 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Achieve Efficient Diffusion without Self-Attention? Distilling Self-Attention into Convolutions
Apr 30, 2025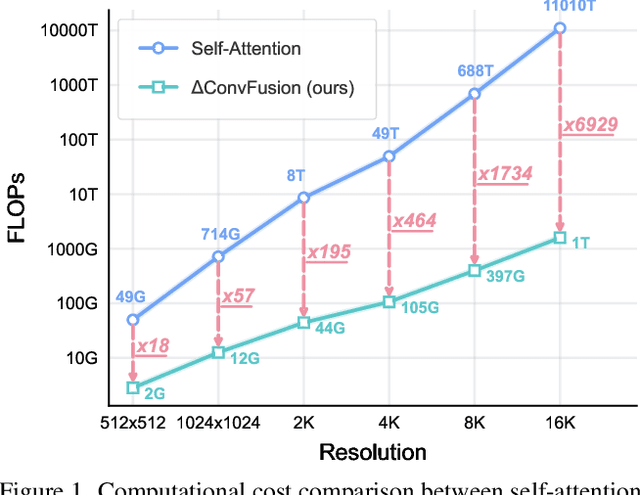
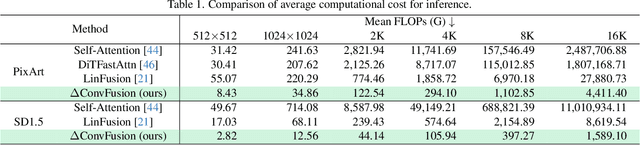

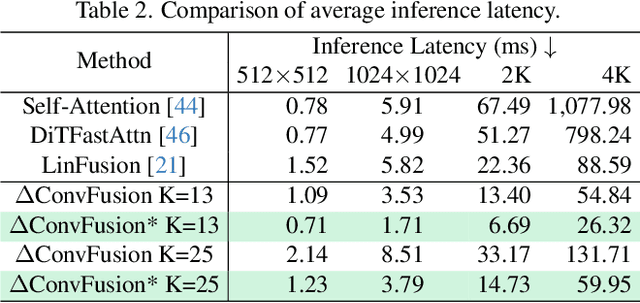
Contemporary diffusion models built upon U-Net or Diffusion Transformer (DiT) architectures have revolutionized image generation through transformer-based attention mechanisms. The prevailing paradigm has commonly employed self-attention with quadratic computational complexity to handle global spatial relationships in complex images, thereby synthesizing high-fidelity images with coherent visual semantics.Contrary to conventional wisdom, our systematic layer-wise analysis reveals an interesting discrepancy: self-attention in pre-trained diffusion models predominantly exhibits localized attention patterns, closely resembling convolutional inductive biases. This suggests that global interactions in self-attention may be less critical than commonly assumed.Driven by this, we propose \(\Delta\)ConvFusion to replace conventional self-attention modules with Pyramid Convolution Blocks (\(\Delta\)ConvBlocks).By distilling attention patterns into localized convolutional operations while keeping other components frozen, \(\Delta\)ConvFusion achieves performance comparable to transformer-based counterparts while reducing computational cost by 6929$\times$ and surpassing LinFusion by 5.42$\times$ in efficiency--all without compromising generative fidelity.
Activating Distributed Visual Region within LLMs for Efficient and Effective Vision-Language Training and Inference
Dec 17, 2024



Large Vision-Language Models (LVLMs) typically learn visual capacity through visual instruction tuning, involving updates to both a projector and their LLM backbones. Drawing inspiration from the concept of visual region in the human brain, we investigate the existence of an analogous \textit{visual region} within LLMs that functions as a cognitive core, and explore the possibility of efficient training of LVLMs via selective layers tuning. We use Bunny-Llama-3-8B-V for detailed experiments and LLaVA-1.5-7B and LLaVA-1.5-13B for validation across a range of visual and textual tasks. Our findings reveal that selectively updating 25\% of LLMs layers, when sparsely and uniformly distributed, can preserve nearly 99\% of visual performance while maintaining or enhancing textual task results, and also effectively reducing training time. Based on this targeted training approach, we further propose a novel visual region-based pruning paradigm, removing non-critical layers outside the visual region, which can achieve minimal performance loss. This study offers an effective and efficient strategy for LVLM training and inference by activating a layer-wise visual region within LLMs, which is consistently effective across different models and parameter scales.
ReForm-Eval: Evaluating Large Vision Language Models via Unified Re-Formulation of Task-Oriented Benchmarks
Oct 17, 2023



Recent years have witnessed remarkable progress in the development of large vision-language models (LVLMs). Benefiting from the strong language backbones and efficient cross-modal alignment strategies, LVLMs exhibit surprising capabilities to perceive visual signals and perform visually grounded reasoning. However, the capabilities of LVLMs have not been comprehensively and quantitatively evaluate. Most existing multi-modal benchmarks require task-oriented input-output formats, posing great challenges to automatically assess the free-form text output of LVLMs. To effectively leverage the annotations available in existing benchmarks and reduce the manual effort required for constructing new benchmarks, we propose to re-formulate existing benchmarks into unified LVLM-compatible formats. Through systematic data collection and reformulation, we present the ReForm-Eval benchmark, offering substantial data for evaluating various capabilities of LVLMs. Based on ReForm-Eval, we conduct extensive experiments, thoroughly analyze the strengths and weaknesses of existing LVLMs, and identify the underlying factors. Our benchmark and evaluation framework will be open-sourced as a cornerstone for advancing the development of LVLMs.