 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Abstract to Contextual: What LLMs Still Cannot Do in Mathematics
Jan 30, 2026Large language models now solve many benchmark math problems at near-expert levels, yet this progress has not fully translated into reliable performance in real-world applications. We study this gap through contextual mathematical reasoning, where the mathematical core must be formulated from descriptive scenarios. We introduce ContextMATH, a benchmark that repurposes AIME and MATH-500 problems into two contextual settings: Scenario Grounding (SG), which embeds abstract problems into realistic narratives without increasing reasoning complexity, and Complexity Scaling (CS), which transforms explicit conditions into sub-problems to capture how constraints often appear in practice. Evaluating 61 proprietary and open-source models, we observe sharp drops: on average, open-source models decline by 13 and 34 points on SG and CS, while proprietary models drop by 13 and 20. Error analysis shows that errors are dominated by incorrect problem formulation, with formulation accuracy declining as original problem difficulty increases. Correct formulation emerges as a prerequisite for success, and its sufficiency improves with model scale, indicating that larger models advance in both understanding and reasoning. Nevertheless, formulation and reasoning remain two complementary bottlenecks that limit contextual mathematical problem solving. Finally, we find that fine-tuning with scenario data improves performance, whereas formulation-only training is ineffective. However, performance gaps are only partially alleviated, highlighting contextual mathematical reasoning as a central unsolved challenge for LLMs.
VERHallu: Evaluating and Mitigating Event Relation Hallucination in Video Large Language Models
Jan 15, 2026Video Large Language Models (VideoLLMs) exhibit various types of hallucinations. Existing research has primarily focused on hallucinations involving the presence of events, objects, and scenes in videos, while largely neglecting event relation hallucination. In this paper, we introduce a novel benchmark for evaluating the Video Event Relation Hallucination, named VERHallu. This benchmark focuses on causal, temporal, and subevent relations between events, encompassing three types of tasks: relation classification, question answering, and counterfactual question answering, for a comprehensive evaluation of event relation hallucination. Additionally, it features counterintuitive video scenarios that deviate from typical pretraining distributions, with each sample accompanied by human-annotated candidates covering both vision-language and pure language biases. Our analysis reveals that current state-of-the-art VideoLLMs struggle with dense-event relation reasoning, often relying on prior knowledge due to insufficient use of frame-level cues. Although these models demonstrate strong grounding capabilities for key events, they often overlook the surrounding subevents, leading to an incomplete and inaccurate understanding of event relations. To tackle this, we propose a Key-Frame Propagating (KFP) strategy, which reallocates frame-level attention within intermediate layers to enhance multi-event understanding. Experiments show it effectively mitigates the event relation hallucination without affecting inference speed.
Stephanie2: Thinking, Waiting, and Making Decisions Like Humans in Step-by-Step AI Social Chat
Jan 09, 2026Instant-messaging human social chat typically progresses through a sequence of short messages. Existing step-by-step AI chatting systems typically split a one-shot generation into multiple messages and send them sequentially, but they lack an active waiting mechanism and exhibit unnatural message pacing. In order to address these issues, we propose Stephanie2, a novel next-generation step-wise decision-making dialogue agent. With active waiting and message-pace adaptation, Stephanie2 explicitly decides at each step whether to send or wait, and models latency as the sum of thinking time and typing time to achieve more natural pacing. We further introduce a time-window-based dual-agent dialogue system to generate pseudo dialogue histories for human and automatic evaluations. Experiments show that Stephanie2 clearly outperforms Stephanie1 on metrics such as naturalness and engagement, and achieves a higher pass rate on human evaluation with the role identification Turing test.
LNE-Blocking: An Efficient Framework for Contamination Mitigation Evaluation on Large Language Models
Sep 18, 2025The problem of data contamination is now almost inevitable during the development of large language models (LLMs), with the training data commonly integrating those evaluation benchmarks even unintentionally. This problem subsequently makes it hard to benchmark LLMs fairly. Instead of constructing contamination-free datasets (quite hard), we propose a novel framework, \textbf{LNE-Blocking}, to restore model performance prior to contamination on potentially leaked datasets. Our framework consists of two components: contamination detection and disruption operation. For the prompt, the framework first uses the contamination detection method, \textbf{LNE}, to assess the extent of contamination in the model. Based on this, it adjusts the intensity of the disruption operation, \textbf{Blocking}, to elicit non-memorized responses from the model. Our framework is the first to efficiently restore the model's greedy decoding performance. This comes with a strong performance on multiple datasets with potential leakage risks, and it consistently achieves stable recovery results across different models and varying levels of data contamination. We release the code at https://github.com/RuijieH/LNE-Blocking to facilitate research.
Dictionary Insertion Prompting for Multilingual Reasoning on Multilingual Large Language Models
Nov 02, 2024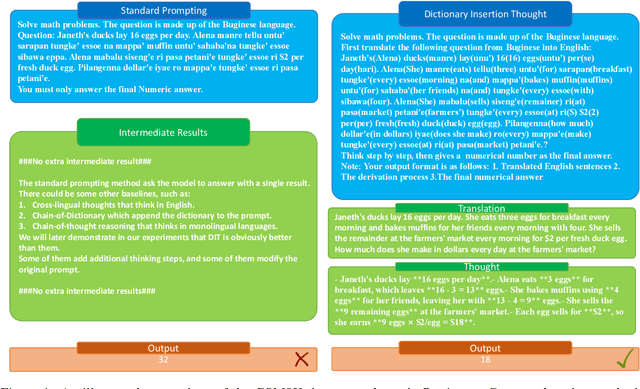
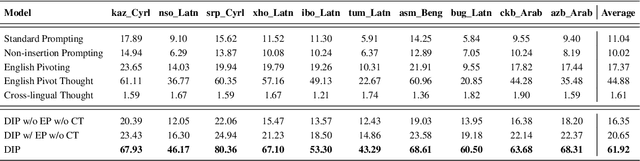
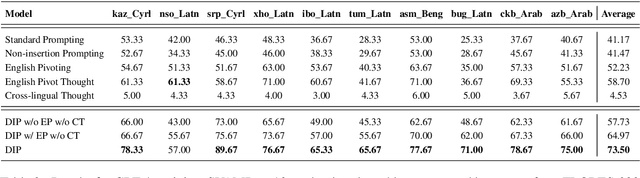
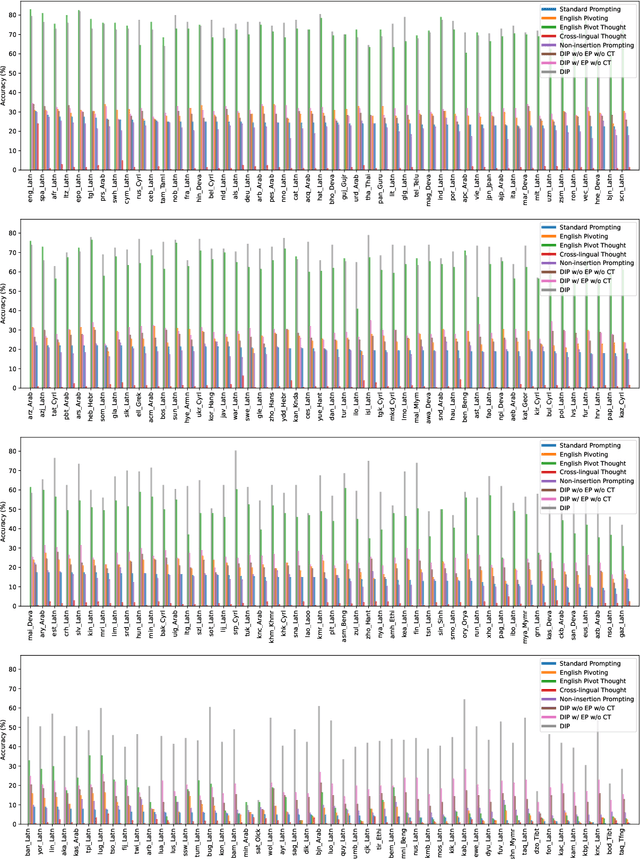
As current training data for Large Language Models (LLMs) are dominated by English corpus, they are English-centric and they present impressive performance on English reasoning tasks.\footnote{This paper primarily studies English-centric models, but our method could be universal by using the centric language in the dictionary for non-English-centric LLMs.} Yet, they usually suffer from lower performance in other languages. There are about 7,000 languages over the world, and many are low-resourced on English-centric LLMs. For the sake of people who primarily speak these languages, it is especially urgent to enable our LLMs in those languages. Model training is usually effective, but computationally expensive and requires experienced NLP practitioners. This paper presents a novel and simple yet effective method called \textbf{D}ictionary \textbf{I}nsertion \textbf{P}rompting (\textbf{DIP}). When providing a non-English prompt, DIP looks up a word dictionary and inserts words' English counterparts into the prompt for LLMs. It then enables better translation into English and better English model thinking steps which leads to obviously better results. We experiment with about 200 languages from FLORES-200. Since there are no adequate datasets, we use the NLLB translator to create synthetic multilingual benchmarks from the existing 4 English reasoning benchmarks such as GSM8K and AQuA. Despite the simplicity and computationally lightweight, we surprisingly found the effectiveness of DIP on math and commonsense reasoning tasks on multiple open-source and close-source LLMs.\footnote{Our dictionaries, code, and synthetic benchmarks will be open-sourced to facilitate future research.}
Clean Evaluations on Contaminated Visual Language Models
Oct 09, 2024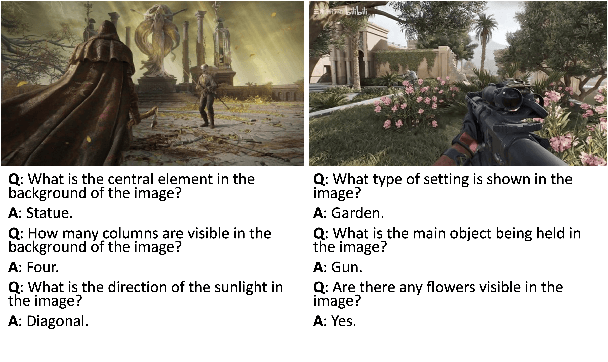
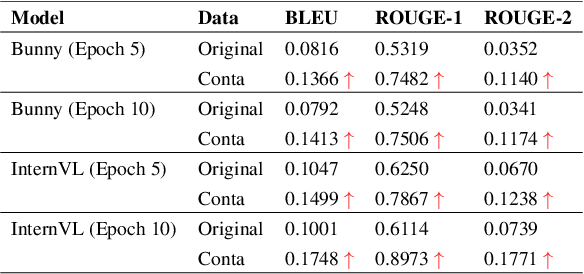
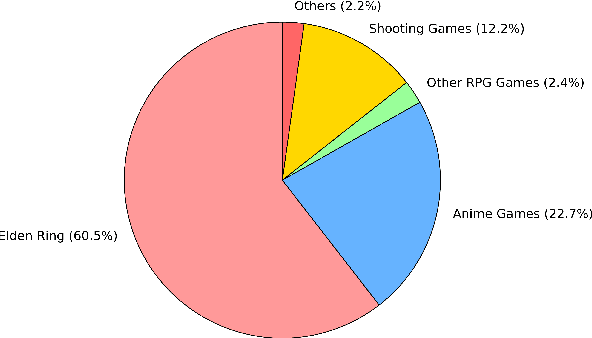
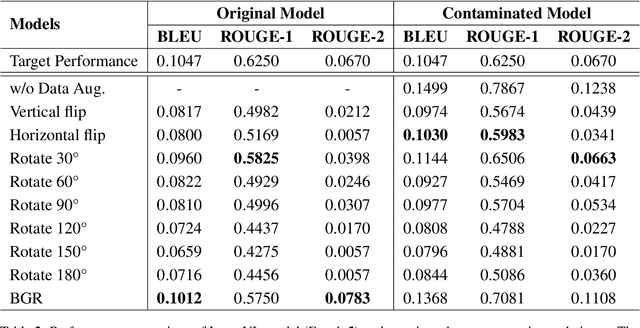
How to evaluate large language models (LLMs) cleanly has been established as an important research era to genuinely report the performance of possibly contaminated LLMs. Yet, how to cleanly evaluate the visual language models (VLMs) is an under-studied problem. We propose a novel approach to achieve such goals through data augmentation methods on the visual input information. We then craft a new visual clean evaluation benchmark with thousands of data instances. Through extensive experiments, we found that the traditional visual data augmentation methods are useful, but they are at risk of being used as a part of the training data as a workaround. We further propose using BGR augmentation to switch the colour channel of the visual information. We found that it is a simple yet effective method for reducing the effect of data contamination and fortunately, it is also harmful to be used as a data augmentation method during training. It means that it is hard to integrate such data augmentation into training by malicious trainers and it could be a promising technique to cleanly evaluate visual LLMs. Our code, data, and model weights will be released upon publication.
Toxic Subword Pruning for Dialogue Response Generation on Large Language Models
Oct 05, 2024



How to defend large language models (LLMs) from generating toxic content is an important research area. Yet, most research focused on various model training techniques to remediate LLMs by updating their weights. A typical related research area is safety alignment. This however is often costly and tedious and can expose the model to even more problems such as catastrophic forgetting if the trainings are not carefully handled by experienced NLP practitioners. We thus propose a simple yet effective and novel algorithm, namely \textbf{Tox}ic Subword \textbf{Prun}ing (ToxPrune) to prune the subword contained by the toxic words from BPE in trained LLMs. In contrast to the previous work that demonstrates pruning BPE tokens as harmful to the task of machine translation, we surprisingly found its usefulness in preventing toxic content from being generated on LLMs. Fortunately, our findings suggest that ToxPrune simultaneously improves the toxic language model NSFW-3B on the task of dialogue response generation obviously. We surprisingly found that ToxPrune can even obviously improve official Llama-3.1-6B in the metric of dialogue diversity. Extensive automatic results and human evaluation indicate that ToxPrune could be helpful for both remediating toxic LLMs and improving non-toxic LLMs on the task of dialogue response generation.\footnote{We plan to release the resources to facilitate future work.}
Stephanie: Step-by-Step Dialogues for Mimicking Human Interactions in Social Conversations
Jul 04, 2024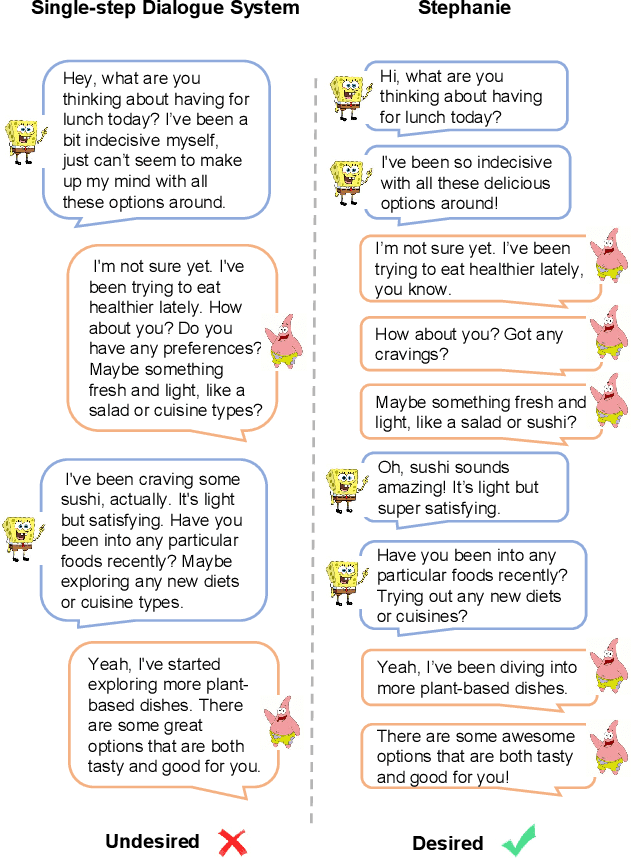
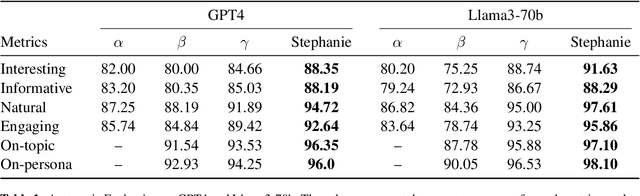
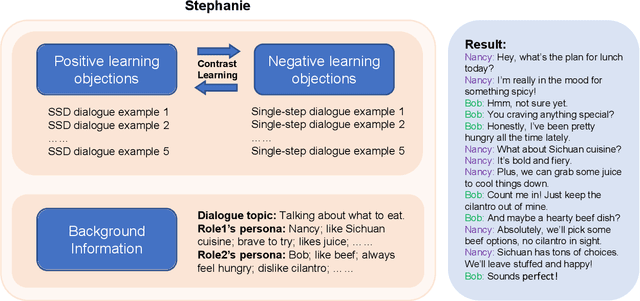
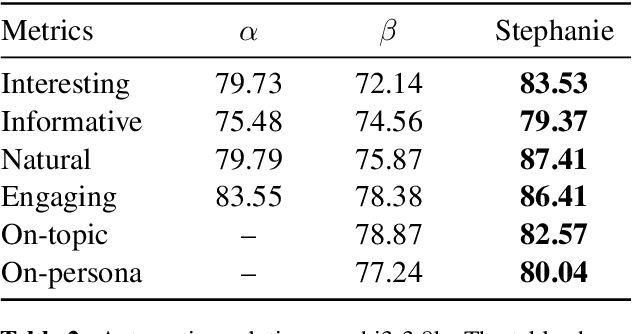
In the rapidly evolving field of natural language processing, dialogue systems primarily employ a single-step dialogue paradigm. Although this paradigm is efficient, it lacks the depth and fluidity of human interactions and does not appear natural. We introduce a novel \textbf{Step}-by-Step Dialogue Paradigm (Stephanie), designed to mimic the ongoing dynamic nature of human conversations. By employing a dual learning strategy and a further-split post-editing method, we generated and utilized a high-quality step-by-step dialogue dataset to fine-tune existing large language models, enabling them to perform step-by-step dialogues. We thoroughly present Stephanie. Tailored automatic and human evaluations are conducted to assess its effectiveness compared to the traditional single-step dialogue paradigm. We will release code, Stephanie datasets, and Stephanie LLMs to facilitate the future of chatbot eras.
Unveiling the Generalization Power of Fine-Tuned Large Language Models
Mar 14, 2024
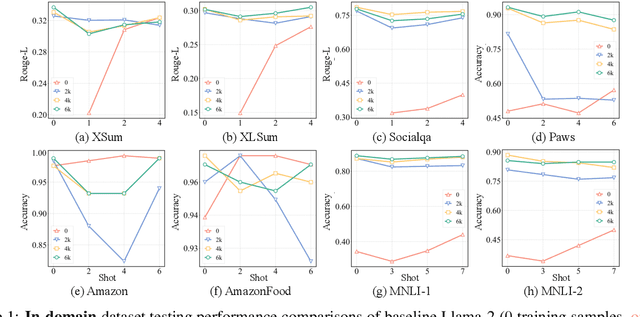
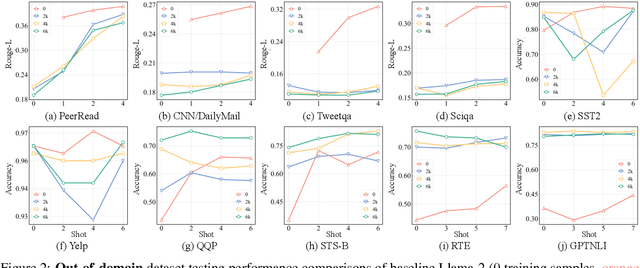
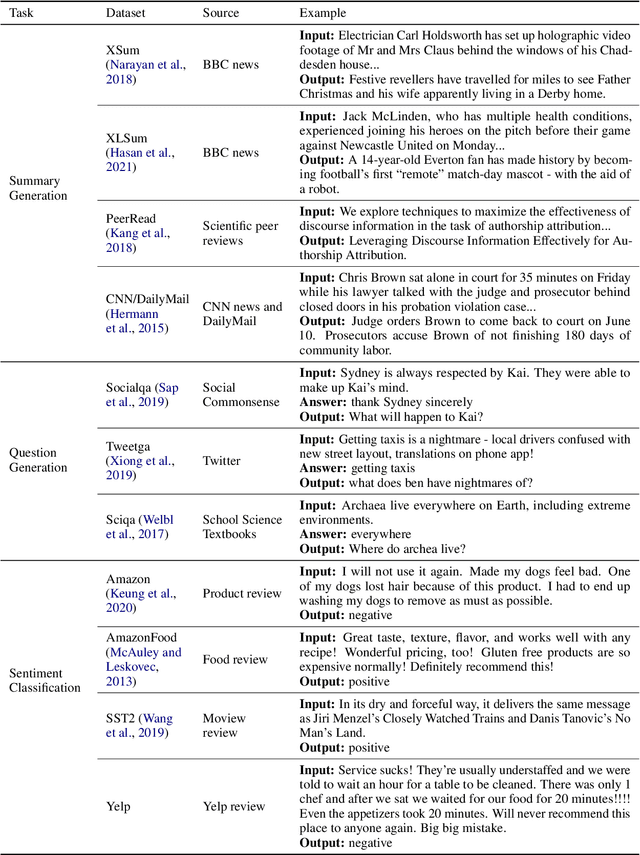
While Large Language Models (LLMs) have demonstrated exceptional multitasking abilities, fine-tuning these models on downstream, domain-specific datasets is often necessary to yield superior performance on test sets compared to their counterparts without fine-tuning. However, the comprehensive effects of fine-tuning on the LLMs' generalization ability are not fully understood. This paper delves into the differences between original, unmodified LLMs and their fine-tuned variants. Our primary investigation centers on whether fine-tuning affects the generalization ability intrinsic to LLMs. To elaborate on this, we conduct extensive experiments across five distinct language tasks on various datasets. Our main findings reveal that models fine-tuned on generation and classification tasks exhibit dissimilar behaviors in generalizing to different domains and tasks. Intriguingly, we observe that integrating the in-context learning strategy during fine-tuning on generation tasks can enhance the model's generalization ability. Through this systematic investigation, we aim to contribute valuable insights into the evolving landscape of fine-tuning practices for LLMs.
Consecutive Model Editing with Batch alongside HooK Layers
Mar 08, 2024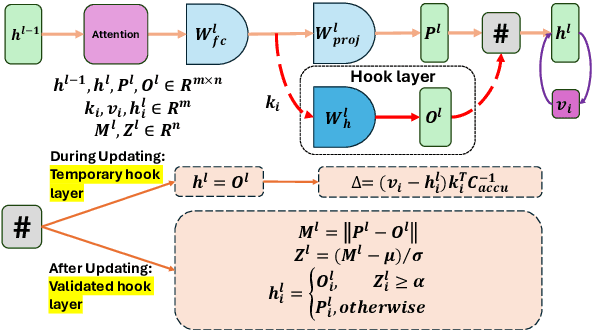



As the typical retraining paradigm is unacceptably time- and resource-consuming, researchers are turning to model editing in order to seek an effective, consecutive, and batch-supportive way to edit the model behavior directly. Despite all these practical expectations, existing model editing methods fail to realize all of them. Furthermore, the memory demands for such succession-supportive model editing approaches tend to be prohibitive, frequently necessitating an external memory that grows incrementally over time. To cope with these challenges, we propose COMEBA-HK, a model editing method that is both consecutive and batch-supportive. COMEBA-HK is memory-friendly as it only needs a small amount of it to store several hook layers with updated weights. Experimental results demonstrate the superiority of our method over other batch-supportive model editing methods under both single-round and consecutive batch editing scenarios. Extensive analyses of COMEBA-HK have been conducted to verify the stability of our method over 1) the number of consecutive steps and 2) the number of editing instance.