 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3-ASR Technical Report
Jan 29, 2026In this report, we introduce Qwen3-ASR family, which includes two powerful all-in-one speech recognition models and a novel non-autoregressive speech forced alignment model. Qwen3-ASR-1.7B and Qwen3-ASR-0.6B are ASR models that support language identification and ASR for 52 languages and dialects. Both of them leverage large-scale speech training data and the strong audio understanding ability of their foundation model Qwen3-Omni. We conduct comprehensive internal evaluation besides the open-sourced benchmarks as ASR models might differ little on open-sourced benchmark scores but exhibit significant quality differences in real-world scenarios. The experiments reveal that the 1.7B version achieves SOTA performance among open-sourced ASR models and is competitive with the strongest proprietary APIs while the 0.6B version offers the best accuracy-efficiency trade-off. Qwen3-ASR-0.6B can achieve an average TTFT as low as 92ms and transcribe 2000 seconds speech in 1 second at a concurrency of 128. Qwen3-ForcedAligner-0.6B is an LLM based NAR timestamp predictor that is able to align text-speech pairs in 11 languages. Timestamp accuracy experiments show that the proposed model outperforms the three strongest force alignment models and takes more advantages in efficiency and versatility. To further accelerate the community research of ASR and audio understanding, we release these models under the Apache 2.0 license.
Qwen3-TTS Technical Report
Jan 22, 2026In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of-the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis, coupled with two speech tokenizers: 1) Qwen-TTS-Tokenizer-25Hz is a single-codebook codec emphasizing semantic content, which offers seamlessly integration with Qwen-Audio and enables streaming waveform reconstruction via a block-wise DiT. 2) Qwen-TTS-Tokenizer-12Hz achieves extreme bitrate reduction and ultra-low-latency streaming, enabling immediate first-packet emission ($97\,\mathrm{ms}$) through its 12.5 Hz, 16-layer multi-codebook design and a lightweight causal ConvNet. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
Multiple-Choice Questions are Efficient and Robust LLM Evaluators
May 21, 2024



We present GSM-MC and MATH-MC, two multiple-choice (MC) datasets constructed by collecting answers and incorrect predictions on GSM8K and MATH from over 50 open-source models. Through extensive experiments, we show that LLMs' performance on the MC versions of these two popular benchmarks is strongly correlated with their performance on the original versions, and is quite robust to distractor choices and option orders, while the evaluation time is reduced by a factor of up to 30. Following a similar procedure, we also introduce PythonIO, a new program output prediction MC dataset constructed from two other popular LLM evaluation benchmarks HumanEval and MBPP. Our data and code are available at https://github.com/Geralt-Targaryen/MC-Evaluation.
G-Refine: A General Quality Refiner for Text-to-Image Generation
Apr 29, 2024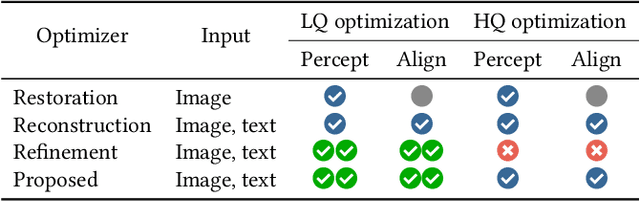
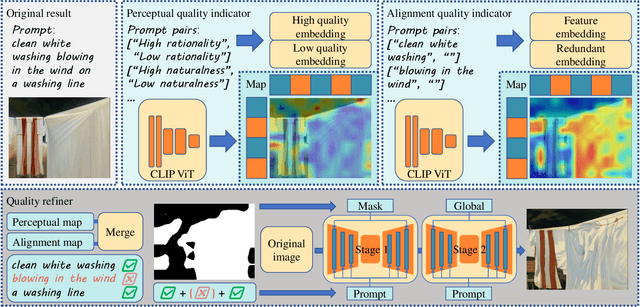
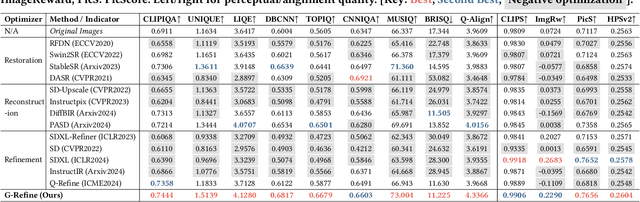
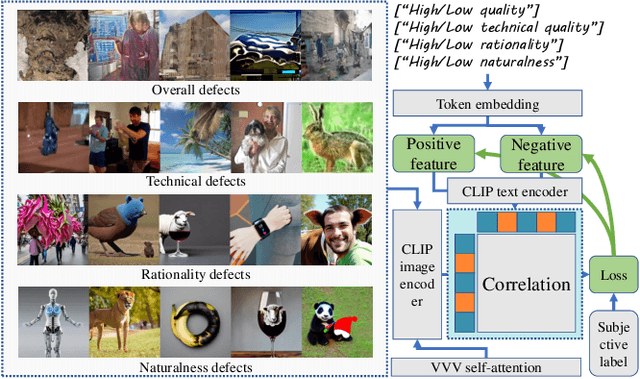
With the evolution of Text-to-Image (T2I) models, the quality defects of AI-Generated Images (AIGIs) pose a significant barrier to their widespread adoption. In terms of both perception and alignment, existing models cannot always guarantee high-quality results. To mitigate this limitation, we introduce G-Refine, a general image quality refiner designed to enhance low-quality images without compromising the integrity of high-quality ones. The model is composed of three interconnected modules: a perception quality indicator, an alignment quality indicator, and a general quality enhancement module. Based on the mechanisms of the Human Visual System (HVS) and syntax trees, the first two indicators can respectively identify the perception and alignment deficiencies, and the last module can apply targeted quality enhancement accordingly. Extensive experimentation reveals that when compared to alternative optimization methods, AIGIs after G-Refine outperform in 10+ quality metrics across 4 databases. This improvement significantly contributes to the practical application of contemporary T2I models, paving the way for their broader adoption. The code will be released on https://github.com/Q-Future/Q-Refine.
WavLLM: Towards Robust and Adaptive Speech Large Language Model
Mar 31, 2024The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at \url{aka.ms/wavllm}.
Improving Open-Ended Text Generation via Adaptive Decoding
Feb 28, 2024



Current language models decode text token by token according to probabilistic distribution, and determining the appropriate candidates for the next token is crucial to ensure generation quality. This study introduces adaptive decoding, a mechanism that empowers the language models to ascertain a sensible candidate set during the generation process dynamically. Specifically, we introduce an entropy-based metric called confidence and conceptualize determining the optimal candidate set as a confidence-increasing process. The rationality of including a token in the candidate set is assessed by leveraging the increment of confidence, enabling the model to determine the most suitable candidate set adaptively. The experimental results reveal that our method achieves higher MAUVE and diversity in story generation tasks and maintains certain coherence, underscoring its superiority over existing algorithms. The code is available at https://github.com/zwhong714/adaptive_decoding.
Is Cognition and Action Consistent or Not: Investigating Large Language Model's Personality
Feb 22, 2024In this study, we investigate the reliability of Large Language Models (LLMs) in professing human-like personality traits through responses to personality questionnaires. Our goal is to evaluate the consistency between LLMs' professed personality inclinations and their actual "behavior", examining the extent to which these models can emulate human-like personality patterns. Through a comprehensive analysis of LLM outputs against established human benchmarks, we seek to understand the cognition-action divergence in LLMs and propose hypotheses for the observed results based on psychological theories and metrics.
Can Watermarks Survive Translation? On the Cross-lingual Consistency of Text Watermark for Large Language Models
Feb 21, 2024



Text watermarking technology aims to tag and identify content produced by large language models (LLMs) to prevent misuse. In this study, we introduce the concept of ''cross-lingual consistency'' in text watermarking, which assesses the ability of text watermarks to maintain their effectiveness after being translated into other languages. Preliminary empirical results from two LLMs and three watermarking methods reveal that current text watermarking technologies lack consistency when texts are translated into various languages. Based on this observation, we propose a Cross-lingual Watermark Removal Attack (CWRA) to bypass watermarking by first obtaining a response from an LLM in a pivot language, which is then translated into the target language. CWRA can effectively remove watermarks by reducing the Area Under the Curve (AUC) from 0.95 to 0.67 without performance loss. Furthermore, we analyze two key factors that contribute to the cross-lingual consistency in text watermarking and propose a defense method that increases the AUC from 0.67 to 0.88 under CWRA.
Q-Refine: A Perceptual Quality Refiner for AI-Generated Image
Jan 02, 2024With the rapid evolution of the Text-to-Image (T2I) model in recent years, their unsatisfactory generation result has become a challenge. However, uniformly refining AI-Generated Images (AIGIs) of different qualities not only limited optimization capabilities for low-quality AIGIs but also brought negative optimization to high-quality AIGIs. To address this issue, a quality-award refiner named Q-Refine is proposed. Based on the preference of the Human Visual System (HVS), Q-Refine uses the Image Quality Assessment (IQA) metric to guide the refining process for the first time, and modify images of different qualities through three adaptive pipelines. Experimental shows that for mainstream T2I models, Q-Refine can perform effective optimization to AIGIs of different qualities. It can be a general refiner to optimize AIGIs from both fidelity and aesthetic quality levels, thus expanding the application of the T2I generation models.
Boosting Large Language Model for Speech Synthesis: An Empirical Study
Dec 30, 2023Large language models (LLMs) have made significant advancements in natural language processing and are concurrently extending the language ability to other modalities, such as speech and vision. Nevertheless, most of the previous work focuses on prompting LLMs with perception abilities like auditory comprehension, and the effective approach for augmenting LLMs with speech synthesis capabilities remains ambiguous. In this paper, we conduct a comprehensive empirical exploration of boosting LLMs with the ability to generate speech, by combining pre-trained LLM LLaMA/OPT and text-to-speech synthesis model VALL-E. We compare three integration methods between LLMs and speech synthesis models, including directly fine-tuned LLMs, superposed layers of LLMs and VALL-E, and coupled LLMs and VALL-E using LLMs as a powerful text encoder. Experimental results show that, using LoRA method to fine-tune LLMs directly to boost the speech synthesis capability does not work well, and superposed LLMs and VALL-E can improve the quality of generated speech both in speaker similarity and word error rate (WER). Among these three methods, coupled methods leveraging LLMs as the text encoder can achieve the best performance, making it outperform original speech synthesis models with a consistently better speaker similarity and a significant (10.9%) WER reduction.