 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventFlash: Towards Efficient MLLMs for Event-Based Vision
Feb 03, 2026Event-based multimodal large language models (MLLMs) enable robust perception in high-speed and low-light scenarios, addressing key limitations of frame-based MLLMs. However, current event-based MLLMs often rely on dense image-like processing paradigms, overlooking the spatiotemporal sparsity of event streams and resulting in high computational cost. In this paper, we propose EventFlash, a novel and efficient MLLM to explore spatiotemporal token sparsification for reducing data redundancy and accelerating inference. Technically, we build EventMind, a large-scale and scene-diverse dataset with over 500k instruction sets, providing both short and long event stream sequences to support our curriculum training strategy. We then present an adaptive temporal window aggregation module for efficient temporal sampling, which adaptively compresses temporal tokens while retaining key temporal cues. Finally, a sparse density-guided attention module is designed to improve spatial token efficiency by selecting informative regions and suppressing empty or sparse areas. Experimental results show that EventFlash achieves a $12.4\times$ throughput improvement over the baseline (EventFlash-Zero) while maintaining comparable performance. It supports long-range event stream processing with up to 1,000 bins, significantly outperforming the 5-bin limit of EventGPT. We believe EventFlash serves as an efficient foundation model for event-based vision.
Small Generalizable Prompt Predictive Models Can Steer Efficient RL Post-Training of Large Reasoning Models
Feb 02, 2026Reinforcement learning enhances the reasoning capabilities of large language models but often involves high computational costs due to rollout-intensive optimization. Online prompt selection presents a plausible solution by prioritizing informative prompts to improve training efficiency. However, current methods either depend on costly, exact evaluations or construct prompt-specific predictive models lacking generalization across prompts. This study introduces Generalizable Predictive Prompt Selection (GPS), which performs Bayesian inference towards prompt difficulty using a lightweight generative model trained on the shared optimization history. Intermediate-difficulty prioritization and history-anchored diversity are incorporated into the batch acquisition principle to select informative prompt batches. The small predictive model also generalizes at test-time for efficient computational allocation. Experiments across varied reasoning benchmarks indicate GPS's substantial improvements in training efficiency, final performance, and test-time efficiency over superior baseline methods.
HINT: Hierarchical Interaction Modeling for Autoregressive Multi-Human Motion Generation
Jan 28, 2026Text-driven multi-human motion generation with complex interactions remains a challenging problem. Despite progress in performance, existing offline methods that generate fixed-length motions with a fixed number of agents, are inherently limited in handling long or variable text, and varying agent counts. These limitations naturally encourage autoregressive formulations, which predict future motions step by step conditioned on all past trajectories and current text guidance. In this work, we introduce HINT, the first autoregressive framework for multi-human motion generation with Hierarchical INTeraction modeling in diffusion. First, HINT leverages a disentangled motion representation within a canonicalized latent space, decoupling local motion semantics from inter-person interactions. This design facilitates direct adaptation to varying numbers of human participants without requiring additional refinement. Second, HINT adopts a sliding-window strategy for efficient online generation, and aggregates local within-window and global cross-window conditions to capture past human history, inter-person dependencies, and align with text guidance. This strategy not only enables fine-grained interaction modeling within each window but also preserves long-horizon coherence across all the long sequence. Extensive experiments on public benchmarks demonstrate that HINT matches the performance of strong offline models and surpasses autoregressive baselines. Notably, on InterHuman, HINT achieves an FID of 3.100, significantly improving over the previous state-of-the-art score of 5.154.
Unveiling Perceptual Artifacts: A Fine-Grained Benchmark for Interpretable AI-Generated Image Detection
Jan 27, 2026Current AI-Generated Image (AIGI) detection approaches predominantly rely on binary classification to distinguish real from synthetic images, often lacking interpretable or convincing evidence to substantiate their decisions. This limitation stems from existing AIGI detection benchmarks, which, despite featuring a broad collection of synthetic images, remain restricted in their coverage of artifact diversity and lack detailed, localized annotations. To bridge this gap, we introduce a fine-grained benchmark towards eXplainable AI-Generated image Detection, named X-AIGD, which provides pixel-level, categorized annotations of perceptual artifacts, spanning low-level distortions, high-level semantics, and cognitive-level counterfactuals. These comprehensive annotations facilitate fine-grained interpretability evaluation and deeper insight into model decision-making processes. Our extensive investigation using X-AIGD provides several key insights: (1) Existing AIGI detectors demonstrate negligible reliance on perceptual artifacts, even at the most basic distortion level. (2) While AIGI detectors can be trained to identify specific artifacts, they still substantially base their judgment on uninterpretable features. (3) Explicitly aligning model attention with artifact regions can increase the interpretability and generalization of detectors. The data and code are available at: https://github.com/Coxy7/X-AIGD.
Scoring, Reasoning, and Selecting the Best! Ensembling Large Language Models via a Peer-Review Process
Dec 29, 2025We propose LLM-PeerReview, an unsupervised LLM Ensemble method that selects the most ideal response from multiple LLM-generated candidates for each query, harnessing the collective wisdom of multiple models with diverse strengths. LLM-PeerReview is built on a novel, peer-review-inspired framework that offers a clear and interpretable mechanism, while remaining fully unsupervised for flexible adaptability and generalization. Specifically, it operates in three stages: For scoring, we use the emerging LLM-as-a-Judge technique to evaluate each response by reusing multiple LLMs at hand; For reasoning, we can apply a principled graphical model-based truth inference algorithm or a straightforward averaging strategy to aggregate multiple scores to produce a final score for each response; Finally, the highest-scoring response is selected as the best ensemble output. LLM-PeerReview is conceptually simple and empirically powerful. The two variants of the proposed approach obtain strong results across four datasets, including outperforming the recent advanced model Smoothie-Global by 6.9% and 7.3% points, respectively.
Bridging Cognitive Gap: Hierarchical Description Learning for Artistic Image Aesthetics Assessment
Dec 29, 2025The aesthetic quality assessment task is crucial for developing a human-aligned quantitative evaluation system for AIGC. However, its inherently complex nature, spanning visual perception, cognition, and emotion, poses fundamental challenges. Although aesthetic descriptions offer a viable representation of this complexity, two critical challenges persist: (1) data scarcity and imbalance: existing dataset overly focuses on visual perception and neglects deeper dimensions due to the expensive manual annotation; and (2) model fragmentation: current visual networks isolate aesthetic attributes with multi-branch encoder, while multimodal methods represented by contrastive learning struggle to effectively process long-form textual descriptions. To resolve challenge (1), we first present the Refined Aesthetic Description (RAD) dataset, a large-scale (70k), multi-dimensional structured dataset, generated via an iterative pipeline without heavy annotation costs and easy to scale. To address challenge (2), we propose ArtQuant, an aesthetics assessment framework for artistic images which not only couples isolated aesthetic dimensions through joint description generation, but also better models long-text semantics with the help of LLM decoders. Besides, theoretical analysis confirms this symbiosis: RAD's semantic adequacy (data) and generation paradigm (model) collectively minimize prediction entropy, providing mathematical grounding for the framework. Our approach achieves state-of-the-art performance on several datasets while requiring only 33% of conventional training epochs, narrowing the cognitive gap between artistic images and aesthetic judgment. We will release both code and dataset to support future research.
LongFly: Long-Horizon UAV Vision-and-Language Navigation with Spatiotemporal Context Integration
Dec 26, 2025Unmanned aerial vehicles (UAVs) are crucial tools for post-disaster search and rescue, facing challenges such as high information density, rapid changes in viewpoint, and dynamic structures, especially in long-horizon navigation. However, current UAV vision-and-language navigation(VLN) methods struggle to model long-horizon spatiotemporal context in complex environments, resulting in inaccurate semantic alignment and unstable path planning. To this end, we propose LongFly, a spatiotemporal context modeling framework for long-horizon UAV VLN. LongFly proposes a history-aware spatiotemporal modeling strategy that transforms fragmented and redundant historical data into structured, compact, and expressive representations. First, we propose the slot-based historical image compression module, which dynamically distills multi-view historical observations into fixed-length contextual representations. Then, the spatiotemporal trajectory encoding module is introduced to capture the temporal dynamics and spatial structure of UAV trajectories. Finally, to integrate existing spatiotemporal context with current observations, we design the prompt-guided multimodal integration module to support time-based reasoning and robust waypoint prediction. Experimental results demonstrate that LongFly outperforms state-of-the-art UAV VLN baselines by 7.89\% in success rate and 6.33\% in success weighted by path length, consistently across both seen and unseen environments.
DiverseGRPO: Mitigating Mode Collapse in Image Generation via Diversity-Aware GRPO
Dec 25, 2025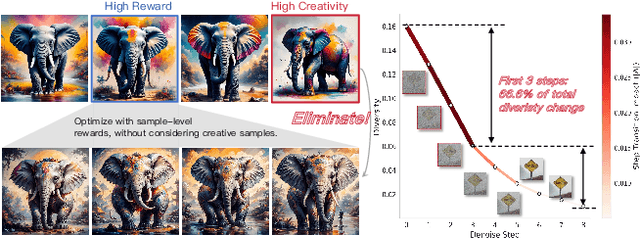



Reinforcement learning (RL), particularly GRPO, improves image generation quality significantly by comparing the relative performance of images generated within the same group. However, in the later stages of training, the model tends to produce homogenized outputs, lacking creativity and visual diversity, which restricts its application scenarios. This issue can be analyzed from both reward modeling and generation dynamics perspectives. First, traditional GRPO relies on single-sample quality as the reward signal, driving the model to converge toward a few high-reward generation modes while neglecting distribution-level diversity. Second, conventional GRPO regularization neglects the dominant role of early-stage denoising in preserving diversity, causing a misaligned regularization budget that limits the achievable quality--diversity trade-off. Motivated by these insights, we revisit the diversity degradation problem from both reward modeling and generation dynamics. At the reward level, we propose a distributional creativity bonus based on semantic grouping. Specifically, we construct a distribution-level representation via spectral clustering over samples generated from the same caption, and adaptively allocate exploratory rewards according to group sizes to encourage the discovery of novel visual modes. At the generation level, we introduce a structure-aware regularization, which enforces stronger early-stage constraints to preserve diversity without compromising reward optimization efficiency. Experiments demonstrate that our method achieves a 13\%--18\% improvement in semantic diversity under matched quality scores, establishing a new Pareto frontier between image quality and diversity for GRPO-based image generation.
UniStateDLO: Unified Generative State Estimation and Tracking of Deformable Linear Objects Under Occlusion for Constrained Manipulation
Dec 19, 2025Perception of deformable linear objects (DLOs), such as cables, ropes, and wires, is the cornerstone for successful downstream manipulation. Although vision-based methods have been extensively explored, they remain highly vulnerable to occlusions that commonly arise in constrained manipulation environments due to surrounding obstacles, large and varying deformations, and limited viewpoints. Moreover, the high dimensionality of the state space, the lack of distinctive visual features, and the presence of sensor noises further compound the challenges of reliable DLO perception. To address these open issues, this paper presents UniStateDLO, the first complete DLO perception pipeline with deep-learning methods that achieves robust performance under severe occlusion, covering both single-frame state estimation and cross-frame state tracking from partial point clouds. Both tasks are formulated as conditional generative problems, leveraging the strong capability of diffusion models to capture the complex mapping between highly partial observations and high-dimensional DLO states. UniStateDLO effectively handles a wide range of occlusion patterns, including initial occlusion, self-occlusion, and occlusion caused by multiple objects. In addition, it exhibits strong data efficiency as the entire network is trained solely on a large-scale synthetic dataset, enabling zero-shot sim-to-real generalization without any real-world training data. Comprehensive simulation and real-world experiments demonstrate that UniStateDLO outperforms all state-of-the-art baselines in both estimation and tracking, producing globally smooth yet locally precise DLO state predictions in real time, even under substantial occlusions. Its integration as the front-end module in a closed-loop DLO manipulation system further demonstrates its ability to support stable feedback control in complex, constrained 3-D environments.
Learning to Remove Lens Flare in Event Camera
Dec 09, 2025Event cameras have the potential to revolutionize vision systems with their high temporal resolution and dynamic range, yet they remain susceptible to lens flare, a fundamental optical artifact that causes severe degradation. In event streams, this optical artifact forms a complex, spatio-temporal distortion that has been largely overlooked. We present E-Deflare, the first systematic framework for removing lens flare from event camera data. We first establish the theoretical foundation by deriving a physics-grounded forward model of the non-linear suppression mechanism. This insight enables the creation of the E-Deflare Benchmark, a comprehensive resource featuring a large-scale simulated training set, E-Flare-2.7K, and the first-ever paired real-world test set, E-Flare-R, captured by our novel optical system. Empowered by this benchmark, we design E-DeflareNet, which achieves state-of-the-art restoration performance. Extensive experiments validate our approach and demonstrate clear benefits for downstream tasks. Code and datasets are publicly available.