 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveCombo: Benchmarking Compositional Traffic Rule Reasoning in Autonomous Driving
Mar 02, 2026Multimodal Large Language Models (MLLMs) are rapidly becoming the intelligence brain of end-to-end autonomous driving systems. A key challenge is to assess whether MLLMs can truly understand and follow complex real-world traffic rules. However, existing benchmarks mainly focus on single-rule scenarios like traffic sign recognition, neglecting the complexity of multi-rule concurrency and conflicts in real driving. Consequently, models perform well on simple tasks but often fail or violate rules in real world complex situations. To bridge this gap, we propose DriveCombo, a text and vision-based benchmark for compositional traffic rule reasoning. Inspired by human drivers' cognitive development, we propose a systematic Five-Level Cognitive Ladder that evaluates reasoning from single-rule understanding to multi-rule integration and conflict resolution, enabling quantitative assessment across cognitive stages. We further propose a Rule2Scene Agent that maps language-based traffic rules to dynamic driving scenes through rule crafting and scene generation, enabling scene-level traffic rule visual reasoning. Evaluations of 14 mainstream MLLMs reveal performance drops as task complexity grows, particularly during rule conflicts. After splitting the dataset and fine-tuning on the training set, we further observe substantial improvements in both traffic rule reasoning and downstream planning capabilities. These results highlight the effectiveness of DriveCombo in advancing compliant and intelligent autonomous driving systems.
LLM for Large-Scale Optimization Model Auto-Formulation: A Lightweight Few-Shot Learning Approach
Jan 14, 2026Large-scale optimization is a key backbone of modern business decision-making. However, building these models is often labor-intensive and time-consuming. We address this by proposing LEAN-LLM-OPT, a LightwEight AgeNtic workflow construction framework for LLM-assisted large-scale OPTimization auto-formulation. LEAN-LLM-OPT takes as input a problem description together with associated datasets and orchestrates a team of LLM agents to produce an optimization formulation. Specifically, upon receiving a query, two upstream LLM agents dynamically construct a workflow that specifies, step-by-step, how optimization models for similar problems can be formulated. A downstream LLM agent then follows this workflow to generate the final output. Leveraging LLMs' text-processing capabilities and common modeling practices, the workflow decomposes the modeling task into a sequence of structured sub-tasks and offloads mechanical data-handling operations to auxiliary tools. This design alleviates the downstream agent's burden related to planning and data handling, allowing it to focus on the most challenging components that cannot be readily standardized. Extensive simulations show that LEAN-LLM-OPT, instantiated with GPT-4.1 and the open source gpt-oss-20B, achieves strong performance on large-scale optimization modeling tasks and is competitive with state-of-the-art approaches. In addition, in a Singapore Airlines choice-based revenue management use case, LEAN-LLM-OPT demonstrates practical value by achieving leading performance across a range of scenarios. Along the way, we introduce Large-Scale-OR and Air-NRM, the first comprehensive benchmarks for large-scale optimization auto-formulation. The code and data of this work is available at https://github.com/CoraLiang01/lean-llm-opt.
OT-ALD: Aligning Latent Distributions with Optimal Transport for Accelerated Image-to-Image Translation
Nov 14, 2025The Dual Diffusion Implicit Bridge (DDIB) is an emerging image-to-image (I2I) translation method that preserves cycle consistency while achieving strong flexibility. It links two independently trained diffusion models (DMs) in the source and target domains by first adding noise to a source image to obtain a latent code, then denoising it in the target domain to generate the translated image. However, this method faces two key challenges: (1) low translation efficiency, and (2) translation trajectory deviations caused by mismatched latent distributions. To address these issues, we propose a novel I2I translation framework, OT-ALD, grounded in optimal transport (OT) theory, which retains the strengths of DDIB-based approach. Specifically, we compute an OT map from the latent distribution of the source domain to that of the target domain, and use the mapped distribution as the starting point for the reverse diffusion process in the target domain. Our error analysis confirms that OT-ALD eliminates latent distribution mismatches. Moreover, OT-ALD effectively balances faster image translation with improved image quality. Experiments on four translation tasks across three high-resolution datasets show that OT-ALD improves sampling efficiency by 20.29% and reduces the FID score by 2.6 on average compared to the top-performing baseline models.
Mitigating Message Imbalance in Fraud Detection with Dual-View Graph Representation Learning
Jul 09, 2025Graph representation learning has become a mainstream method for fraud detection due to its strong expressive power, which focuses on enhancing node representations through improved neighborhood knowledge capture. However, the focus on local interactions leads to imbalanced transmission of global topological information and increased risk of node-specific information being overwhelmed during aggregation due to the imbalance between fraud and benign nodes. In this paper, we first summarize the impact of topology and class imbalance on downstream tasks in GNN-based fraud detection, as the problem of imbalanced supervisory messages is caused by fraudsters' topological behavior obfuscation and identity feature concealment. Based on statistical validation, we propose a novel dual-view graph representation learning method to mitigate Message imbalance in Fraud Detection(MimbFD). Specifically, we design a topological message reachability module for high-quality node representation learning to penetrate fraudsters' camouflage and alleviate insufficient propagation. Then, we introduce a local confounding debiasing module to adjust node representations, enhancing the stable association between node representations and labels to balance the influence of different classes. Finally, we conducted experiments on three public fraud datasets, and the results demonstrate that MimbFD exhibits outstanding performance in fraud detection.
Pose-invariant face recognition via feature-space pose frontalization
May 22, 2025Pose-invariant face recognition has become a challenging problem for modern AI-based face recognition systems. It aims at matching a profile face captured in the wild with a frontal face registered in a database. Existing methods perform face frontalization via either generative models or learning a pose robust feature representation. In this paper, a new method is presented to perform face frontalization and recognition within the feature space. First, a novel feature space pose frontalization module (FSPFM) is proposed to transform profile images with arbitrary angles into frontal counterparts. Second, a new training paradigm is proposed to maximize the potential of FSPFM and boost its performance. The latter consists of a pre-training and an attention-guided fine-tuning stage. Moreover, extensive experiments have been conducted on five popular face recognition benchmarks. Results show that not only our method outperforms the state-of-the-art in the pose-invariant face recognition task but also maintains superior performance in other standard scenarios.
RenderWorld: World Model with Self-Supervised 3D Label
Sep 17, 2024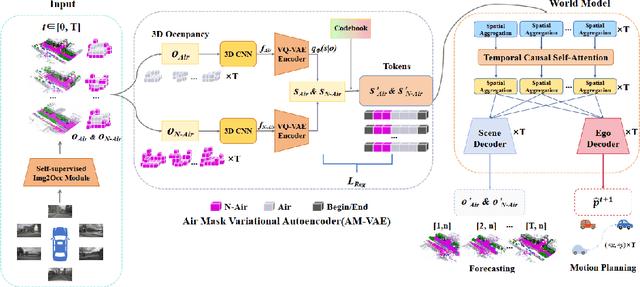

End-to-end autonomous driving with vision-only is not only more cost-effective compared to LiDAR-vision fusion but also more reliable than traditional methods. To achieve a economical and robust purely visual autonomous driving system, we propose RenderWorld, a vision-only end-to-end autonomous driving framework, which generates 3D occupancy labels using a self-supervised gaussian-based Img2Occ Module, then encodes the labels by AM-VAE, and uses world model for forecasting and planning. RenderWorld employs Gaussian Splatting to represent 3D scenes and render 2D images greatly improves segmentation accuracy and reduces GPU memory consumption compared with NeRF-based methods. By applying AM-VAE to encode air and non-air separately, RenderWorld achieves more fine-grained scene element representation, leading to state-of-the-art performance in both 4D occupancy forecasting and motion planning from autoregressive world model.
Can LVLMs Obtain a Driver's License? A Benchmark Towards Reliable AGI for Autonomous Driving
Sep 04, 2024Large Vision-Language Models (LVLMs) have recently garnered significant attention, with many efforts aimed at harnessing their general knowledge to enhance the interpretability and robustness of autonomous driving models. However, LVLMs typically rely on large, general-purpose datasets and lack the specialized expertise required for professional and safe driving. Existing vision-language driving datasets focus primarily on scene understanding and decision-making, without providing explicit guidance on traffic rules and driving skills, which are critical aspects directly related to driving safety. To bridge this gap, we propose IDKB, a large-scale dataset containing over one million data items collected from various countries, including driving handbooks, theory test data, and simulated road test data. Much like the process of obtaining a driver's license, IDKB encompasses nearly all the explicit knowledge needed for driving from theory to practice. In particular, we conducted comprehensive tests on 15 LVLMs using IDKB to assess their reliability in the context of autonomous driving and provided extensive analysis. We also fine-tuned popular models, achieving notable performance improvements, which further validate the significance of our dataset. The project page can be found at: \url{https://4dvlab.github.io/project_page/idkb.html}
Towards A Comprehensive Visual Saliency Explanation Framework for AI-based Face Recognition Systems
Jul 08, 2024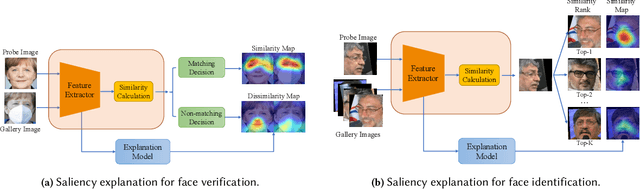
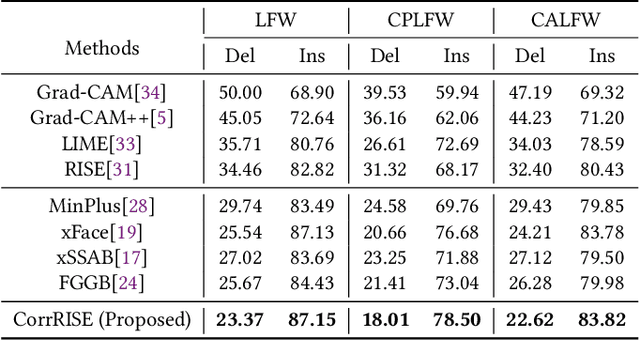
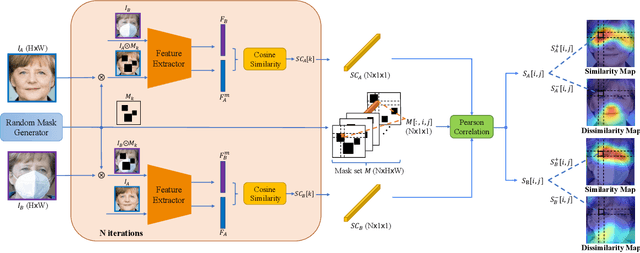
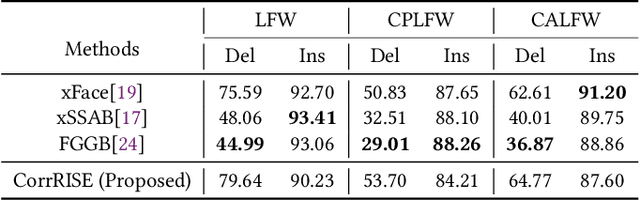
Over recent years, deep convolutional neural networks have significantly advanced the field of face recognition techniques for both verification and identification purposes. Despite the impressive accuracy, these neural networks are often criticized for lacking explainability. There is a growing demand for understanding the decision-making process of AI-based face recognition systems. Some studies have investigated the use of visual saliency maps as explanations, but they have predominantly focused on the specific face verification case. The discussion on more general face recognition scenarios and the corresponding evaluation methodology for these explanations have long been absent in current research. Therefore, this manuscript conceives a comprehensive explanation framework for face recognition tasks. Firstly, an exhaustive definition of visual saliency map-based explanations for AI-based face recognition systems is provided, taking into account the two most common recognition situations individually, i.e., face verification and identification. Secondly, a new model-agnostic explanation method named CorrRISE is proposed to produce saliency maps, which reveal both the similar and dissimilar regions between any given face images. Subsequently, the explanation framework conceives a new evaluation methodology that offers quantitative measurement and comparison of the performance of general visual saliency explanation methods in face recognition. Consequently, extensive experiments are carried out on multiple verification and identification scenarios. The results showcase that CorrRISE generates insightful saliency maps and demonstrates superior performance, particularly in similarity maps in comparison with the state-of-the-art explanation approaches.
Explainable Face Verification via Feature-Guided Gradient Backpropagation
Mar 07, 2024Recent years have witnessed significant advancement in face recognition (FR) techniques, with their applications widely spread in people's lives and security-sensitive areas. There is a growing need for reliable interpretations of decisions of such systems. Existing studies relying on various mechanisms have investigated the usage of saliency maps as an explanation approach, but suffer from different limitations. This paper first explores the spatial relationship between face image and its deep representation via gradient backpropagation. Then a new explanation approach FGGB has been conceived, which provides precise and insightful similarity and dissimilarity saliency maps to explain the "Accept" and "Reject" decision of an FR system. Extensive visual presentation and quantitative measurement have shown that FGGB achieves superior performance in both similarity and dissimilarity maps when compared to current state-of-the-art explainable face verification approaches.
Towards the Detection of AI-Synthesized Human Face Images
Feb 13, 2024Over the past years, image generation and manipulation have achieved remarkable progress due to the rapid development of generative AI based on deep learning. Recent studies have devoted significant efforts to address the problem of face image manipulation caused by deepfake techniques. However, the problem of detecting purely synthesized face images has been explored to a lesser extent. In particular, the recent popular Diffusion Models (DMs) have shown remarkable success in image synthesis. Existing detectors struggle to generalize between synthesized images created by different generative models. In this work, a comprehensive benchmark including human face images produced by Generative Adversarial Networks (GANs) and a variety of DMs has been established to evaluate both the generalization ability and robustness of state-of-the-art detectors. Then, the forgery traces introduced by different generative models have been analyzed in the frequency domain to draw various insights. The paper further demonstrates that a detector trained with frequency representation can generalize well to other unseen generative models.