 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivating Distributed Visual Region within LLMs for Efficient and Effective Vision-Language Training and Inference
Dec 17, 2024



Large Vision-Language Models (LVLMs) typically learn visual capacity through visual instruction tuning, involving updates to both a projector and their LLM backbones. Drawing inspiration from the concept of visual region in the human brain, we investigate the existence of an analogous \textit{visual region} within LLMs that functions as a cognitive core, and explore the possibility of efficient training of LVLMs via selective layers tuning. We use Bunny-Llama-3-8B-V for detailed experiments and LLaVA-1.5-7B and LLaVA-1.5-13B for validation across a range of visual and textual tasks. Our findings reveal that selectively updating 25\% of LLMs layers, when sparsely and uniformly distributed, can preserve nearly 99\% of visual performance while maintaining or enhancing textual task results, and also effectively reducing training time. Based on this targeted training approach, we further propose a novel visual region-based pruning paradigm, removing non-critical layers outside the visual region, which can achieve minimal performance loss. This study offers an effective and efficient strategy for LVLM training and inference by activating a layer-wise visual region within LLMs, which is consistently effective across different models and parameter scales.
RSL-SQL: Robust Schema Linking in Text-to-SQL Generation
Oct 31, 2024



Text-to-SQL generation aims to translate natural language questions into SQL statements. In large language models (LLMs) based Text-to-SQL, schema linking is a widely adopted strategy to streamline the input for LLMs by selecting only relevant schema elements, therefore reducing noise and computational overhead. However, schema linking faces risks that requires caution, including the potential omission of necessary elements and disruption of database structural integrity. To address these challenges, we propose a novel framework called RSL-SQL that combines bidirectional schema linking, contextual information augmentation, binary selection strategy, and multi-turn self-correction. Our approach improves the recall of schema linking through forward and backward pruning and hedges the risk by voting between full schema and contextual information augmented simplified schema. Experiments on the BIRD and Spider benchmarks demonstrate that our approach achieves state-of-the-art execution accuracy among open-source solutions, with 67.2% on BIRD and 87.9% on Spider using GPT-4o. Furthermore, our approach outperforms a series of GPT-4 based Text-to-SQL systems when adopting DeepSeek (much cheaper) with same intact prompts. Extensive analysis and ablation studies confirm the effectiveness of each component in our framework. The codes are available at https://github.com/Laqcce-cao/RSL-SQL.
MC-CoT: A Modular Collaborative CoT Framework for Zero-shot Medical-VQA with LLM and MLLM Integration
Oct 06, 2024



In recent advancements, multimodal large language models (MLLMs) have been fine-tuned on specific medical image datasets to address medical visual question answering (Med-VQA) tasks. However, this common approach of task-specific fine-tuning is costly and necessitates separate models for each downstream task, limiting the exploration of zero-shot capabilities. In this paper, we introduce MC-CoT, a modular cross-modal collaboration Chain-of-Thought (CoT) framework designed to enhance the zero-shot performance of MLLMs in Med-VQA by leveraging large language models (LLMs). MC-CoT improves reasoning and information extraction by integrating medical knowledge and task-specific guidance, where LLM provides various complex medical reasoning chains and MLLM provides various observations of medical images based on instructions of the LLM. Our experiments on datasets such as SLAKE, VQA-RAD, and PATH-VQA show that MC-CoT surpasses standalone MLLMs and various multimodality CoT frameworks in recall rate and accuracy. These findings highlight the importance of incorporating background information and detailed guidance in addressing complex zero-shot Med-VQA tasks.
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Sep 18, 2024



We present the Qwen2-VL Series, an advanced upgrade of the previous Qwen-VL models that redefines the conventional predetermined-resolution approach in visual processing. Qwen2-VL introduces the Naive Dynamic Resolution mechanism, which enables the model to dynamically process images of varying resolutions into different numbers of visual tokens. This approach allows the model to generate more efficient and accurate visual representations, closely aligning with human perceptual processes. The model also integrates Multimodal Rotary Position Embedding (M-RoPE), facilitating the effective fusion of positional information across text, images, and videos. We employ a unified paradigm for processing both images and videos, enhancing the model's visual perception capabilities. To explore the potential of large multimodal models, Qwen2-VL investigates the scaling laws for large vision-language models (LVLMs). By scaling both the model size-with versions at 2B, 8B, and 72B parameters-and the amount of training data, the Qwen2-VL Series achieves highly competitive performance. Notably, the Qwen2-VL-72B model achieves results comparable to leading models such as GPT-4o and Claude3.5-Sonnet across various multimodal benchmarks, outperforming other generalist models. Code is available at \url{https://github.com/QwenLM/Qwen2-VL}.
Qwen2 Technical Report
Jul 16, 2024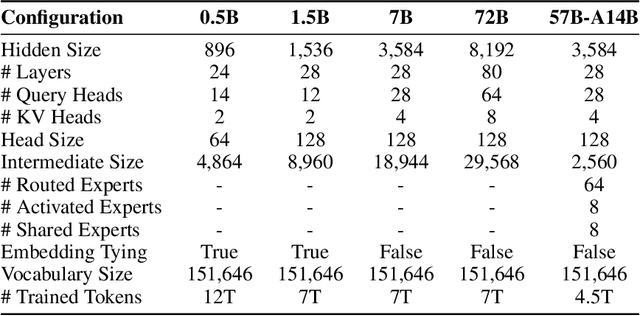
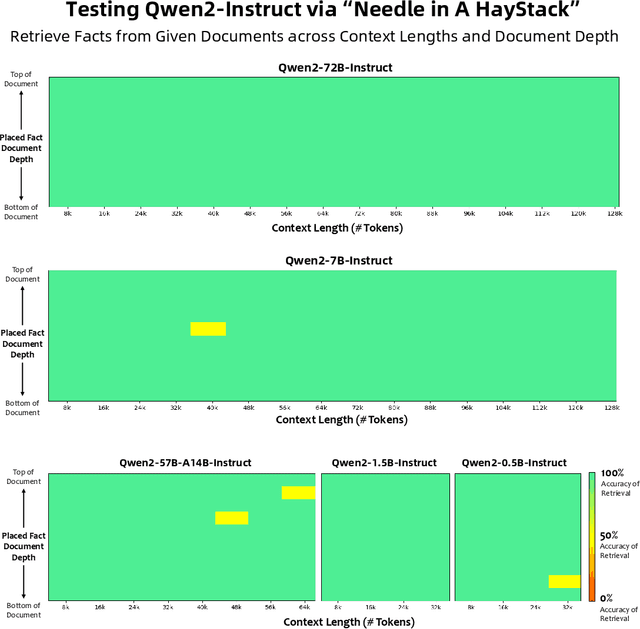
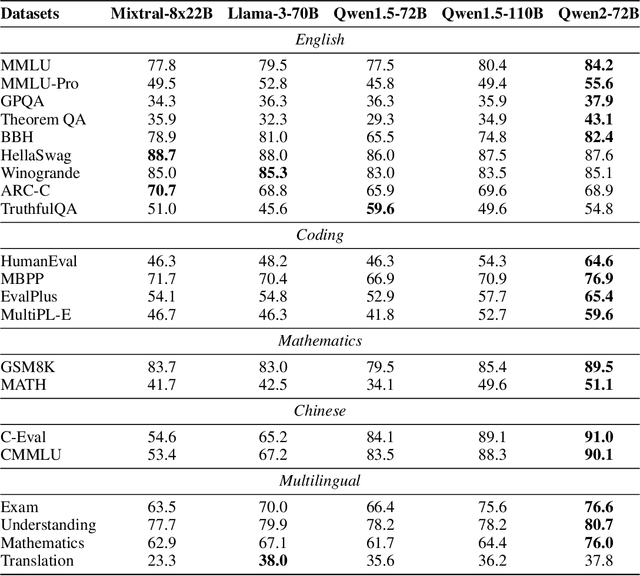
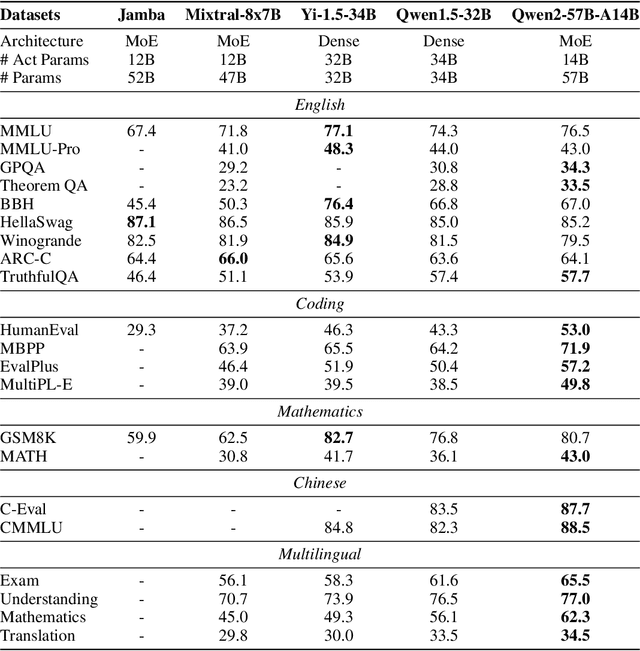
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
From LLMs to MLLMs: Exploring the Landscape of Multimodal Jailbreaking
Jun 21, 2024The rapid development of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has exposed vulnerabilities to various adversarial attacks. This paper provides a comprehensive overview of jailbreaking research targeting both LLMs and MLLMs, highlighting recent advancements in evaluation benchmarks, attack techniques and defense strategies. Compared to the more advanced state of unimodal jailbreaking, multimodal domain remains underexplored. We summarize the limitations and potential research directions of multimodal jailbreaking, aiming to inspire future research and further enhance the robustness and security of MLLMs.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024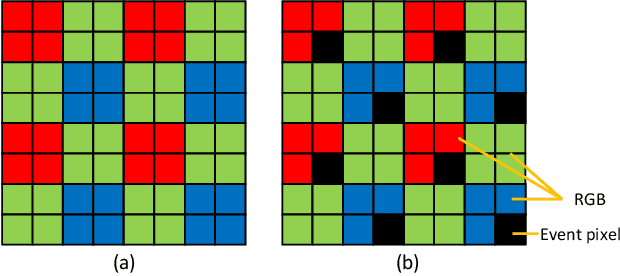
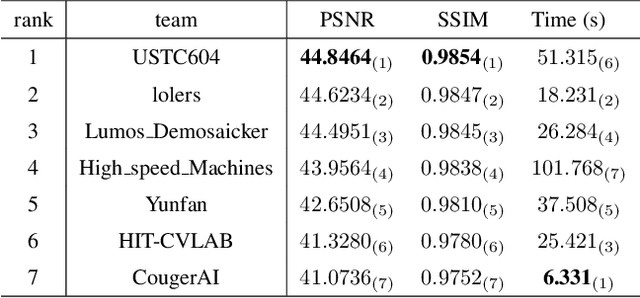
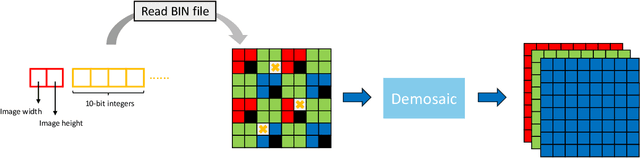

The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
DELAN: Dual-Level Alignment for Vision-and-Language Navigation by Cross-Modal Contrastive Learning
Apr 02, 2024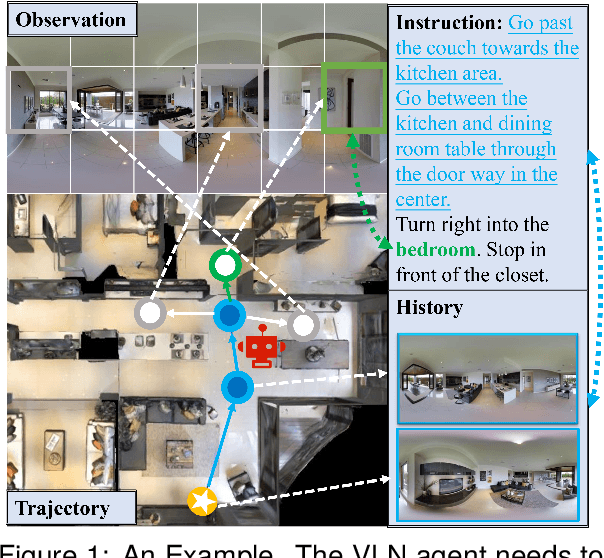

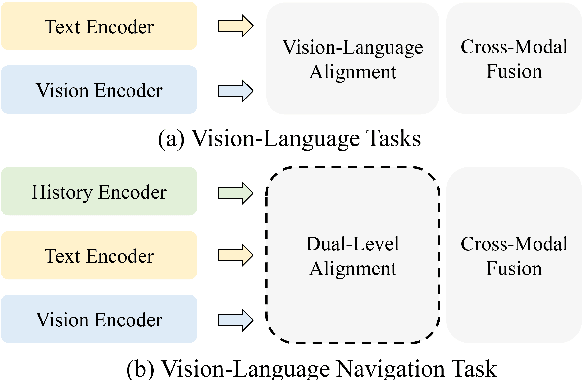

Vision-and-Language navigation (VLN) requires an agent to navigate in unseen environment by following natural language instruction. For task completion, the agent needs to align and integrate various navigation modalities, including instruction, observation and navigation history. Existing works primarily concentrate on cross-modal attention at the fusion stage to achieve this objective. Nevertheless, modality features generated by disparate uni-encoders reside in their own spaces, leading to a decline in the quality of cross-modal fusion and decision. To address this problem, we propose a Dual-levEL AligNment (DELAN) framework by cross-modal contrastive learning. This framework is designed to align various navigation-related modalities before fusion, thereby enhancing cross-modal interaction and action decision-making. Specifically, we divide the pre-fusion alignment into dual levels: instruction-history level and landmark-observation level according to their semantic correlations. We also reconstruct a dual-level instruction for adaptation to the dual-level alignment. As the training signals for pre-fusion alignment are extremely limited, self-supervised contrastive learning strategies are employed to enforce the matching between different modalities. Our approach seamlessly integrates with the majority of existing models, resulting in improved navigation performance on various VLN benchmarks, including R2R, R4R, RxR and CVDN.
AI Hospital: Interactive Evaluation and Collaboration of LLMs as Intern Doctors for Clinical Diagnosis
Feb 21, 2024



The incorporation of Large Language Models (LLMs) in healthcare marks a significant advancement. However, the application has predominantly been limited to discriminative and question-answering tasks, which does not fully leverage their interactive potential. To address this limitation, our paper presents AI Hospital, a framework designed to build a real-time interactive diagnosis environment. To simulate the procedure, we collect high-quality medical records to create patient, examiner, and medical director agents. AI Hospital is then utilized for the interactive evaluation and collaboration of LLMs. Initially, we create a Multi-View Medical Evaluation (MVME) benchmark where various LLMs serve as intern doctors for interactive diagnosis. Subsequently, to improve diagnostic accuracy, we introduce a collaborative mechanism that involves iterative discussions and a dispute resolution process under the supervision of the medical director. In our experiments, we validate the reliability of AI Hospital. The results not only explore the feasibility of apply LLMs in clinical consultation but also confirm the effectiveness of the dispute resolution focused collaboration method.
Benchmark Self-Evolving: A Multi-Agent Framework for Dynamic LLM Evaluation
Feb 18, 2024This paper presents a benchmark self-evolving framework to dynamically evaluate rapidly advancing Large Language Models (LLMs), aiming for a more accurate assessment of their capabilities and limitations. We utilize a multi-agent system to manipulate the context or question of original instances, reframing new evolving instances with high confidence that dynamically extend existing benchmarks. Towards a more scalable, robust and fine-grained evaluation, we implement six reframing operations to construct evolving instances testing LLMs against diverse queries, data noise and probing their problem-solving sub-abilities. With this framework, we extend benchmark datasets of four tasks. Experimental results show a general performance decline in most LLMs against their original results. This decline under our scalable and robust evaluations, alongside our fine-grained evaluation, more accurately reflect models' capabilities. Besides, our framework widens performance discrepancies both between different models and within the same model across various tasks, facilitating more informed model selection for specific tasks (Code and data are available at https://github.com/NanshineLoong/Self-Evolving-Benchmark).