 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Implicit Noise-based Imprint of Generative Models
Mar 12, 2025With the rapid advancement of vision generation models, the potential security risks stemming from synthetic visual content have garnered increasing attention, posing significant challenges for AI-generated image detection. Existing methods suffer from inadequate generalization capabilities, resulting in unsatisfactory performance on emerging generative models. To address this issue, this paper presents a novel framework that leverages noise-based model-specific imprint for the detection task. Specifically, we propose a novel noise-based imprint simulator to capture intrinsic patterns imprinted in images generated by different models. By aggregating imprints from various generative models, imprints of future models can be extrapolated to expand training data, thereby enhancing generalization and robustness. Furthermore, we design a new pipeline that pioneers the use of noise patterns, derived from a noise-based imprint extractor, alongside other visual features for AI-generated image detection, resulting in a significant improvement in performance. Our approach achieves state-of-the-art performance across three public benchmarks including GenImage, Synthbuster and Chameleon.
A Soft Contrastive Learning-based Prompt Model for Few-shot Sentiment Analysis
Dec 16, 2023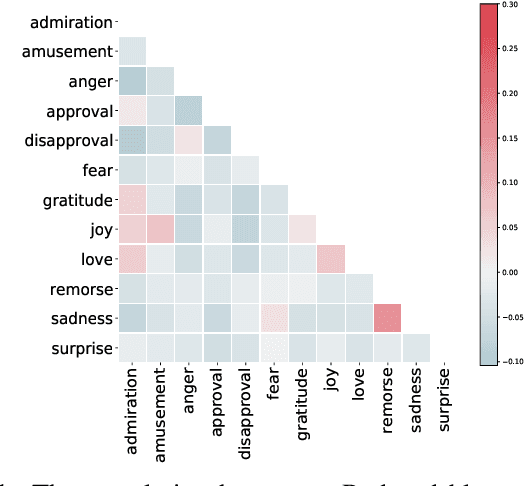


Few-shot text classification has attracted great interest in both academia and industry due to the lack of labeled data in many fields. Different from general text classification (e.g., topic classification), few-shot sentiment classification is more challenging because the semantic distances among the classes are more subtle. For instance, the semantic distances between the sentiment labels in a positive or negative polarity (e.g., ``love" and ``joy", ``remorse" and ``sadness") are close, while the distances are large for the sentiment labels in two opposite polarities (e.g., ``love" and ``sadness"). To address this problem, we propose a Soft Contrastive learning-based Prompt (\texttt{SCP}) model for few-shot sentiment analysis. First, we design a sentiment-aware chain of thought prompt module to guide the model to predict the sentiment from coarse grain to fine grain via a series of intermediate reasoning steps. Then, we propose a soft contrastive learning algorithm to take the correlation of the labels into account. A series of experiments on several sentiment analysis datasets show the great advantages of \texttt{SCP} by comparing it with SOTA baselines (e.g., ChatGPT).
Query Structure Modeling for Inductive Logical Reasoning Over Knowledge Graphs
May 23, 2023Logical reasoning over incomplete knowledge graphs to answer complex logical queries is a challenging task. With the emergence of new entities and relations in constantly evolving KGs, inductive logical reasoning over KGs has become a crucial problem. However, previous PLMs-based methods struggle to model the logical structures of complex queries, which limits their ability to generalize within the same structure. In this paper, we propose a structure-modeled textual encoding framework for inductive logical reasoning over KGs. It encodes linearized query structures and entities using pre-trained language models to find answers. For structure modeling of complex queries, we design stepwise instructions that implicitly prompt PLMs on the execution order of geometric operations in each query. We further separately model different geometric operations (i.e., projection, intersection, and union) on the representation space using a pre-trained encoder with additional attention and maxout layers to enhance structured modeling. We conduct experiments on two inductive logical reasoning datasets and three transductive datasets. The results demonstrate the effectiveness of our method on logical reasoning over KGs in both inductive and transductive settings.
Constructing Phrase-level Semantic Labels to Form Multi-Grained Supervision for Image-Text Retrieval
Sep 12, 2021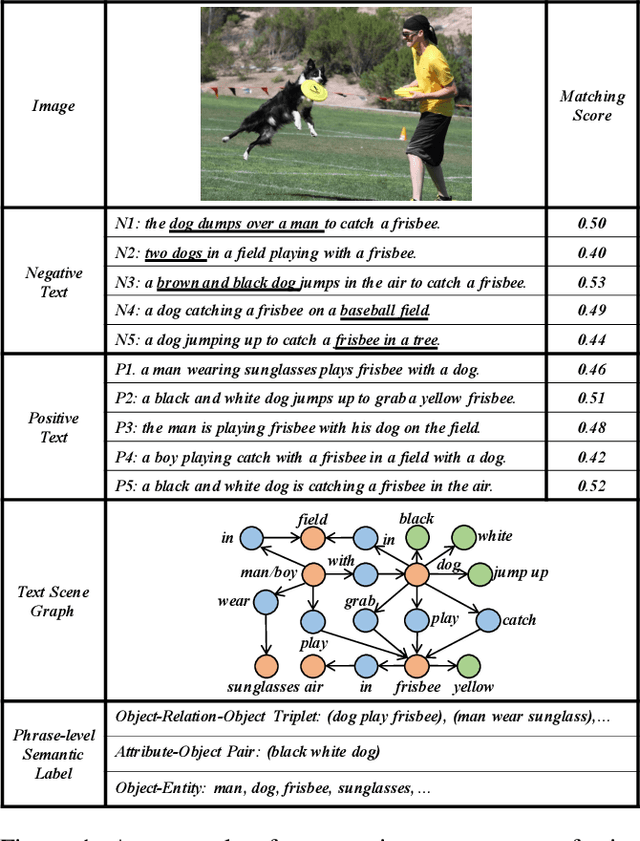
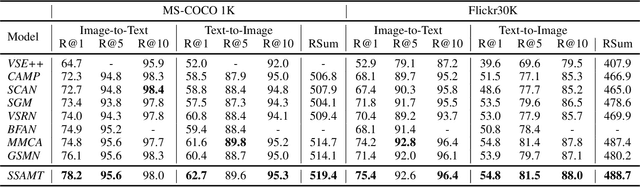
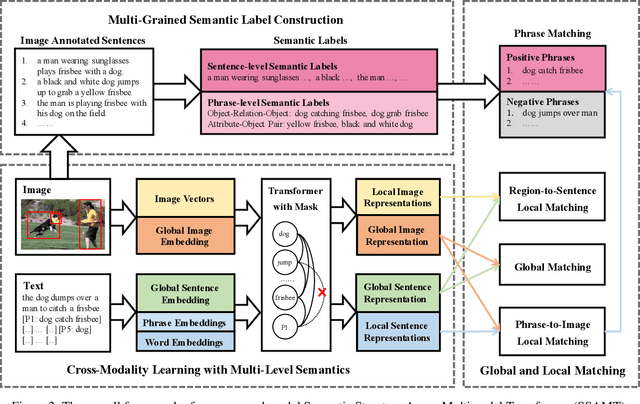
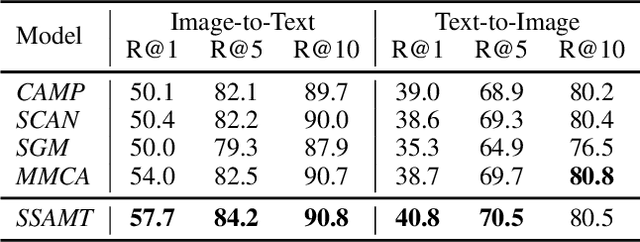
Existing research for image text retrieval mainly relies on sentence-level supervision to distinguish matched and mismatched sentences for a query image. However, semantic mismatch between an image and sentences usually happens in finer grain, i.e., phrase level. In this paper, we explore to introduce additional phrase-level supervision for the better identification of mismatched units in the text. In practice, multi-grained semantic labels are automatically constructed for a query image in both sentence-level and phrase-level. We construct text scene graphs for the matched sentences and extract entities and triples as the phrase-level labels. In order to integrate both supervision of sentence-level and phrase-level, we propose Semantic Structure Aware Multimodal Transformer (SSAMT) for multi-modal representation learning. Inside the SSAMT, we utilize different kinds of attention mechanisms to enforce interactions of multi-grain semantic units in both sides of vision and language. For the training, we propose multi-scale matching losses from both global and local perspectives, and penalize mismatched phrases. Experimental results on MS-COCO and Flickr30K show the effectiveness of our approach compared to some state-of-the-art models.
TCIC: Theme Concepts Learning Cross Language and Vision for Image Captioning
Jun 21, 2021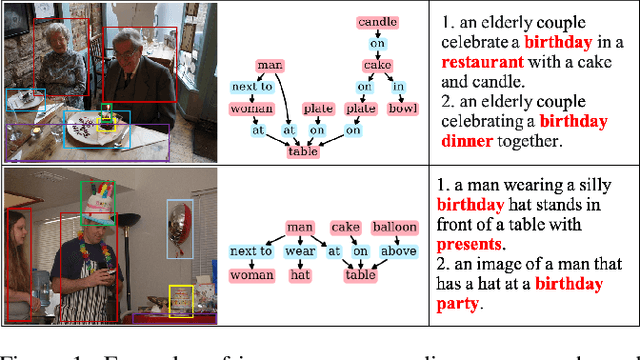
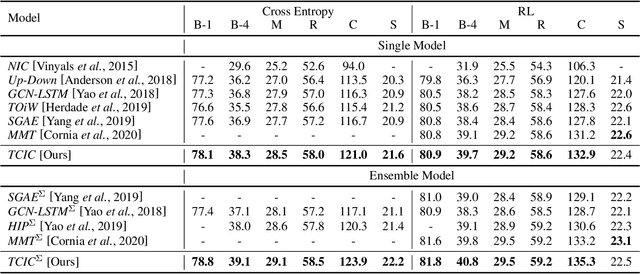
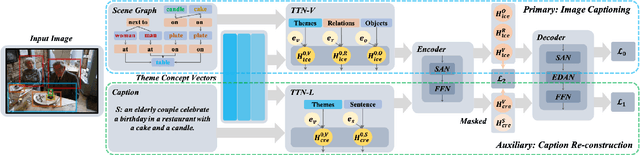
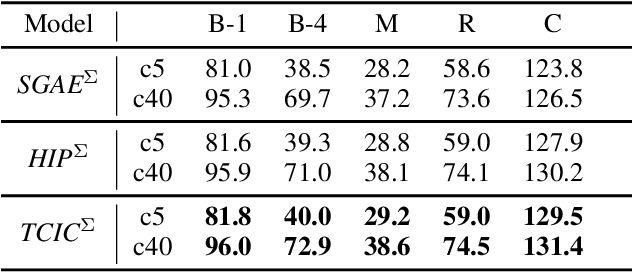
Existing research for image captioning usually represents an image using a scene graph with low-level facts (objects and relations) and fails to capture the high-level semantics. In this paper, we propose a Theme Concepts extended Image Captioning (TCIC) framework that incorporates theme concepts to represent high-level cross-modality semantics. In practice, we model theme concepts as memory vectors and propose Transformer with Theme Nodes (TTN) to incorporate those vectors for image captioning. Considering that theme concepts can be learned from both images and captions, we propose two settings for their representations learning based on TTN. On the vision side, TTN is configured to take both scene graph based features and theme concepts as input for visual representation learning. On the language side, TTN is configured to take both captions and theme concepts as input for text representation re-construction. Both settings aim to generate target captions with the same transformer-based decoder. During the training, we further align representations of theme concepts learned from images and corresponding captions to enforce the cross-modality learning. Experimental results on MS COCO show the effectiveness of our approach compared to some state-of-the-art models.
An Unsupervised Sampling Approach for Image-Sentence Matching Using Document-Level Structural Information
Mar 21, 2021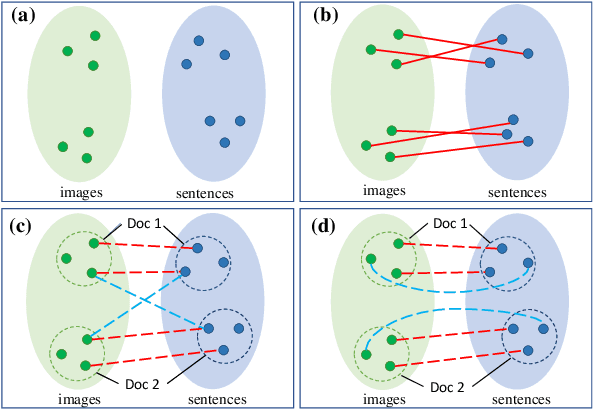

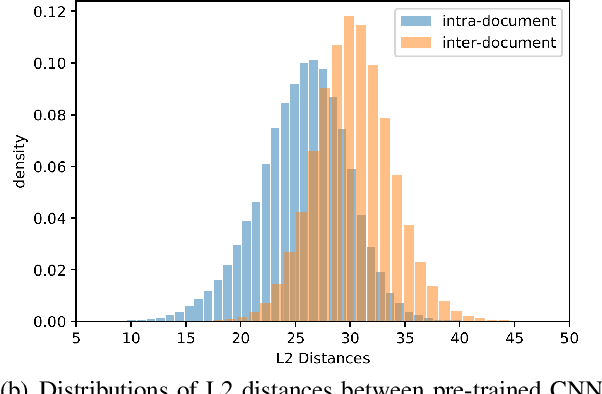
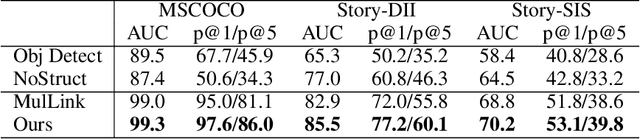
In this paper, we focus on the problem of unsupervised image-sentence matching. Existing research explores to utilize document-level structural information to sample positive and negative instances for model training. Although the approach achieves positive results, it introduces a sampling bias and fails to distinguish instances with high semantic similarity. To alleviate the bias, we propose a new sampling strategy to select additional intra-document image-sentence pairs as positive or negative samples. Furthermore, to recognize the complex pattern in intra-document samples, we propose a Transformer based model to capture fine-grained features and implicitly construct a graph for each document, where concepts in a document are introduced to bridge the representation learning of images and sentences in the context of a document. Experimental results show the effectiveness of our approach to alleviate the bias and learn well-aligned multimodal representations.
Keep it Consistent: Topic-Aware Storytelling from an Image Stream via Iterative Multi-agent Communication
Nov 11, 2019
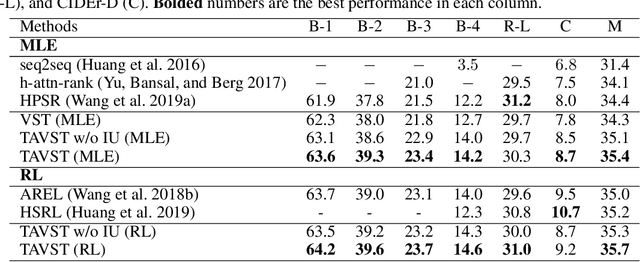
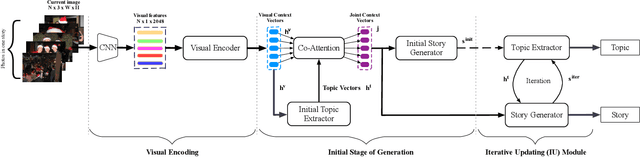
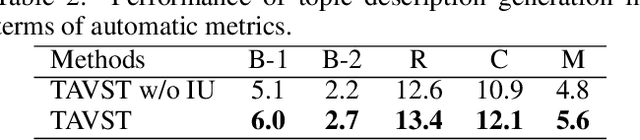
Visual storytelling aims to generate a narrative paragraph from a sequence of images automatically. Existing approaches construct text description independently for each image and roughly concatenate them as a story, which leads to the problem of generating semantically incoherent content. In this paper, we proposed a new way for visual storytelling by introducing a topic description task to detect the global semantic context of an image stream. A story is then constructed with the guidance of the topic description. In order to combine the two generation tasks, we propose a multi-agent communication framework that regards the topic description generator and the story generator as two agents and learn them simultaneously via iterative updating mechanism. We validate our approach on VIST, where quantitative results, ablations, and human evaluation demonstrate our method's good ability in generating stories with higher quality compared to state-of-the-art methods.