 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Rethinking Image Evaluation in Super-Resolution
Mar 17, 2025While recent advancing image super-resolution (SR) techniques are continually improving the perceptual quality of their outputs, they can usually fail in quantitative evaluations. This inconsistency leads to a growing distrust in existing image metrics for SR evaluations. Though image evaluation depends on both the metric and the reference ground truth (GT), researchers typically do not inspect the role of GTs, as they are generally accepted as `perfect' references. However, due to the data being collected in the early years and the ignorance of controlling other types of distortions, we point out that GTs in existing SR datasets can exhibit relatively poor quality, which leads to biased evaluations. Following this observation, in this paper, we are interested in the following questions: Are GT images in existing SR datasets 100\% trustworthy for model evaluations? How does GT quality affect this evaluation? And how to make fair evaluations if there exist imperfect GTs? To answer these questions, this paper presents two main contributions. First, by systematically analyzing seven state-of-the-art SR models across three real-world SR datasets, we show that SR performances can be consistently affected across models by low-quality GTs, and models can perform quite differently when GT quality is controlled. Second, we propose a novel perceptual quality metric, Relative Quality Index (RQI), that measures the relative quality discrepancy of image pairs, thus issuing the biased evaluations caused by unreliable GTs. Our proposed model achieves significantly better consistency with human opinions. We expect our work to provide insights for the SR community on how future datasets, models, and metrics should be developed.
Adaptive Blind All-in-One Image Restoration
Nov 27, 2024Blind all-in-one image restoration models aim to recover a high-quality image from an input degraded with unknown distortions. However, these models require all the possible degradation types to be defined during the training stage while showing limited generalization to unseen degradations, which limits their practical application in complex cases. In this paper, we propose a simple but effective adaptive blind all-in-one restoration (ABAIR) model, which can address multiple degradations, generalizes well to unseen degradations, and efficiently incorporate new degradations by training a small fraction of parameters. First, we train our baseline model on a large dataset of natural images with multiple synthetic degradations, augmented with a segmentation head to estimate per-pixel degradation types, resulting in a powerful backbone able to generalize to a wide range of degradations. Second, we adapt our baseline model to varying image restoration tasks using independent low-rank adapters. Third, we learn to adaptively combine adapters to versatile images via a flexible and lightweight degradation estimator. Our model is both powerful in handling specific distortions and flexible in adapting to complex tasks, it not only outperforms the state-of-the-art by a large margin on five- and three-task IR setups, but also shows improved generalization to unseen degradations and also composite distortions.
Fine-grained subjective visual quality assessment for high-fidelity compressed images
Oct 12, 2024Advances in image compression, storage, and display technologies have made high-quality images and videos widely accessible. At this level of quality, distinguishing between compressed and original content becomes difficult, highlighting the need for assessment methodologies that are sensitive to even the smallest visual quality differences. Conventional subjective visual quality assessments often use absolute category rating scales, ranging from ``excellent'' to ``bad''. While suitable for evaluating more pronounced distortions, these scales are inadequate for detecting subtle visual differences. The JPEG standardization project AIC is currently developing a subjective image quality assessment methodology for high-fidelity images. This paper presents the proposed assessment methods, a dataset of high-quality compressed images, and their corresponding crowdsourced visual quality ratings. It also outlines a data analysis approach that reconstructs quality scale values in just noticeable difference (JND) units. The assessment method uses boosting techniques on visual stimuli to help observers detect compression artifacts more clearly. This is followed by a rescaling process that adjusts the boosted quality values back to the original perceptual scale. This reconstruction yields a fine-grained, high-precision quality scale in JND units, providing more informative results for practical applications. The dataset and code to reproduce the results will be available at https://github.com/jpeg-aic/dataset-BTC-PTC-24.
KonX: Cross-Resolution Image Quality Assessment
Dec 12, 2022Scale-invariance is an open problem in many computer vision subfields. For example, object labels should remain constant across scales, yet model predictions diverge in many cases. This problem gets harder for tasks where the ground-truth labels change with the presentation scale. In image quality assessment (IQA), downsampling attenuates impairments, e.g., blurs or compression artifacts, which can positively affect the impression evoked in subjective studies. To accurately predict perceptual image quality, cross-resolution IQA methods must therefore account for resolution-dependent errors induced by model inadequacies as well as for the perceptual label shifts in the ground truth. We present the first study of its kind that disentangles and examines the two issues separately via KonX, a novel, carefully crafted cross-resolution IQA database. This paper contributes the following: 1. Through KonX, we provide empirical evidence of label shifts caused by changes in the presentation resolution. 2. We show that objective IQA methods have a scale bias, which reduces their predictive performance. 3. We propose a multi-scale and multi-column DNN architecture that improves performance over previous state-of-the-art IQA models for this task, including recent transformers. We thus both raise and address a novel research problem in image quality assessment.
Going the Extra Mile in Face Image Quality Assessment: A Novel Database and Model
Jul 11, 2022
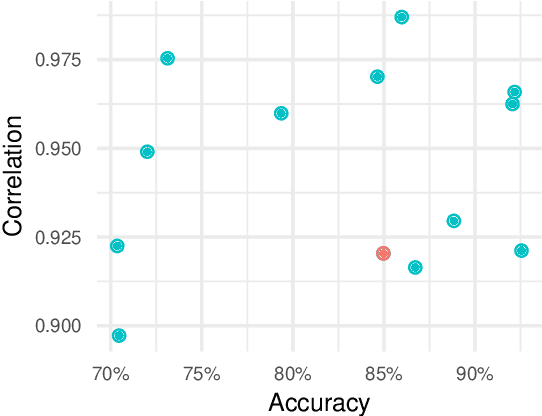

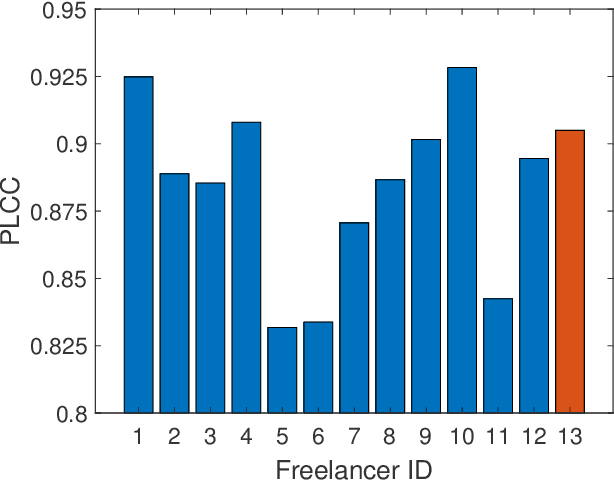
Computer vision models for image quality assessment (IQA) predict the subjective effect of generic image degradation, such as artefacts, blurs, bad exposure, or colors. The scarcity of face images in existing IQA datasets (below 10\%) is limiting the precision of IQA required for accurately filtering low-quality face images or guiding CV models for face image processing, such as super-resolution, image enhancement, and generation. In this paper, we first introduce the largest annotated IQA database to date that contains 20,000 human faces (an order of magnitude larger than all existing rated datasets of faces), of diverse individuals, in highly varied circumstances, quality levels, and distortion types. Based on the database, we further propose a novel deep learning model, which re-purposes generative prior features for predicting subjective face quality. By exploiting rich statistics encoded in well-trained generative models, we obtain generative prior information of the images and serve them as latent references to facilitate the blind IQA task. Experimental results demonstrate the superior prediction accuracy of the proposed model on the face IQA task.
Exploring and Evaluating Image Restoration Potential in Dynamic Scenes
Mar 23, 2022



In dynamic scenes, images often suffer from dynamic blur due to superposition of motions or low signal-noise ratio resulted from quick shutter speed when avoiding motions. Recovering sharp and clean results from the captured images heavily depends on the ability of restoration methods and the quality of the input. Although existing research on image restoration focuses on developing models for obtaining better restored results, fewer have studied to evaluate how and which input image leads to superior restored quality. In this paper, to better study an image's potential value that can be explored for restoration, we propose a novel concept, referring to image restoration potential (IRP). Specifically, We first establish a dynamic scene imaging dataset containing composite distortions and applied image restoration processes to validate the rationality of the existence to IRP. Based on this dataset, we investigate several properties of IRP and propose a novel deep model to accurately predict IRP values. By gradually distilling and selective fusing the degradation features, the proposed model shows its superiority in IRP prediction. Thanks to the proposed model, we are then able to validate how various image restoration related applications are benefited from IRP prediction. We show the potential usages of IRP as a filtering principle to select valuable frames, an auxiliary guidance to improve restoration models, and even an indicator to optimize camera settings for capturing better images under dynamic scenarios.
Learning Depth via Leveraging Semantics: Self-supervised Monocular Depth Estimation with Both Implicit and Explicit Semantic Guidance
Feb 11, 2021
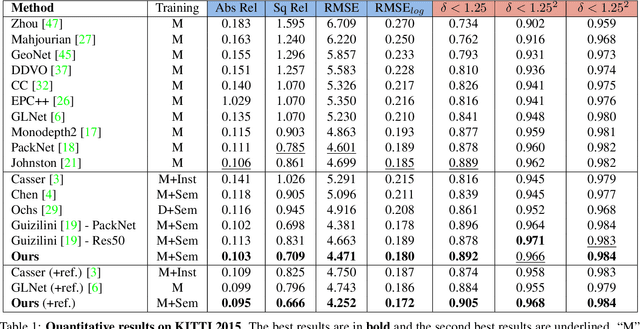
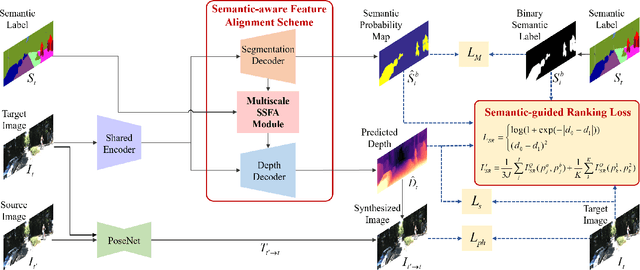

Self-supervised depth estimation has made a great success in learning depth from unlabeled image sequences. While the mappings between image and pixel-wise depth are well-studied in current methods, the correlation between image, depth and scene semantics, however, is less considered. This hinders the network to better understand the real geometry of the scene, since the contextual clues, contribute not only the latent representations of scene depth, but also the straight constraints for depth map. In this paper, we leverage the two benefits by proposing the implicit and explicit semantic guidance for accurate self-supervised depth estimation. We propose a Semantic-aware Spatial Feature Alignment (SSFA) scheme to effectively align implicit semantic features with depth features for scene-aware depth estimation. We also propose a semantic-guided ranking loss to explicitly constrain the estimated depth maps to be consistent with real scene contextual properties. Both semantic label noise and prediction uncertainty is considered to yield reliable depth supervisions. Extensive experimental results show that our method produces high quality depth maps which are consistently superior either on complex scenes or diverse semantic categories, and outperforms the state-of-the-art methods by a significant margin.