 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerate 3D Object Detection Models via Zero-Shot Attention Key Pruning
Mar 11, 2025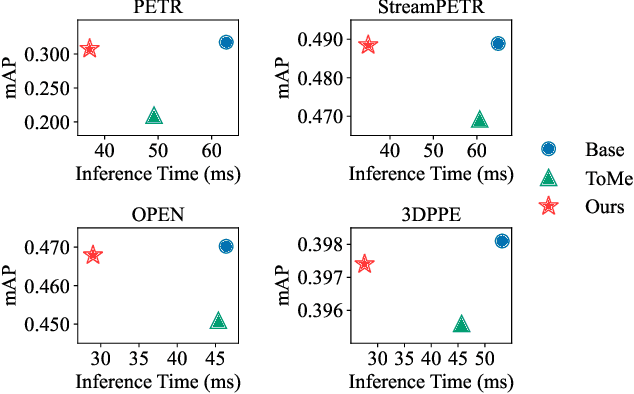
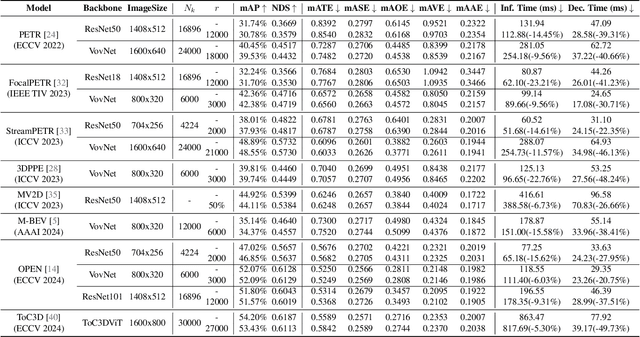
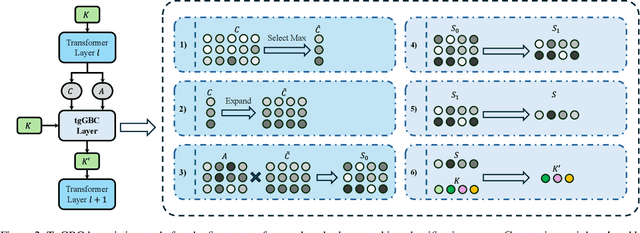
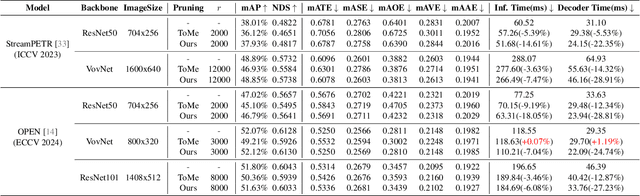
Query-based methods with dense features have demonstrated remarkable success in 3D object detection tasks. However, the computational demands of these models, particularly with large image sizes and multiple transformer layers, pose significant challenges for efficient running on edge devices. Existing pruning and distillation methods either need retraining or are designed for ViT models, which are hard to migrate to 3D detectors. To address this issue, we propose a zero-shot runtime pruning method for transformer decoders in 3D object detection models. The method, termed tgGBC (trim keys gradually Guided By Classification scores), systematically trims keys in transformer modules based on their importance. We expand the classification score to multiply it with the attention map to get the importance score of each key and then prune certain keys after each transformer layer according to their importance scores. Our method achieves a 1.99x speedup in the transformer decoder of the latest ToC3D model, with only a minimal performance loss of less than 1%. Interestingly, for certain models, our method even enhances their performance. Moreover, we deploy 3D detectors with tgGBC on an edge device, further validating the effectiveness of our method. The code can be found at https://github.com/iseri27/tg_gbc.
Redundant Queries in DETR-Based 3D Detection Methods: Unnecessary and Prunable
Dec 03, 2024



Query-based models are extensively used in 3D object detection tasks, with a wide range of pre-trained checkpoints readily available online. However, despite their popularity, these models often require an excessive number of object queries, far surpassing the actual number of objects to detect. The redundant queries result in unnecessary computational and memory costs. In this paper, we find that not all queries contribute equally -- a significant portion of queries have a much smaller impact compared to others. Based on this observation, we propose an embarrassingly simple approach called \bd{G}radually \bd{P}runing \bd{Q}ueries (GPQ), which prunes queries incrementally based on their classification scores. It is straightforward to implement in any query-based method, as it can be seamlessly integrated as a fine-tuning step using an existing checkpoint after training. With GPQ, users can easily generate multiple models with fewer queries, starting from a checkpoint with an excessive number of queries. Experiments on various advanced 3D detectors show that GPQ effectively reduces redundant queries while maintaining performance. Using our method, model inference on desktop GPUs can be accelerated by up to 1.31x. Moreover, after deployment on edge devices, it achieves up to a 67.86\% reduction in FLOPs and a 76.38\% decrease in inference time. The code will be available at \url{https://github.com/iseri27/Gpq}.
Multiple-Choice Questions are Efficient and Robust LLM Evaluators
May 21, 2024



We present GSM-MC and MATH-MC, two multiple-choice (MC) datasets constructed by collecting answers and incorrect predictions on GSM8K and MATH from over 50 open-source models. Through extensive experiments, we show that LLMs' performance on the MC versions of these two popular benchmarks is strongly correlated with their performance on the original versions, and is quite robust to distractor choices and option orders, while the evaluation time is reduced by a factor of up to 30. Following a similar procedure, we also introduce PythonIO, a new program output prediction MC dataset constructed from two other popular LLM evaluation benchmarks HumanEval and MBPP. Our data and code are available at https://github.com/Geralt-Targaryen/MC-Evaluation.
R-Judge: Benchmarking Safety Risk Awareness for LLM Agents
Jan 18, 2024



Large language models (LLMs) have exhibited great potential in autonomously completing tasks across real-world applications. Despite this, these LLM agents introduce unexpected safety risks when operating in interactive environments. Instead of centering on LLM-generated content safety in most prior studies, this work addresses the imperative need for benchmarking the behavioral safety of LLM agents within diverse environments. We introduce R-Judge, a benchmark crafted to evaluate the proficiency of LLMs in judging safety risks given agent interaction records. R-Judge comprises 162 agent interaction records, encompassing 27 key risk scenarios among 7 application categories and 10 risk types. It incorporates human consensus on safety with annotated safety risk labels and high-quality risk descriptions. Utilizing R-Judge, we conduct a comprehensive evaluation of 8 prominent LLMs commonly employed as the backbone for agents. The best-performing model, GPT-4, achieves 72.29% in contrast to the human score of 89.38%, showing considerable room for enhancing the risk awareness of LLMs. Notably, leveraging risk descriptions as environment feedback significantly improves model performance, revealing the importance of salient safety risk feedback. Furthermore, we design an effective chain of safety analysis technique to help the judgment of safety risks and conduct an in-depth case study to facilitate future research. R-Judge is publicly available at https://github.com/Lordog/R-Judge.