 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained HDR Image Quality Assessment From Noticeably Distorted to Very High Fidelity
Jun 14, 2025



High dynamic range (HDR) and wide color gamut (WCG) technologies significantly improve color reproduction compared to standard dynamic range (SDR) and standard color gamuts, resulting in more accurate, richer, and more immersive images. However, HDR increases data demands, posing challenges for bandwidth efficiency and compression techniques. Advances in compression and display technologies require more precise image quality assessment, particularly in the high-fidelity range where perceptual differences are subtle. To address this gap, we introduce AIC-HDR2025, the first such HDR dataset, comprising 100 test images generated from five HDR sources, each compressed using four codecs at five compression levels. It covers the high-fidelity range, from visible distortions to compression levels below the visually lossless threshold. A subjective study was conducted using the JPEG AIC-3 test methodology, combining plain and boosted triplet comparisons. In total, 34,560 ratings were collected from 151 participants across four fully controlled labs. The results confirm that AIC-3 enables precise HDR quality estimation, with 95\% confidence intervals averaging a width of 0.27 at 1 JND. In addition, several recently proposed objective metrics were evaluated based on their correlation with subjective ratings. The dataset is publicly available.
Pose-invariant face recognition via feature-space pose frontalization
May 22, 2025Pose-invariant face recognition has become a challenging problem for modern AI-based face recognition systems. It aims at matching a profile face captured in the wild with a frontal face registered in a database. Existing methods perform face frontalization via either generative models or learning a pose robust feature representation. In this paper, a new method is presented to perform face frontalization and recognition within the feature space. First, a novel feature space pose frontalization module (FSPFM) is proposed to transform profile images with arbitrary angles into frontal counterparts. Second, a new training paradigm is proposed to maximize the potential of FSPFM and boost its performance. The latter consists of a pre-training and an attention-guided fine-tuning stage. Moreover, extensive experiments have been conducted on five popular face recognition benchmarks. Results show that not only our method outperforms the state-of-the-art in the pose-invariant face recognition task but also maintains superior performance in other standard scenarios.
Fine-grained subjective visual quality assessment for high-fidelity compressed images
Oct 12, 2024Advances in image compression, storage, and display technologies have made high-quality images and videos widely accessible. At this level of quality, distinguishing between compressed and original content becomes difficult, highlighting the need for assessment methodologies that are sensitive to even the smallest visual quality differences. Conventional subjective visual quality assessments often use absolute category rating scales, ranging from ``excellent'' to ``bad''. While suitable for evaluating more pronounced distortions, these scales are inadequate for detecting subtle visual differences. The JPEG standardization project AIC is currently developing a subjective image quality assessment methodology for high-fidelity images. This paper presents the proposed assessment methods, a dataset of high-quality compressed images, and their corresponding crowdsourced visual quality ratings. It also outlines a data analysis approach that reconstructs quality scale values in just noticeable difference (JND) units. The assessment method uses boosting techniques on visual stimuli to help observers detect compression artifacts more clearly. This is followed by a rescaling process that adjusts the boosted quality values back to the original perceptual scale. This reconstruction yields a fine-grained, high-precision quality scale in JND units, providing more informative results for practical applications. The dataset and code to reproduce the results will be available at https://github.com/jpeg-aic/dataset-BTC-PTC-24.
Towards A Comprehensive Visual Saliency Explanation Framework for AI-based Face Recognition Systems
Jul 08, 2024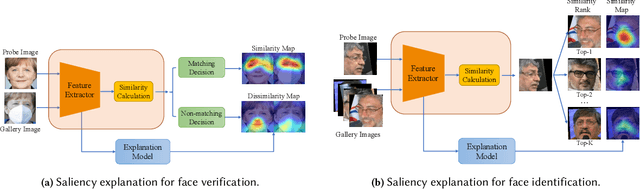
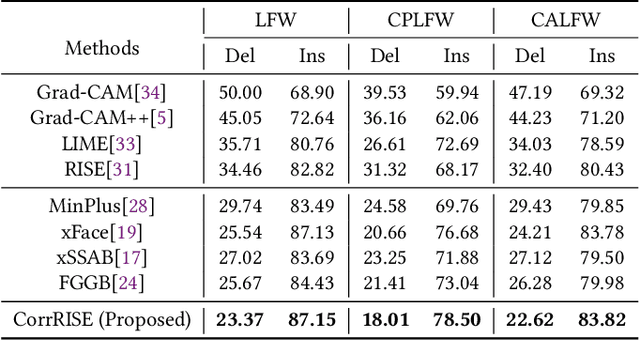
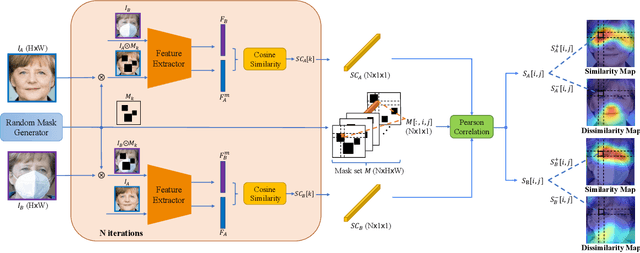
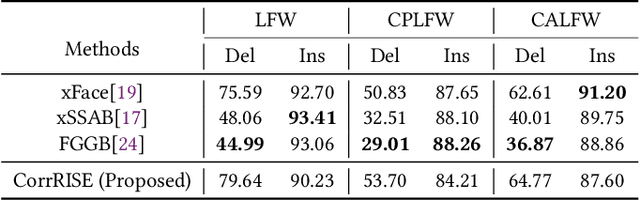
Over recent years, deep convolutional neural networks have significantly advanced the field of face recognition techniques for both verification and identification purposes. Despite the impressive accuracy, these neural networks are often criticized for lacking explainability. There is a growing demand for understanding the decision-making process of AI-based face recognition systems. Some studies have investigated the use of visual saliency maps as explanations, but they have predominantly focused on the specific face verification case. The discussion on more general face recognition scenarios and the corresponding evaluation methodology for these explanations have long been absent in current research. Therefore, this manuscript conceives a comprehensive explanation framework for face recognition tasks. Firstly, an exhaustive definition of visual saliency map-based explanations for AI-based face recognition systems is provided, taking into account the two most common recognition situations individually, i.e., face verification and identification. Secondly, a new model-agnostic explanation method named CorrRISE is proposed to produce saliency maps, which reveal both the similar and dissimilar regions between any given face images. Subsequently, the explanation framework conceives a new evaluation methodology that offers quantitative measurement and comparison of the performance of general visual saliency explanation methods in face recognition. Consequently, extensive experiments are carried out on multiple verification and identification scenarios. The results showcase that CorrRISE generates insightful saliency maps and demonstrates superior performance, particularly in similarity maps in comparison with the state-of-the-art explanation approaches.
Explainable Face Verification via Feature-Guided Gradient Backpropagation
Mar 07, 2024Recent years have witnessed significant advancement in face recognition (FR) techniques, with their applications widely spread in people's lives and security-sensitive areas. There is a growing need for reliable interpretations of decisions of such systems. Existing studies relying on various mechanisms have investigated the usage of saliency maps as an explanation approach, but suffer from different limitations. This paper first explores the spatial relationship between face image and its deep representation via gradient backpropagation. Then a new explanation approach FGGB has been conceived, which provides precise and insightful similarity and dissimilarity saliency maps to explain the "Accept" and "Reject" decision of an FR system. Extensive visual presentation and quantitative measurement have shown that FGGB achieves superior performance in both similarity and dissimilarity maps when compared to current state-of-the-art explainable face verification approaches.
Assessing objective quality metrics for JPEG and MPEG point cloud coding
Mar 01, 2024



As applications using immersive media gain increasing attention from both academia and industry, research in the field of point cloud compression has greatly intensified in recent years, leading to the development of the MPEG compression standards V-PCC and G-PCC, as well as the more recent JPEG Pleno learning-based point cloud coding. Each of the above-mentioned standards is based on a different algorithm, introducing distinct types of degradation that may impair the quality of experience when high lossy compression is applied. Although the impact on perceptual quality could be accurately evaluated during subjective quality assessment experiments, objective quality metrics serve as predictors of the visually perceived quality and provide similarity scores without human intervention. Nevertheless, their accuracy can be susceptible to the characteristics of the evaluated media as well as to the type and intensity of the added distortion. While the performance of multiple state-of-the-art objective quality metrics has already been evaluated through their correlation with subjective scores obtained in the presence of artifacts produced by the MPEG standards, no study has evaluated how metrics perform with the more recent JPEG Pleno point cloud coding. In this paper, a study is conducted to benchmark the performance of a large set of objective quality metrics in a subjective dataset including distortions produced by JPEG and MPEG codecs. The dataset also contains three different trade-offs between color and geometry compression for each codec, adding another dimension to the analysis. Performance indexes are computed over the entire dataset but also after splitting according to the codec and to the original model, resulting in detailed insights about the overall performance of each visual quality predictor as well as their cross-content and cross-codec generalization ability.
Towards the Detection of AI-Synthesized Human Face Images
Feb 13, 2024Over the past years, image generation and manipulation have achieved remarkable progress due to the rapid development of generative AI based on deep learning. Recent studies have devoted significant efforts to address the problem of face image manipulation caused by deepfake techniques. However, the problem of detecting purely synthesized face images has been explored to a lesser extent. In particular, the recent popular Diffusion Models (DMs) have shown remarkable success in image synthesis. Existing detectors struggle to generalize between synthesized images created by different generative models. In this work, a comprehensive benchmark including human face images produced by Generative Adversarial Networks (GANs) and a variety of DMs has been established to evaluate both the generalization ability and robustness of state-of-the-art detectors. Then, the forgery traces introduced by different generative models have been analyzed in the frequency domain to draw various insights. The paper further demonstrates that a detector trained with frequency representation can generalize well to other unseen generative models.
Subjective performance evaluation of bitrate allocation strategies for MPEG and JPEG Pleno point cloud compression
Feb 08, 2024The recent rise in interest in point clouds as an imaging modality has motivated standardization groups such as MPEG and JPEG Pleno to launch activities aiming at developing compression standards for point clouds. Lossy compression usually introduces visual artifacts that negatively impact the perceived quality of media, which can only be reliably measured through subjective visual quality assessment experiments. While MPEG standards have been subjectively evaluated in previous studies on multiple occasions, no work has yet assessed the performance of the recent JPEG Pleno standard in comparison to them. In this study, a comprehensive performance evaluation of MPEG and JPEG Pleno standards for point cloud compression is conducted. The impact of different configuration parameters on the performance of the codecs is first analyzed with the help of objective quality metrics. The results from this analysis are used to define three rate allocation strategies for each codec, which are employed to compress a set of point clouds at four target rates. The set of distorted point clouds is then subjectively evaluated following two subjective quality assessment protocols. Finally, the obtained results are used to compare the performance of these compression standards and draw insights about best coding practices.
Technical description of the EPFL submission to the JPEG DNA CfP
Dec 01, 2023



This document provides a technical description of the codec proposed by EPFL to the JPEG DNA Call for Proposals. The codec we refer to as V-DNA for its versatility, enables the encoding of raw images and already compressed JPEG 1 bitstreams, but the underlying algorithm could be used to encode and transcode any kind of data. The codec is composed of two main modules: the image compression module, handled by the state-of-the-art JPEG XL codec, and the DNA encoding module, implemented using a modified Raptor Code implementation following the RU10 (Raptor Unsystematic) description. The code for encoding and decoding, as well as the objective metrics results, plots and biochemical constraints analysis are available on ISO Documents system with document number WG1M101013-ICQ-EPFL submission to the JPEG DNA CfP.
Discriminative Deep Feature Visualization for Explainable Face Recognition
Jun 01, 2023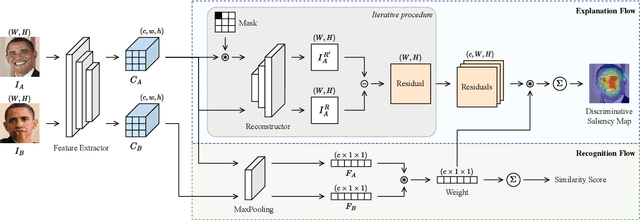
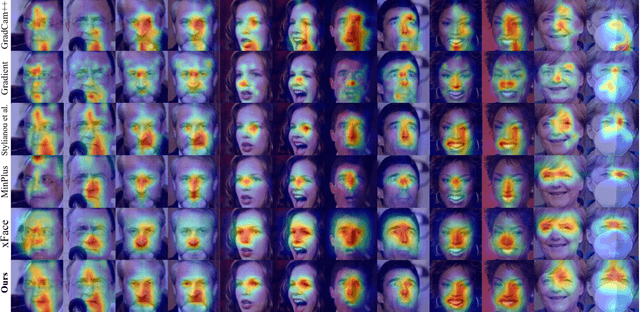
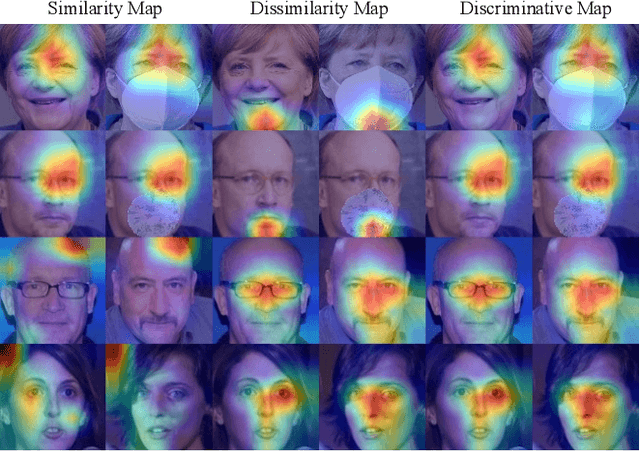
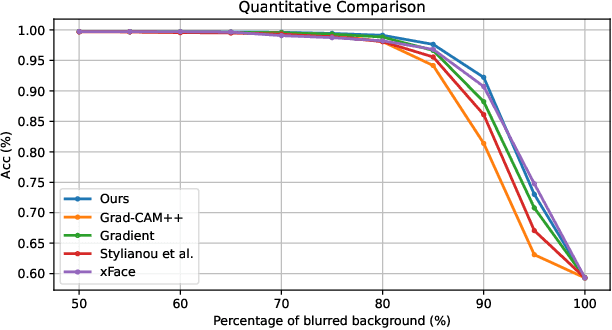
Despite the huge success of deep convolutional neural networks in face recognition (FR) tasks, current methods lack explainability for their predictions because of their "black-box" nature. In recent years, studies have been carried out to give an interpretation of the decision of a deep FR system. However, the affinity between the input facial image and the extracted deep features has not been explored. This paper contributes to the problem of explainable face recognition by first conceiving a face reconstruction-based explanation module, which reveals the correspondence between the deep feature and the facial regions. To further interpret the decision of an FR model, a novel visual saliency explanation algorithm has been proposed. It provides insightful explanation by producing visual saliency maps that represent similar and dissimilar regions between input faces. A detailed analysis has been presented for the generated visual explanation to show the effectiveness of the proposed method.