 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTNMamba: Mamba-based Spatial-Temporal Normality Learning for Video Anomaly Detection
Dec 28, 2024Video anomaly detection (VAD) has been extensively researched due to its potential for intelligent video systems. However, most existing methods based on CNNs and transformers still suffer from substantial computational burdens and have room for improvement in learning spatial-temporal normality. Recently, Mamba has shown great potential for modeling long-range dependencies with linear complexity, providing an effective solution to the above dilemma. To this end, we propose a lightweight and effective Mamba-based network named STNMamba, which incorporates carefully designed Mamba modules to enhance the learning of spatial-temporal normality. Firstly, we develop a dual-encoder architecture, where the spatial encoder equipped with Multi-Scale Vision Space State Blocks (MS-VSSB) extracts multi-scale appearance features, and the temporal encoder employs Channel-Aware Vision Space State Blocks (CA-VSSB) to capture significant motion patterns. Secondly, a Spatial-Temporal Interaction Module (STIM) is introduced to integrate spatial and temporal information across multiple levels, enabling effective modeling of intrinsic spatial-temporal consistency. Within this module, the Spatial-Temporal Fusion Block (STFB) is proposed to fuse the spatial and temporal features into a unified feature space, and the memory bank is utilized to store spatial-temporal prototypes of normal patterns, restricting the model's ability to represent anomalies. Extensive experiments on three benchmark datasets demonstrate that our STNMamba achieves competitive performance with fewer parameters and lower computational costs than existing methods.
DualMamba: A Lightweight Spectral-Spatial Mamba-Convolution Network for Hyperspectral Image Classification
Jun 11, 2024
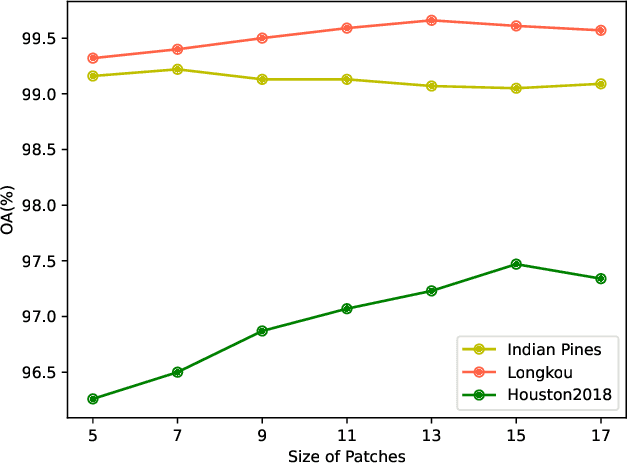
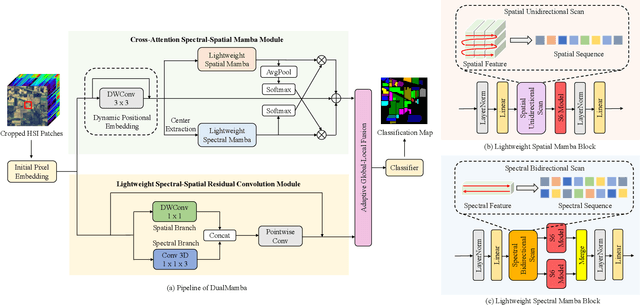
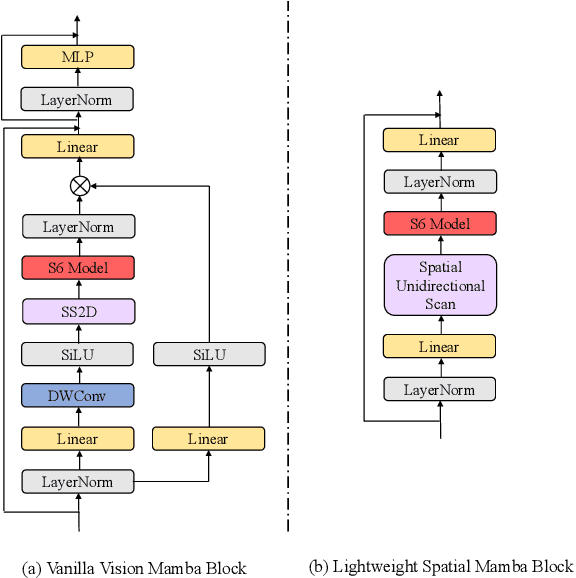
The effectiveness and efficiency of modeling complex spectral-spatial relations are both crucial for Hyperspectral image (HSI) classification. Most existing methods based on CNNs and transformers still suffer from heavy computational burdens and have room for improvement in capturing the global-local spectral-spatial feature representation. To this end, we propose a novel lightweight parallel design called lightweight dual-stream Mamba-convolution network (DualMamba) for HSI classification. Specifically, a parallel lightweight Mamba and CNN block are first developed to extract global and local spectral-spatial features. First, the cross-attention spectral-spatial Mamba module is proposed to leverage the global modeling of Mamba at linear complexity. Within this module, dynamic positional embedding is designed to enhance the spatial location information of visual sequences. The lightweight spectral/spatial Mamba blocks comprise an efficient scanning strategy and a lightweight Mamba design to efficiently extract global spectral-spatial features. And the cross-attention spectral-spatial fusion is designed to learn cross-correlation and fuse spectral-spatial features. Second, the lightweight spectral-spatial residual convolution module is proposed with lightweight spectral and spatial branches to extract local spectral-spatial features through residual learning. Finally, the adaptive global-local fusion is proposed to dynamically combine global Mamba features and local convolution features for a global-local spectral-spatial representation. Compared with state-of-the-art HSI classification methods, experimental results demonstrate that DualMamba achieves significant classification accuracy on three public HSI datasets and a superior reduction in model parameters and floating point operations (FLOPs).
MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies
Mar 03, 2024
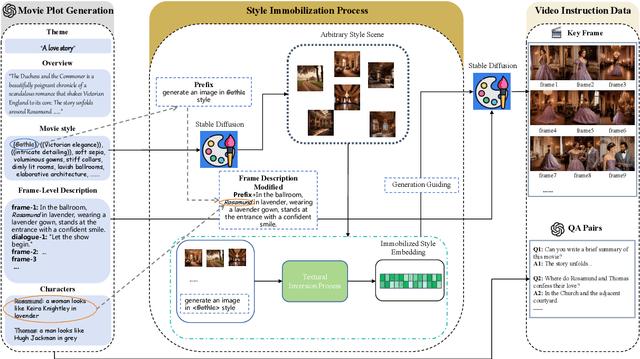
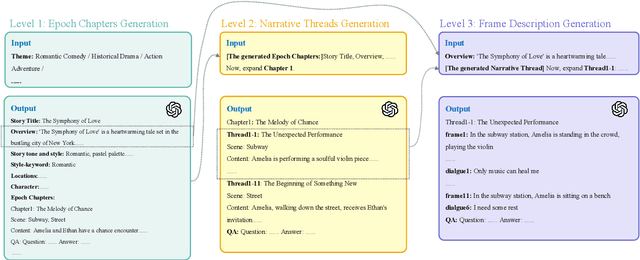
The development of multimodal models has marked a significant step forward in how machines understand videos. These models have shown promise in analyzing short video clips. However, when it comes to longer formats like movies, they often fall short. The main hurdles are the lack of high-quality, diverse video data and the intensive work required to collect or annotate such data. In the face of these challenges, we propose MovieLLM, a novel framework designed to create synthetic, high-quality data for long videos. This framework leverages the power of GPT-4 and text-to-image models to generate detailed scripts and corresponding visuals. Our approach stands out for its flexibility and scalability, making it a superior alternative to traditional data collection methods. Our extensive experiments validate that the data produced by MovieLLM significantly improves the performance of multimodal models in understanding complex video narratives, overcoming the limitations of existing datasets regarding scarcity and bias.
When Hyperspectral Image Classification Meets Diffusion Models: An Unsupervised Feature Learning Framework
Jun 15, 2023



Learning effective spectral-spatial features is important for the hyperspectral image (HSI) classification task, but the majority of existing HSI classification methods still suffer from modeling complex spectral-spatial relations and characterizing low-level details and high-level semantics comprehensively. As a new class of record-breaking generative models, diffusion models are capable of modeling complex relations for understanding inputs well as learning both high-level and low-level visual features. Meanwhile, diffusion models can capture more abundant features by taking advantage of the extra and unique dimension of timestep t. In view of these, we propose an unsupervised spectral-spatial feature learning framework based on the diffusion model for HSI classification for the first time, named Diff-HSI. Specifically, we first pretrain the diffusion model with unlabeled HSI patches for unsupervised feature learning, and then exploit intermediate hierarchical features from different timesteps for classification. For better using the abundant timestep-wise features, we design a timestep-wise feature bank and a dynamic feature fusion module to construct timestep-wise features, adaptively learning informative multi-timestep representations. Finally, an ensemble of linear classifiers is applied to perform HSI classification. Extensive experiments are conducted on three public HSI datasets, and our results demonstrate that Diff-HSI outperforms state-of-the-art supervised and unsupervised methods for HSI classification.
JNDMix: JND-Based Data Augmentation for No-reference Image Quality Assessment
Feb 20, 2023



Despite substantial progress in no-reference image quality assessment (NR-IQA), previous training models often suffer from over-fitting due to the limited scale of used datasets, resulting in model performance bottlenecks. To tackle this challenge, we explore the potential of leveraging data augmentation to improve data efficiency and enhance model robustness. However, most existing data augmentation methods incur a serious issue, namely that it alters the image quality and leads to training images mismatching with their original labels. Additionally, although only a few data augmentation methods are available for NR-IQA task, their ability to enrich dataset diversity is still insufficient. To address these issues, we propose a effective and general data augmentation based on just noticeable difference (JND) noise mixing for NR-IQA task, named JNDMix. In detail, we randomly inject the JND noise, imperceptible to the human visual system (HVS), into the training image without any adjustment to its label. Extensive experiments demonstrate that JNDMix significantly improves the performance and data efficiency of various state-of-the-art NR-IQA models and the commonly used baseline models, as well as the generalization ability. More importantly, JNDMix facilitates MANIQA to achieve the state-of-the-art performance on LIVEC and KonIQ-10k.