 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLG-Stereo: ViT Based Stereo Matching with Multi-Stage Local-Global Enhancement
Apr 22, 2026With the development of deep learning, ViT-based stereo matching methods have made significant progress due to their remarkable robustness and zero-shot ability. However, due to the limitations of ViTs in handling resolution sensitivity and their relative neglect of local information, the ability of ViT-based methods to predict details and handle arbitrary-resolution images is still weaker than that of CNN-based methods. To address these shortcomings, we propose MLG-Stereo, a systematic pipeline-level design that extends global modeling beyond the encoder stage. First, we propose a Multi-Granularity Feature Network to effectively balance global context and local geometric information, enabling comprehensive feature extraction from images of arbitrary resolution and bridging the gap between training and inference scales. Then, a Local-Global Cost Volume is constructed to capture both locally-correlated and global-aware matching information. Finally, a Local-Global Guided Recurrent Unit is introduced to iteratively optimize the disparity locally under the guidance of global information. Extensive experiments are conducted on multiple benchmark datasets, demonstrating that our MLG-Stereo exhibits highly competitive performance on the Middlebury and KITTI-2015 benchmarks compared to contemporaneous leading methods, and achieves outstanding results in the KITTI-2012 dataset.
Consistency-aware Self-Training for Iterative-based Stereo Matching
Mar 31, 2025Iterative-based methods have become mainstream in stereo matching due to their high performance. However, these methods heavily rely on labeled data and face challenges with unlabeled real-world data. To this end, we propose a consistency-aware self-training framework for iterative-based stereo matching for the first time, leveraging real-world unlabeled data in a teacher-student manner. We first observe that regions with larger errors tend to exhibit more pronounced oscillation characteristics during model prediction.Based on this, we introduce a novel consistency-aware soft filtering module to evaluate the reliability of teacher-predicted pseudo-labels, which consists of a multi-resolution prediction consistency filter and an iterative prediction consistency filter to assess the prediction fluctuations of multiple resolutions and iterative optimization respectively. Further, we introduce a consistency-aware soft-weighted loss to adjust the weight of pseudo-labels accordingly, relieving the error accumulation and performance degradation problem due to incorrect pseudo-labels. Extensive experiments demonstrate that our method can improve the performance of various iterative-based stereo matching approaches in various scenarios. In particular, our method can achieve further enhancements over the current SOTA methods on several benchmark datasets.
All-in-One: Transferring Vision Foundation Models into Stereo Matching
Dec 13, 2024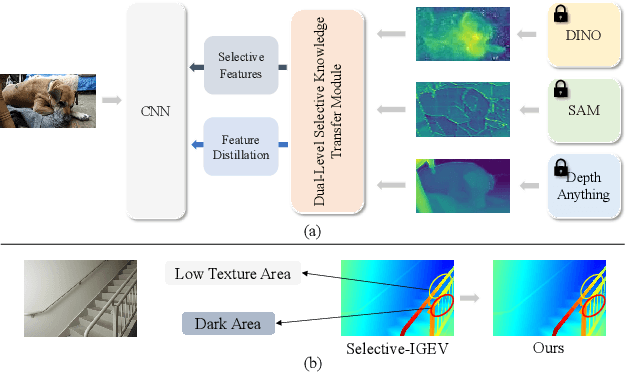

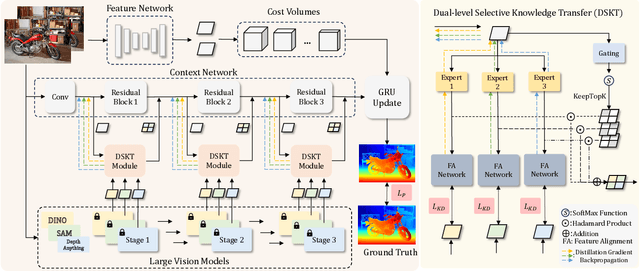
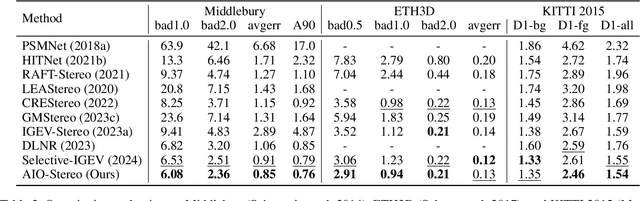
As a fundamental vision task, stereo matching has made remarkable progress. While recent iterative optimization-based methods have achieved promising performance, their feature extraction capabilities still have room for improvement. Inspired by the ability of vision foundation models (VFMs) to extract general representations, in this work, we propose AIO-Stereo which can flexibly select and transfer knowledge from multiple heterogeneous VFMs to a single stereo matching model. To better reconcile features between heterogeneous VFMs and the stereo matching model and fully exploit prior knowledge from VFMs, we proposed a dual-level feature utilization mechanism that aligns heterogeneous features and transfers multi-level knowledge. Based on the mechanism, a dual-level selective knowledge transfer module is designed to selectively transfer knowledge and integrate the advantages of multiple VFMs. Experimental results show that AIO-Stereo achieves start-of-the-art performance on multiple datasets and ranks $1^{st}$ on the Middlebury dataset and outperforms all the published work on the ETH3D benchmark.
A Chinese Multi-label Affective Computing Dataset Based on Social Media Network Users
Nov 13, 2024



Emotion and personality are central elements in understanding human psychological states. Emotions reflect an individual subjective experiences, while personality reveals relatively stable behavioral and cognitive patterns. Existing affective computing datasets often annotate emotion and personality traits separately, lacking fine-grained labeling of micro-emotions and emotion intensity in both single-label and multi-label classifications. Chinese emotion datasets are extremely scarce, and datasets capturing Chinese user personality traits are even more limited. To address these gaps, this study collected data from the major social media platform Weibo, screening 11,338 valid users from over 50,000 individuals with diverse MBTI personality labels and acquiring 566,900 posts along with the user MBTI personality tags. Using the EQN method, we compiled a multi-label Chinese affective computing dataset that integrates the same user's personality traits with six emotions and micro-emotions, each annotated with intensity levels. Validation results across multiple NLP classification models demonstrate the dataset strong utility. This dataset is designed to advance machine recognition of complex human emotions and provide data support for research in psychology, education, marketing, finance, and politics.
Expansion Quantization Network: An Efficient Micro-emotion Annotation and Detection Framework
Nov 09, 2024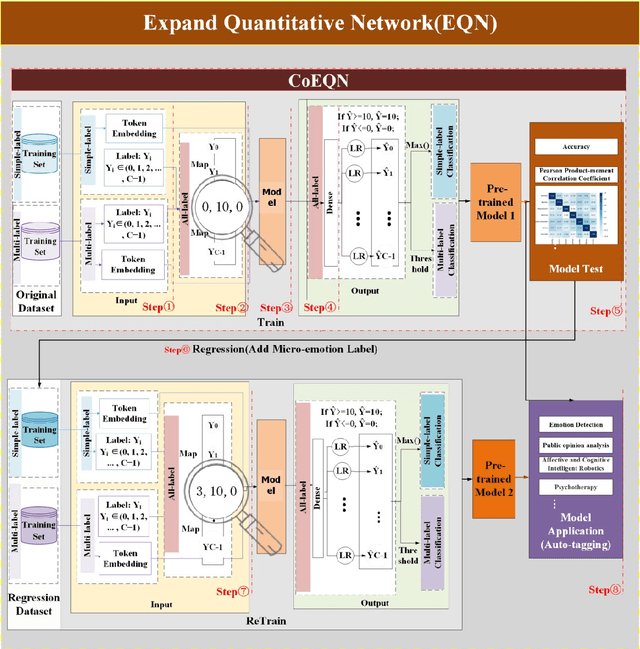

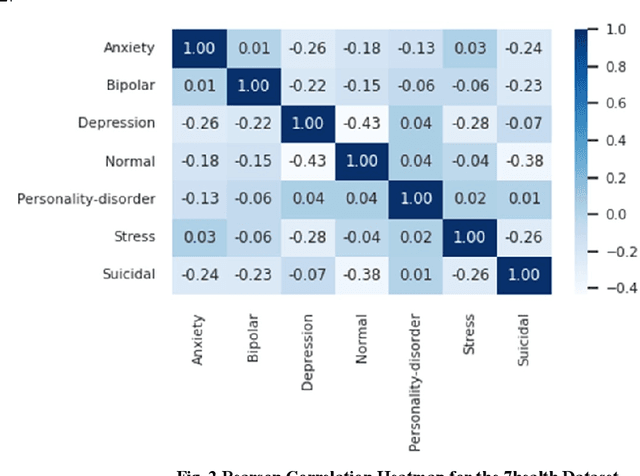
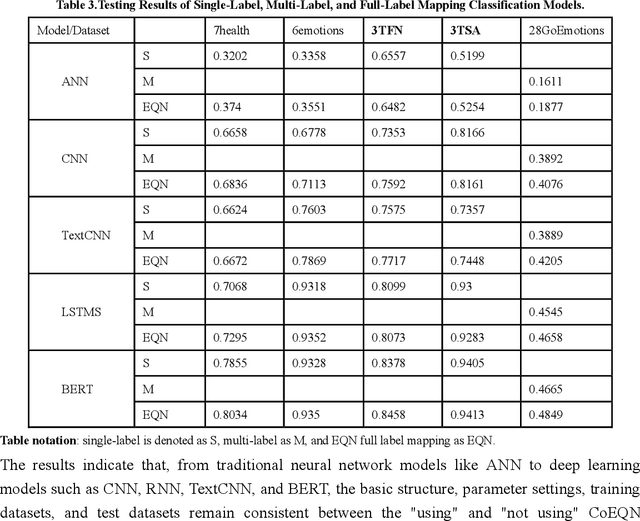
Text emotion detection constitutes a crucial foundation for advancing artificial intelligence from basic comprehension to the exploration of emotional reasoning. Most existing emotion detection datasets rely on manual annotations, which are associated with high costs, substantial subjectivity, and severe label imbalances. This is particularly evident in the inadequate annotation of micro-emotions and the absence of emotional intensity representation, which fail to capture the rich emotions embedded in sentences and adversely affect the quality of downstream task completion. By proposing an all-labels and training-set label regression method, we map label values to energy intensity levels, thereby fully leveraging the learning capabilities of machine models and the interdependencies among labels to uncover multiple emotions within samples. This led to the establishment of the Emotion Quantization Network (EQN) framework for micro-emotion detection and annotation. Using five commonly employed sentiment datasets, we conducted comparative experiments with various models, validating the broad applicability of our framework within NLP machine learning models. Based on the EQN framework, emotion detection and annotation are conducted on the GoEmotions dataset. A comprehensive comparison with the results from Google literature demonstrates that the EQN framework possesses a high capability for automatic detection and annotation of micro-emotions. The EQN framework is the first to achieve automatic micro-emotion annotation with energy-level scores, providing strong support for further emotion detection analysis and the quantitative research of emotion computing.
DualMamba: A Lightweight Spectral-Spatial Mamba-Convolution Network for Hyperspectral Image Classification
Jun 11, 2024
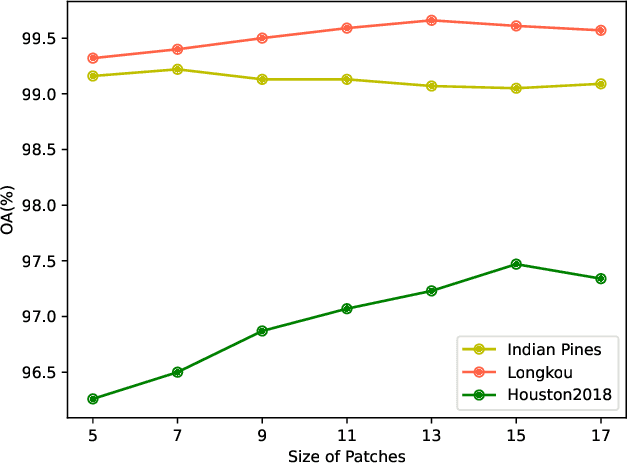
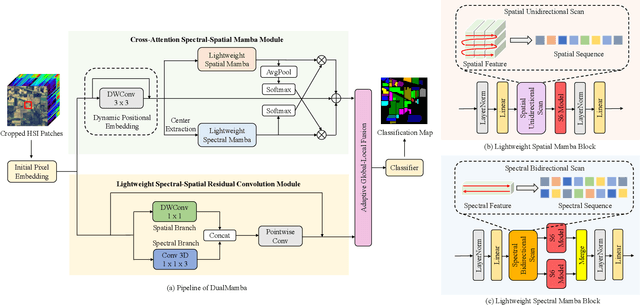
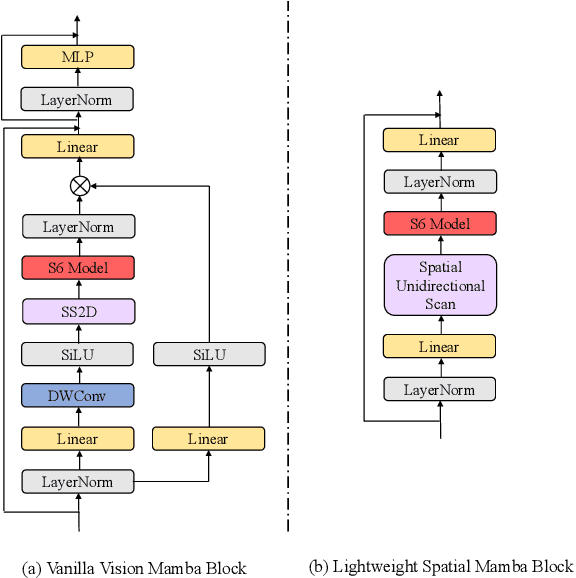
The effectiveness and efficiency of modeling complex spectral-spatial relations are both crucial for Hyperspectral image (HSI) classification. Most existing methods based on CNNs and transformers still suffer from heavy computational burdens and have room for improvement in capturing the global-local spectral-spatial feature representation. To this end, we propose a novel lightweight parallel design called lightweight dual-stream Mamba-convolution network (DualMamba) for HSI classification. Specifically, a parallel lightweight Mamba and CNN block are first developed to extract global and local spectral-spatial features. First, the cross-attention spectral-spatial Mamba module is proposed to leverage the global modeling of Mamba at linear complexity. Within this module, dynamic positional embedding is designed to enhance the spatial location information of visual sequences. The lightweight spectral/spatial Mamba blocks comprise an efficient scanning strategy and a lightweight Mamba design to efficiently extract global spectral-spatial features. And the cross-attention spectral-spatial fusion is designed to learn cross-correlation and fuse spectral-spatial features. Second, the lightweight spectral-spatial residual convolution module is proposed with lightweight spectral and spatial branches to extract local spectral-spatial features through residual learning. Finally, the adaptive global-local fusion is proposed to dynamically combine global Mamba features and local convolution features for a global-local spectral-spatial representation. Compared with state-of-the-art HSI classification methods, experimental results demonstrate that DualMamba achieves significant classification accuracy on three public HSI datasets and a superior reduction in model parameters and floating point operations (FLOPs).
A Soft Contrastive Learning-based Prompt Model for Few-shot Sentiment Analysis
Dec 16, 2023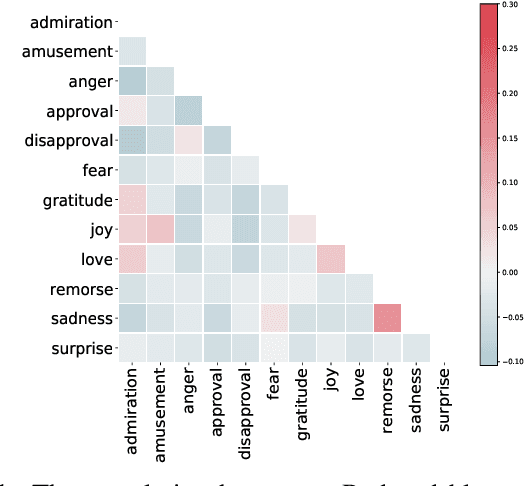


Few-shot text classification has attracted great interest in both academia and industry due to the lack of labeled data in many fields. Different from general text classification (e.g., topic classification), few-shot sentiment classification is more challenging because the semantic distances among the classes are more subtle. For instance, the semantic distances between the sentiment labels in a positive or negative polarity (e.g., ``love" and ``joy", ``remorse" and ``sadness") are close, while the distances are large for the sentiment labels in two opposite polarities (e.g., ``love" and ``sadness"). To address this problem, we propose a Soft Contrastive learning-based Prompt (\texttt{SCP}) model for few-shot sentiment analysis. First, we design a sentiment-aware chain of thought prompt module to guide the model to predict the sentiment from coarse grain to fine grain via a series of intermediate reasoning steps. Then, we propose a soft contrastive learning algorithm to take the correlation of the labels into account. A series of experiments on several sentiment analysis datasets show the great advantages of \texttt{SCP} by comparing it with SOTA baselines (e.g., ChatGPT).
When Hyperspectral Image Classification Meets Diffusion Models: An Unsupervised Feature Learning Framework
Jun 15, 2023



Learning effective spectral-spatial features is important for the hyperspectral image (HSI) classification task, but the majority of existing HSI classification methods still suffer from modeling complex spectral-spatial relations and characterizing low-level details and high-level semantics comprehensively. As a new class of record-breaking generative models, diffusion models are capable of modeling complex relations for understanding inputs well as learning both high-level and low-level visual features. Meanwhile, diffusion models can capture more abundant features by taking advantage of the extra and unique dimension of timestep t. In view of these, we propose an unsupervised spectral-spatial feature learning framework based on the diffusion model for HSI classification for the first time, named Diff-HSI. Specifically, we first pretrain the diffusion model with unlabeled HSI patches for unsupervised feature learning, and then exploit intermediate hierarchical features from different timesteps for classification. For better using the abundant timestep-wise features, we design a timestep-wise feature bank and a dynamic feature fusion module to construct timestep-wise features, adaptively learning informative multi-timestep representations. Finally, an ensemble of linear classifiers is applied to perform HSI classification. Extensive experiments are conducted on three public HSI datasets, and our results demonstrate that Diff-HSI outperforms state-of-the-art supervised and unsupervised methods for HSI classification.