025Autonomous exploration is a fundamental capability that tightly integrates perception, planning, control, and motion execution. It plays a critical role in a wide range of applications, including indoor target search, mapping of extreme environments, resource exploration, etc. Despite significant progress in individual components, a holistic and practical description of a completely autonomous exploration system, encompassing both hardware and software, remains scarce. In this paper, we present GuangMing-Explorer, a fully integrated autonomous exploration platform designed for robust operation across diverse environments. We provide a comprehensive overview of the system architecture, including hardware design, software stack, algorithm deployment, and experimental configuration. Extensive real-world experiments demonstrate the platform's effectiveness and efficiency in executing autonomous exploration tasks, highlighting its potential for practical deployment in complex and unstructured environments.
Exploring Embodied Multimodal Large Models: Development, Datasets, and Future Directions
Feb 21, 2025
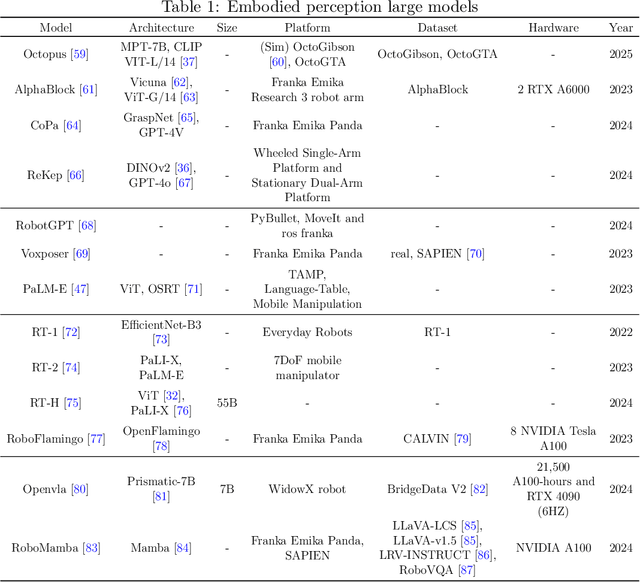

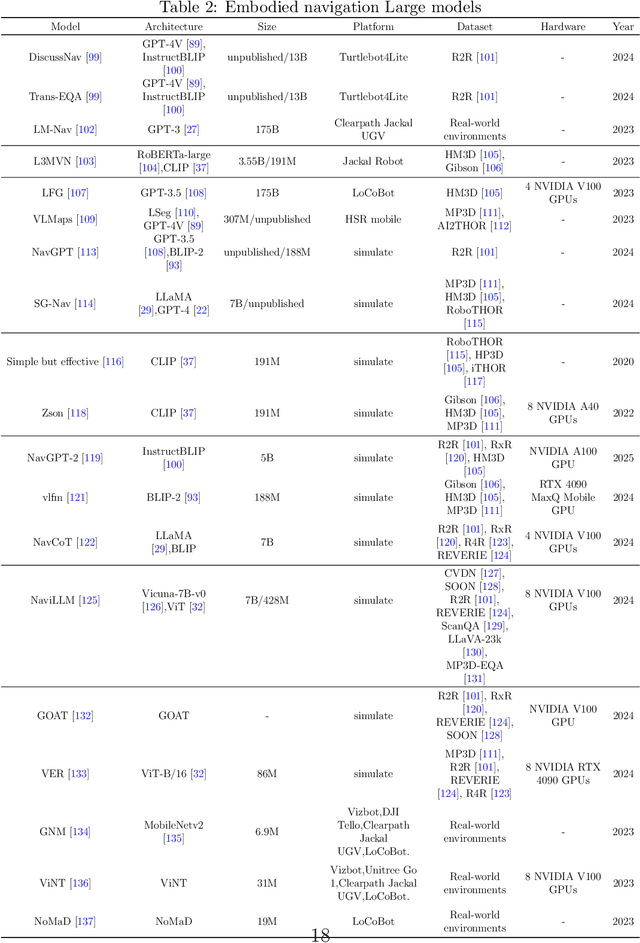
Embodied multimodal large models (EMLMs) have gained significant attention in recent years due to their potential to bridge the gap between perception, cognition, and action in complex, real-world environments. This comprehensive review explores the development of such models, including Large Language Models (LLMs), Large Vision Models (LVMs), and other models, while also examining other emerging architectures. We discuss the evolution of EMLMs, with a focus on embodied perception, navigation, interaction, and simulation. Furthermore, the review provides a detailed analysis of the datasets used for training and evaluating these models, highlighting the importance of diverse, high-quality data for effective learning. The paper also identifies key challenges faced by EMLMs, including issues of scalability, generalization, and real-time decision-making. Finally, we outline future directions, emphasizing the integration of multimodal sensing, reasoning, and action to advance the development of increasingly autonomous systems. By providing an in-depth analysis of state-of-the-art methods and identifying critical gaps, this paper aims to inspire future advancements in EMLMs and their applications across diverse domains.
Redundant Queries in DETR-Based 3D Detection Methods: Unnecessary and Prunable
Dec 03, 2024



Query-based models are extensively used in 3D object detection tasks, with a wide range of pre-trained checkpoints readily available online. However, despite their popularity, these models often require an excessive number of object queries, far surpassing the actual number of objects to detect. The redundant queries result in unnecessary computational and memory costs. In this paper, we find that not all queries contribute equally -- a significant portion of queries have a much smaller impact compared to others. Based on this observation, we propose an embarrassingly simple approach called \bd{G}radually \bd{P}runing \bd{Q}ueries (GPQ), which prunes queries incrementally based on their classification scores. It is straightforward to implement in any query-based method, as it can be seamlessly integrated as a fine-tuning step using an existing checkpoint after training. With GPQ, users can easily generate multiple models with fewer queries, starting from a checkpoint with an excessive number of queries. Experiments on various advanced 3D detectors show that GPQ effectively reduces redundant queries while maintaining performance. Using our method, model inference on desktop GPUs can be accelerated by up to 1.31x. Moreover, after deployment on edge devices, it achieves up to a 67.86\% reduction in FLOPs and a 76.38\% decrease in inference time. The code will be available at \url{https://github.com/iseri27/Gpq}.
Lane Detection in Low-light Conditions Using an Efficient Data Enhancement : Light Conditions Style Transfer
Feb 04, 2020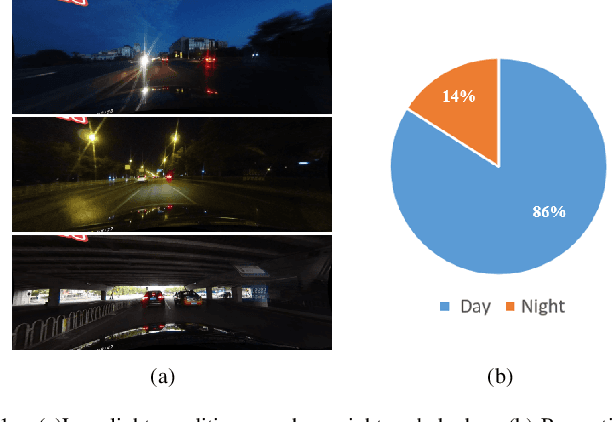

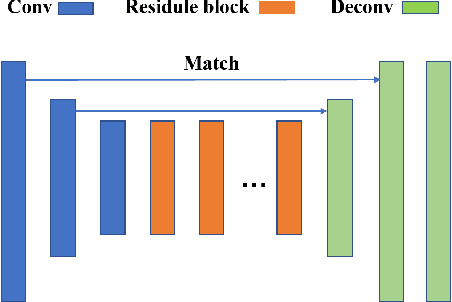

Nowadays, deep learning techniques are widely used for lane detection, but application in low-light conditions remains a challenge until this day. Although multi-task learning and contextual information based methods have been proposed to solve the problem, they either require additional manual annotations or introduce extra inference computation respectively. In this paper, we propose a style-transfer-based data enhancement method, which uses Generative Adversarial Networks (GANs) to generate images in low-light conditions, that increases the environmental adaptability of the lane detector. Our solution consists of three models: the proposed Better-CycleGAN, light conditions style transfer network and lane detection network. It does not require additional manual annotations nor extra inference computation. We validated our methods on the lane detection benchmark CULane using ERFNet. Empirically, lane detection model trained using our method demonstrated adaptability in low-light conditions and robustness in complex scenarios. Our code for this paper will be publicly available.