 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStephanie2: Thinking, Waiting, and Making Decisions Like Humans in Step-by-Step AI Social Chat
Jan 09, 2026Instant-messaging human social chat typically progresses through a sequence of short messages. Existing step-by-step AI chatting systems typically split a one-shot generation into multiple messages and send them sequentially, but they lack an active waiting mechanism and exhibit unnatural message pacing. In order to address these issues, we propose Stephanie2, a novel next-generation step-wise decision-making dialogue agent. With active waiting and message-pace adaptation, Stephanie2 explicitly decides at each step whether to send or wait, and models latency as the sum of thinking time and typing time to achieve more natural pacing. We further introduce a time-window-based dual-agent dialogue system to generate pseudo dialogue histories for human and automatic evaluations. Experiments show that Stephanie2 clearly outperforms Stephanie1 on metrics such as naturalness and engagement, and achieves a higher pass rate on human evaluation with the role identification Turing test.
Cross-channel Perception Learning for H&E-to-IHC Virtual Staining
Jun 09, 2025



With the rapid development of digital pathology, virtual staining has become a key technology in multimedia medical information systems, offering new possibilities for the analysis and diagnosis of pathological images. However, existing H&E-to-IHC studies often overlook the cross-channel correlations between cell nuclei and cell membranes. To address this issue, we propose a novel Cross-Channel Perception Learning (CCPL) strategy. Specifically, CCPL first decomposes HER2 immunohistochemical staining into Hematoxylin and DAB staining channels, corresponding to cell nuclei and cell membranes, respectively. Using the pathology foundation model Gigapath's Tile Encoder, CCPL extracts dual-channel features from both the generated and real images and measures cross-channel correlations between nuclei and membranes. The features of the generated and real stained images, obtained through the Tile Encoder, are also used to calculate feature distillation loss, enhancing the model's feature extraction capabilities without increasing the inference burden. Additionally, CCPL performs statistical analysis on the focal optical density maps of both single channels to ensure consistency in staining distribution and intensity. Experimental results, based on quantitative metrics such as PSNR, SSIM, PCC, and FID, along with professional evaluations from pathologists, demonstrate that CCPL effectively preserves pathological features, generates high-quality virtual stained images, and provides robust support for automated pathological diagnosis using multimedia medical data.
PathVLM-R1: A Reinforcement Learning-Driven Reasoning Model for Pathology Visual-Language Tasks
Apr 12, 2025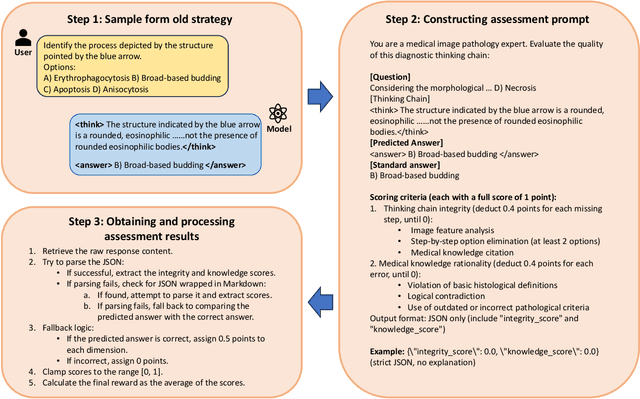
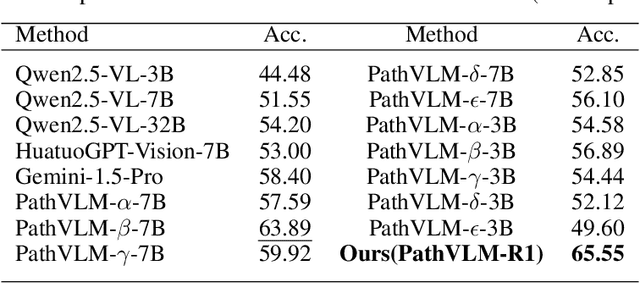
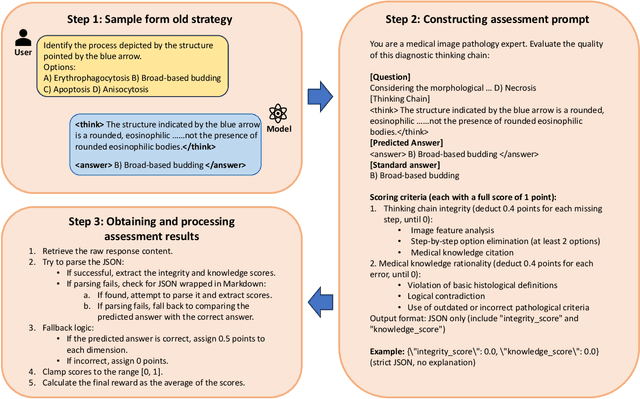

The diagnosis of pathological images is often limited by expert availability and regional disparities, highlighting the importance of automated diagnosis using Vision-Language Models (VLMs). Traditional multimodal models typically emphasize outcomes over the reasoning process, compromising the reliability of clinical decisions. To address the weak reasoning abilities and lack of supervised processes in pathological VLMs, we have innovatively proposed PathVLM-R1, a visual language model designed specifically for pathological images. We have based our model on Qwen2.5-VL-7B-Instruct and enhanced its performance for pathological tasks through meticulously designed post-training strategies. Firstly, we conduct supervised fine-tuning guided by pathological data to imbue the model with foundational pathological knowledge, forming a new pathological base model. Subsequently, we introduce Group Relative Policy Optimization (GRPO) and propose a dual reward-driven reinforcement learning optimization, ensuring strict constraint on logical supervision of the reasoning process and accuracy of results via cross-modal process reward and outcome accuracy reward. In the pathological image question-answering tasks, the testing results of PathVLM-R1 demonstrate a 14% improvement in accuracy compared to baseline methods, and it demonstrated superior performance compared to the Qwen2.5-VL-32B version despite having a significantly smaller parameter size. Furthermore, in out-domain data evaluation involving four medical imaging modalities: Computed Tomography (CT), dermoscopy, fundus photography, and Optical Coherence Tomography (OCT) images: PathVLM-R1's transfer performance improved by an average of 17.3% compared to traditional SFT methods. These results clearly indicate that PathVLM-R1 not only enhances accuracy but also possesses broad applicability and expansion potential.
STNMamba: Mamba-based Spatial-Temporal Normality Learning for Video Anomaly Detection
Dec 28, 2024Video anomaly detection (VAD) has been extensively researched due to its potential for intelligent video systems. However, most existing methods based on CNNs and transformers still suffer from substantial computational burdens and have room for improvement in learning spatial-temporal normality. Recently, Mamba has shown great potential for modeling long-range dependencies with linear complexity, providing an effective solution to the above dilemma. To this end, we propose a lightweight and effective Mamba-based network named STNMamba, which incorporates carefully designed Mamba modules to enhance the learning of spatial-temporal normality. Firstly, we develop a dual-encoder architecture, where the spatial encoder equipped with Multi-Scale Vision Space State Blocks (MS-VSSB) extracts multi-scale appearance features, and the temporal encoder employs Channel-Aware Vision Space State Blocks (CA-VSSB) to capture significant motion patterns. Secondly, a Spatial-Temporal Interaction Module (STIM) is introduced to integrate spatial and temporal information across multiple levels, enabling effective modeling of intrinsic spatial-temporal consistency. Within this module, the Spatial-Temporal Fusion Block (STFB) is proposed to fuse the spatial and temporal features into a unified feature space, and the memory bank is utilized to store spatial-temporal prototypes of normal patterns, restricting the model's ability to represent anomalies. Extensive experiments on three benchmark datasets demonstrate that our STNMamba achieves competitive performance with fewer parameters and lower computational costs than existing methods.
Stephanie: Step-by-Step Dialogues for Mimicking Human Interactions in Social Conversations
Jul 04, 2024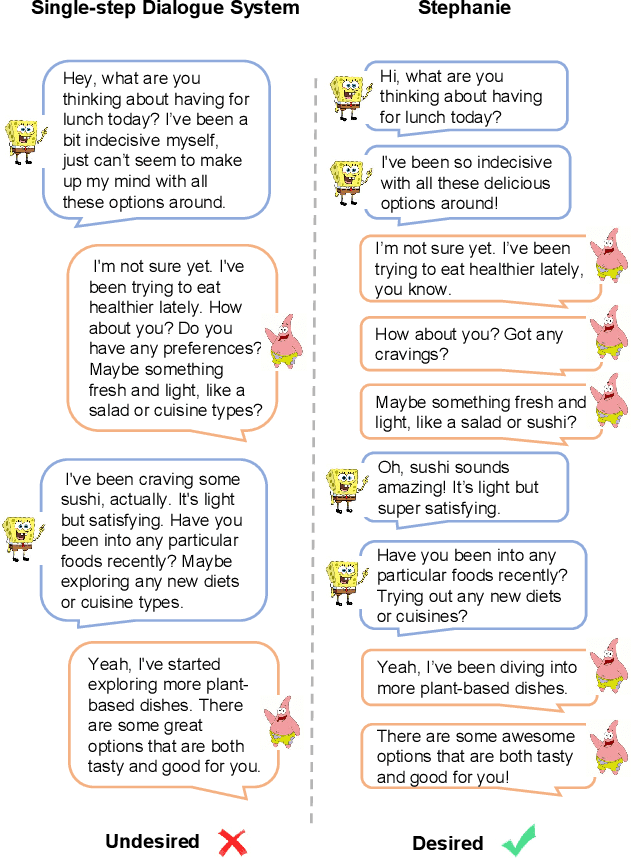
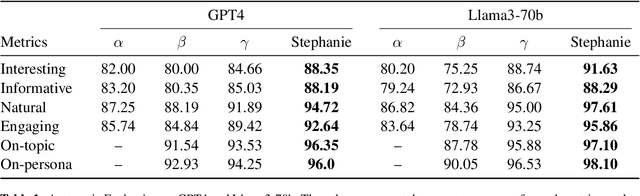
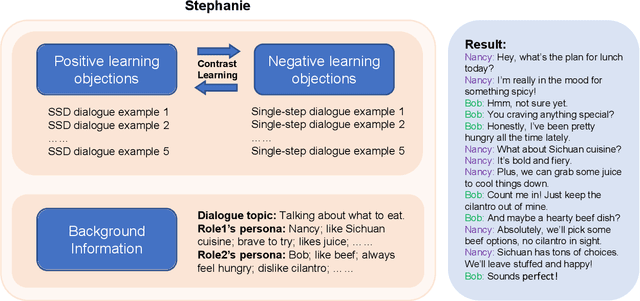
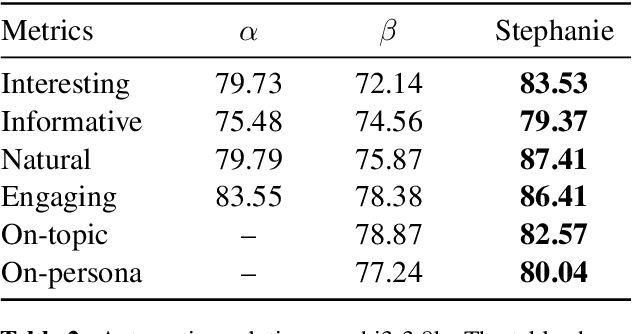
In the rapidly evolving field of natural language processing, dialogue systems primarily employ a single-step dialogue paradigm. Although this paradigm is efficient, it lacks the depth and fluidity of human interactions and does not appear natural. We introduce a novel \textbf{Step}-by-Step Dialogue Paradigm (Stephanie), designed to mimic the ongoing dynamic nature of human conversations. By employing a dual learning strategy and a further-split post-editing method, we generated and utilized a high-quality step-by-step dialogue dataset to fine-tune existing large language models, enabling them to perform step-by-step dialogues. We thoroughly present Stephanie. Tailored automatic and human evaluations are conducted to assess its effectiveness compared to the traditional single-step dialogue paradigm. We will release code, Stephanie datasets, and Stephanie LLMs to facilitate the future of chatbot eras.
Configurable Spatial-Temporal Hierarchical Analysis for Flexible Video Anomaly Detection
May 12, 2023



Video anomaly detection (VAD) is a vital task with great practical applications in industrial surveillance, security system, and traffic control. Unlike previous unsupervised VAD methods that adopt a fixed structure to learn normality without considering different detection demands, we design a spatial-temporal hierarchical architecture (STHA) as a configurable architecture to flexibly detect different degrees of anomaly. The comprehensive structure of the STHA is delineated into a tripartite hierarchy, encompassing the following tiers: the stream level, the stack level, and the block level. Specifically, we design several auto-encoder-based blocks that possess varying capacities for extracting normal patterns. Then, we stack blocks according to the complexity degrees with both intra-stack and inter-stack residual links to learn hierarchical normality gradually. Considering the multisource knowledge of videos, we also model the spatial normality of video frames and temporal normality of RGB difference by designing two parallel streams consisting of stacks. Thus, STHA can provide various representation learning abilities by expanding or contracting hierarchically to detect anomalies of different degrees. Since the anomaly set is complicated and unbounded, our STHA can adjust its detection ability to adapt to the human detection demands and the complexity degree of anomaly that happened in the history of a scene. We conduct experiments on three benchmarks and perform extensive analysis, and the results demonstrate that our method performs comparablely to the state-of-the-art methods. In addition, we design a toy dataset to prove that our model can better balance the learning ability to adapt to different detection demands.
LGN-Net: Local-Global Normality Network for Video Anomaly Detection
Nov 21, 2022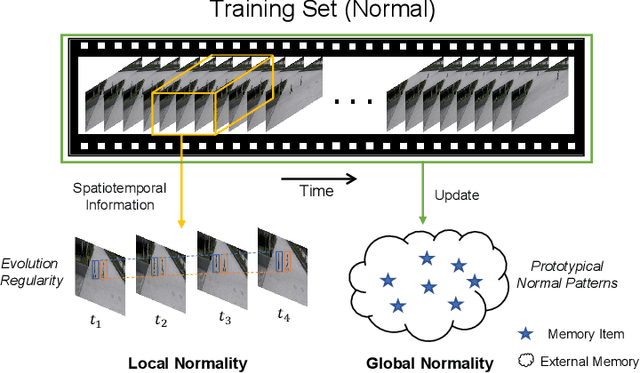
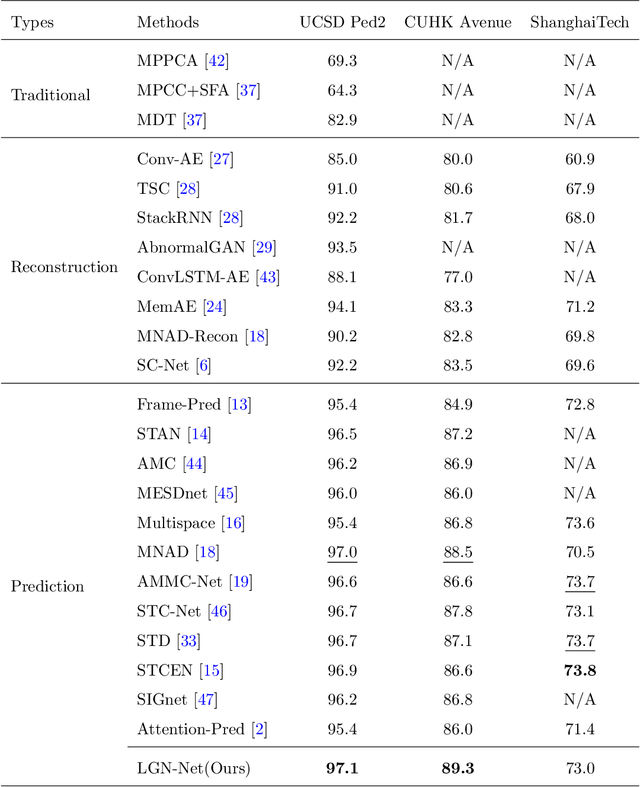
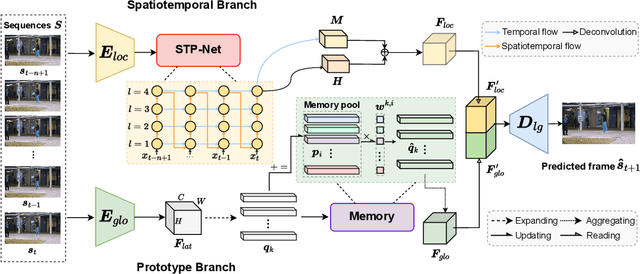
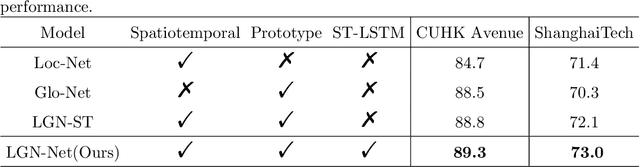
Video anomaly detection (VAD) has been intensively studied for years because of its potential applications in intelligent video systems. Existing unsupervised VAD methods tend to learn normality from training sets consisting of only normal videos and regard instances deviating from such normality as anomalies. However, they often consider only local or global normality. Some of them focus on learning local spatiotemporal representations from consecutive frames in video clips to enhance the representation for normal events. But powerful representation allows these methods to represent some anomalies and causes missed detections. In contrast, the other methods are devoted to memorizing global prototypical patterns of whole training videos to weaken the generalization for anomalies, which also restricts them to represent diverse normal patterns and causes false alarms. To this end, we propose a two-branch model, Local-Global Normality Network (LGN-Net), to learn local and global normality simultaneously. Specifically, one branch learns the evolution regularities of appearance and motion from consecutive frames as local normality utilizing a spatiotemporal prediction network, while the other branch memorizes prototype features of the whole videos as global normality by a memory module. LGN-Net achieves a balance of representing normal and abnormal instances by fusing local and global normality. The fused normality enables our model more generalized to various scenes compared to exploiting single normality. Experiments demonstrate the effectiveness and superior performance of our method. The code is available online: https://github.com/Myzhao1999/LGN-Net.
Exploiting Spatial-temporal Correlations for Video Anomaly Detection
Nov 02, 2022Video anomaly detection (VAD) remains a challenging task in the pattern recognition community due to the ambiguity and diversity of abnormal events. Existing deep learning-based VAD methods usually leverage proxy tasks to learn the normal patterns and discriminate the instances that deviate from such patterns as abnormal. However, most of them do not take full advantage of spatial-temporal correlations among video frames, which is critical for understanding normal patterns. In this paper, we address unsupervised VAD by learning the evolution regularity of appearance and motion in the long and short-term and exploit the spatial-temporal correlations among consecutive frames in normal videos more adequately. Specifically, we proposed to utilize the spatiotemporal long short-term memory (ST-LSTM) to extract and memorize spatial appearances and temporal variations in a unified memory cell. In addition, inspired by the generative adversarial network, we introduce a discriminator to perform adversarial learning with the ST-LSTM to enhance the learning capability. Experimental results on standard benchmarks demonstrate the effectiveness of spatial-temporal correlations for unsupervised VAD. Our method achieves competitive performance compared to the state-of-the-art methods with AUCs of 96.7%, 87.8%, and 73.1% on the UCSD Ped2, CUHK Avenue, and ShanghaiTech, respectively.