 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3ST: A Synthetic 3D Dataset With Realistic Trajectories
Dec 18, 2025Datasets are essential to train and evaluate computer vision models used for traffic analysis and to enhance road safety. Existing real datasets fit real-world scenarios, capturing authentic road object behaviors, however, they typically lack precise ground-truth annotations. In contrast, synthetic datasets play a crucial role, allowing for the annotation of a large number of frames without additional costs or extra time. However, a general drawback of synthetic datasets is the lack of realistic vehicle motion, since trajectories are generated using AI models or rule-based systems. In this work, we introduce R3ST (Realistic 3D Synthetic Trajectories), a synthetic dataset that overcomes this limitation by generating a synthetic 3D environment and integrating real-world trajectories derived from SinD, a bird's-eye-view dataset recorded from drone footage. The proposed dataset closes the gap between synthetic data and realistic trajectories, advancing the research in trajectory forecasting of road vehicles, offering both accurate multimodal ground-truth annotations and authentic human-driven vehicle trajectories.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Training-Free Style and Content Transfer by Leveraging U-Net Skip Connections in Stable Diffusion 2.*
Jan 24, 2025


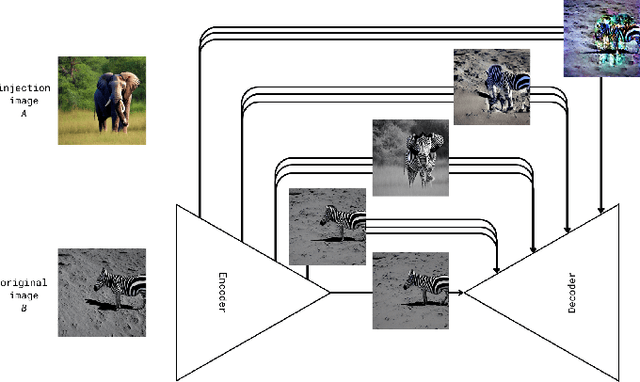
Despite significant recent advances in image generation with diffusion models, their internal latent representations remain poorly understood. Existing works focus on the bottleneck layer (h-space) of Stable Diffusion's U-Net or leverage the cross-attention, self-attention, or decoding layers. Our model, SkipInject takes advantage of U-Net's skip connections. We conduct thorough analyses on the role of the skip connections and find that the residual connections passed by the third encoder block carry most of the spatial information of the reconstructed image, splitting the content from the style. We show that injecting the representations from this block can be used for text-based editing, precise modifications, and style transfer. We compare our methods state-of-the-art style transfer and image editing methods and demonstrate that our method obtains the best content alignment and optimal structural preservation tradeoff.
STLight: a Fully Convolutional Approach for Efficient Predictive Learning by Spatio-Temporal joint Processing
Nov 15, 2024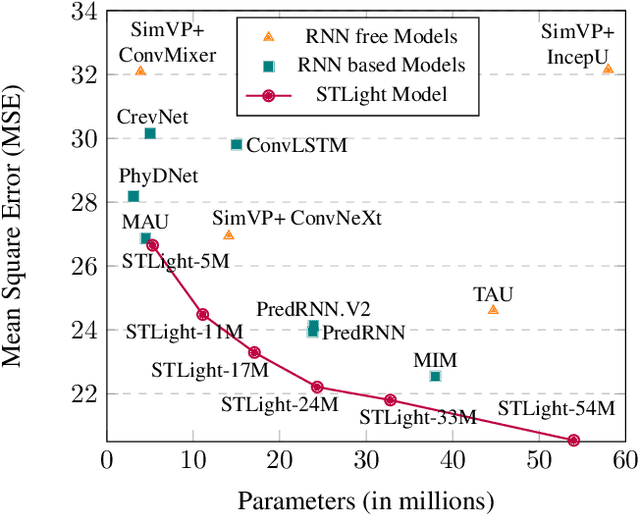

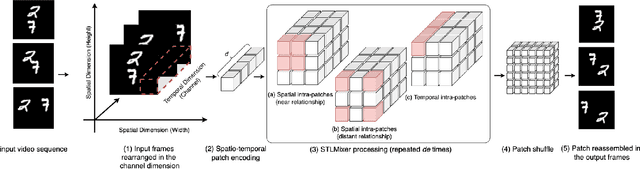

Spatio-Temporal predictive Learning is a self-supervised learning paradigm that enables models to identify spatial and temporal patterns by predicting future frames based on past frames. Traditional methods, which use recurrent neural networks to capture temporal patterns, have proven their effectiveness but come with high system complexity and computational demand. Convolutions could offer a more efficient alternative but are limited by their characteristic of treating all previous frames equally, resulting in poor temporal characterization, and by their local receptive field, limiting the capacity to capture distant correlations among frames. In this paper, we propose STLight, a novel method for spatio-temporal learning that relies solely on channel-wise and depth-wise convolutions as learnable layers. STLight overcomes the limitations of traditional convolutional approaches by rearranging spatial and temporal dimensions together, using a single convolution to mix both types of features into a comprehensive spatio-temporal patch representation. This representation is then processed in a purely convolutional framework, capable of focusing simultaneously on the interaction among near and distant patches, and subsequently allowing for efficient reconstruction of the predicted frames. Our architecture achieves state-of-the-art performance on STL benchmarks across different datasets and settings, while significantly improving computational efficiency in terms of parameters and computational FLOPs. The code is publicly available
ColorwAI: Generative Colorways of Textiles through GAN and Diffusion Disentanglement
Jul 16, 2024Colorway creation is the task of generating textile samples in alternate color variations maintaining an underlying pattern. The individuation of a suitable color palette for a colorway is a complex creative task, responding to client and market needs, stylistic and cultural specifications, and mood. We introduce a modification of this task, the "generative colorway" creation, that includes minimal shape modifications, and propose a framework, "ColorwAI", to tackle this task using color disentanglement on StyleGAN and Diffusion. We introduce a variation of the InterfaceGAN method for supervised disentanglement, ShapleyVec. We use Shapley values to subselect a few dimensions of the detected latent direction. Moreover, we introduce a general framework to adopt common disentanglement methods on any architecture with a semantic latent space and test it on Diffusion and GANs. We interpret the color representations within the models' latent space. We find StyleGAN's W space to be the most aligned with human notions of color. Finally, we suggest that disentanglement can solicit a creative system for colorway creation, and evaluate it through expert questionnaires and creativity theory.