 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained HDR Image Quality Assessment From Noticeably Distorted to Very High Fidelity
Jun 14, 2025High dynamic range (HDR) and wide color gamut (WCG) technologies significantly improve color reproduction compared to standard dynamic range (SDR) and standard color gamuts, resulting in more accurate, richer, and more immersive images. However, HDR increases data demands, posing challenges for bandwidth efficiency and compression techniques. Advances in compression and display technologies require more precise image quality assessment, particularly in the high-fidelity range where perceptual differences are subtle. To address this gap, we introduce AIC-HDR2025, the first such HDR dataset, comprising 100 test images generated from five HDR sources, each compressed using four codecs at five compression levels. It covers the high-fidelity range, from visible distortions to compression levels below the visually lossless threshold. A subjective study was conducted using the JPEG AIC-3 test methodology, combining plain and boosted triplet comparisons. In total, 34,560 ratings were collected from 151 participants across four fully controlled labs. The results confirm that AIC-3 enables precise HDR quality estimation, with 95\% confidence intervals averaging a width of 0.27 at 1 JND. In addition, several recently proposed objective metrics were evaluated based on their correlation with subjective ratings. The dataset is publicly available.
Subjective Visual Quality Assessment for High-Fidelity Learning-Based Image Compression
Apr 10, 2025Learning-based image compression methods have recently emerged as promising alternatives to traditional codecs, offering improved rate-distortion performance and perceptual quality. JPEG AI represents the latest standardized framework in this domain, leveraging deep neural networks for high-fidelity image reconstruction. In this study, we present a comprehensive subjective visual quality assessment of JPEG AI-compressed images using the JPEG AIC-3 methodology, which quantifies perceptual differences in terms of Just Noticeable Difference (JND) units. We generated a dataset of 50 compressed images with fine-grained distortion levels from five diverse sources. A large-scale crowdsourced experiment collected 96,200 triplet responses from 459 participants. We reconstructed JND-based quality scales using a unified model based on boosted and plain triplet comparisons. Additionally, we evaluated the alignment of multiple objective image quality metrics with human perception in the high-fidelity range. The CVVDP metric achieved the overall highest performance; however, most metrics including CVVDP were overly optimistic in predicting the quality of JPEG AI-compressed images. These findings emphasize the necessity for rigorous subjective evaluations in the development and benchmarking of modern image codecs, particularly in the high-fidelity range. Another technical contribution is the introduction of the well-known Meng-Rosenthal-Rubin statistical test to the field of Quality of Experience research. This test can reliably assess the significance of difference in performance of quality metrics in terms of correlation between metrics and ground truth. The complete dataset, including all subjective scores, is publicly available at https://github.com/jpeg-aic/dataset-JPEG-AI-SDR25.
Fine-grained subjective visual quality assessment for high-fidelity compressed images
Oct 12, 2024Advances in image compression, storage, and display technologies have made high-quality images and videos widely accessible. At this level of quality, distinguishing between compressed and original content becomes difficult, highlighting the need for assessment methodologies that are sensitive to even the smallest visual quality differences. Conventional subjective visual quality assessments often use absolute category rating scales, ranging from ``excellent'' to ``bad''. While suitable for evaluating more pronounced distortions, these scales are inadequate for detecting subtle visual differences. The JPEG standardization project AIC is currently developing a subjective image quality assessment methodology for high-fidelity images. This paper presents the proposed assessment methods, a dataset of high-quality compressed images, and their corresponding crowdsourced visual quality ratings. It also outlines a data analysis approach that reconstructs quality scale values in just noticeable difference (JND) units. The assessment method uses boosting techniques on visual stimuli to help observers detect compression artifacts more clearly. This is followed by a rescaling process that adjusts the boosted quality values back to the original perceptual scale. This reconstruction yields a fine-grained, high-precision quality scale in JND units, providing more informative results for practical applications. The dataset and code to reproduce the results will be available at https://github.com/jpeg-aic/dataset-BTC-PTC-24.
Perceptual impact of the loss function on deep-learning image coding performance
Nov 10, 2023

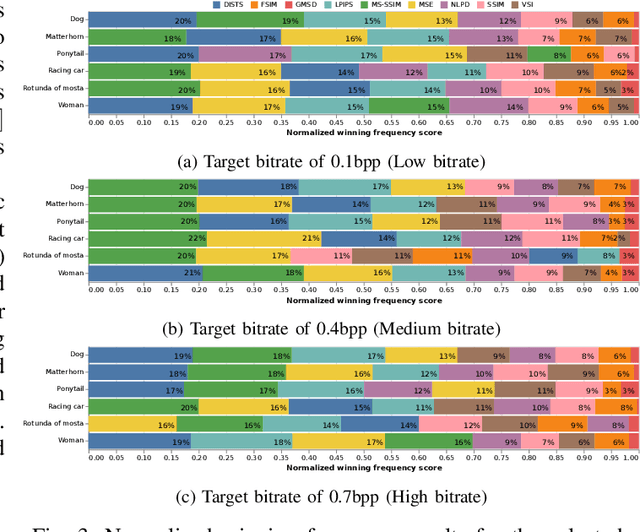

Nowadays, deep-learning image coding solutions have shown similar or better compression efficiency than conventional solutions based on hand-crafted transforms and spatial prediction techniques. These deep-learning codecs require a large training set of images and a training methodology to obtain a suitable model (set of parameters) for efficient compression. The training is performed with an optimization algorithm which provides a way to minimize the loss function. Therefore, the loss function plays a key role in the overall performance and includes a differentiable quality metric that attempts to mimic human perception. The main objective of this paper is to study the perceptual impact of several image quality metrics that can be used in the loss function of the training process, through a crowdsourcing subjective image quality assessment study. From this study, it is possible to conclude that the choice of the quality metric is critical for the perceptual performance of the deep-learning codec and that can vary depending on the image content.