 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTkvr: KV Cache Retrieval for Long-Context LLMs via Centroid then Token Indexing
Dec 17, 2025Large language models (LLMs) are increasingly applied in long-context scenarios such as multi-turn conversations. However, long contexts pose significant challenges for inference efficiency, including high memory overhead from Key-Value (KV) cache and increased latency due to excessive memory accesses. Recent methods for dynamic KV selection struggle with trade-offs: block-level indexing degrades accuracy by retrieving irrelevant KV entries, while token-level indexing incurs high latency from inefficient retrieval mechanisms. In this paper, we propose CTKVR, a novel centroid-then-token KV retrieval scheme that addresses these limitations. CTKVR leverages a key observation: query vectors adjacent in position exhibit high similarity after Rotary Position Embedding (RoPE) and share most of their top-k KV cache entries. Based on this insight, CTKVR employs a two-stage retrieval strategy: lightweight centroids are precomputed during prefilling for centroid-grained indexing, followed by token-level refinement for precise KV retrieval. This approach balances retrieval efficiency and accuracy. To further enhance performance, we implement an optimized system for indexing construction and search using CPU-GPU co-execution. Experimentally, CTKVR achieves superior performance across multiple benchmarks with less than 1% accuracy degradation. Meanwhile, CTKVR delivers 3 times and 4 times throughput speedups on Llama-3-8B and Yi-9B at 96K context length across diverse GPU hardware.
STAGE: A Stream-Centric Generative World Model for Long-Horizon Driving-Scene Simulation
Jun 16, 2025The generation of temporally consistent, high-fidelity driving videos over extended horizons presents a fundamental challenge in autonomous driving world modeling. Existing approaches often suffer from error accumulation and feature misalignment due to inadequate decoupling of spatio-temporal dynamics and limited cross-frame feature propagation mechanisms. To address these limitations, we present STAGE (Streaming Temporal Attention Generative Engine), a novel auto-regressive framework that pioneers hierarchical feature coordination and multi-phase optimization for sustainable video synthesis. To achieve high-quality long-horizon driving video generation, we introduce Hierarchical Temporal Feature Transfer (HTFT) and a novel multi-stage training strategy. HTFT enhances temporal consistency between video frames throughout the video generation process by modeling the temporal and denoising process separately and transferring denoising features between frames. The multi-stage training strategy is to divide the training into three stages, through model decoupling and auto-regressive inference process simulation, thereby accelerating model convergence and reducing error accumulation. Experiments on the Nuscenes dataset show that STAGE has significantly surpassed existing methods in the long-horizon driving video generation task. In addition, we also explored STAGE's ability to generate unlimited-length driving videos. We generated 600 frames of high-quality driving videos on the Nuscenes dataset, which far exceeds the maximum length achievable by existing methods.
Can LVLMs Obtain a Driver's License? A Benchmark Towards Reliable AGI for Autonomous Driving
Sep 04, 2024Large Vision-Language Models (LVLMs) have recently garnered significant attention, with many efforts aimed at harnessing their general knowledge to enhance the interpretability and robustness of autonomous driving models. However, LVLMs typically rely on large, general-purpose datasets and lack the specialized expertise required for professional and safe driving. Existing vision-language driving datasets focus primarily on scene understanding and decision-making, without providing explicit guidance on traffic rules and driving skills, which are critical aspects directly related to driving safety. To bridge this gap, we propose IDKB, a large-scale dataset containing over one million data items collected from various countries, including driving handbooks, theory test data, and simulated road test data. Much like the process of obtaining a driver's license, IDKB encompasses nearly all the explicit knowledge needed for driving from theory to practice. In particular, we conducted comprehensive tests on 15 LVLMs using IDKB to assess their reliability in the context of autonomous driving and provided extensive analysis. We also fine-tuned popular models, achieving notable performance improvements, which further validate the significance of our dataset. The project page can be found at: \url{https://4dvlab.github.io/project_page/idkb.html}
Towards Practical Human Motion Prediction with LiDAR Point Clouds
Aug 15, 2024



Human motion prediction is crucial for human-centric multimedia understanding and interacting. Current methods typically rely on ground truth human poses as observed input, which is not practical for real-world scenarios where only raw visual sensor data is available. To implement these methods in practice, a pre-phrase of pose estimation is essential. However, such two-stage approaches often lead to performance degradation due to the accumulation of errors. Moreover, reducing raw visual data to sparse keypoint representations significantly diminishes the density of information, resulting in the loss of fine-grained features. In this paper, we propose \textit{LiDAR-HMP}, the first single-LiDAR-based 3D human motion prediction approach, which receives the raw LiDAR point cloud as input and forecasts future 3D human poses directly. Building upon our novel structure-aware body feature descriptor, LiDAR-HMP adaptively maps the observed motion manifold to future poses and effectively models the spatial-temporal correlations of human motions for further refinement of prediction results. Extensive experiments show that our method achieves state-of-the-art performance on two public benchmarks and demonstrates remarkable robustness and efficacy in real-world deployments.
LiveHPS++: Robust and Coherent Motion Capture in Dynamic Free Environment
Jul 13, 2024



LiDAR-based human motion capture has garnered significant interest in recent years for its practicability in large-scale and unconstrained environments. However, most methods rely on cleanly segmented human point clouds as input, the accuracy and smoothness of their motion results are compromised when faced with noisy data, rendering them unsuitable for practical applications. To address these limitations and enhance the robustness and precision of motion capture with noise interference, we introduce LiveHPS++, an innovative and effective solution based on a single LiDAR system. Benefiting from three meticulously designed modules, our method can learn dynamic and kinematic features from human movements, and further enable the precise capture of coherent human motions in open settings, making it highly applicable to real-world scenarios. Through extensive experiments, LiveHPS++ has proven to significantly surpass existing state-of-the-art methods across various datasets, establishing a new benchmark in the field.
HUNTER: Unsupervised Human-centric 3D Detection via Transferring Knowledge from Synthetic Instances to Real Scenes
Mar 15, 2024



Human-centric 3D scene understanding has recently drawn increasing attention, driven by its critical impact on robotics. However, human-centric real-life scenarios are extremely diverse and complicated, and humans have intricate motions and interactions. With limited labeled data, supervised methods are difficult to generalize to general scenarios, hindering real-life applications. Mimicking human intelligence, we propose an unsupervised 3D detection method for human-centric scenarios by transferring the knowledge from synthetic human instances to real scenes. To bridge the gap between the distinct data representations and feature distributions of synthetic models and real point clouds, we introduce novel modules for effective instance-to-scene representation transfer and synthetic-to-real feature alignment. Remarkably, our method exhibits superior performance compared to current state-of-the-art techniques, achieving 87.8% improvement in mAP and closely approaching the performance of fully supervised methods (62.15 mAP vs. 69.02 mAP) on HuCenLife Dataset.
RealDex: Towards Human-like Grasping for Robotic Dexterous Hand
Feb 21, 2024



In this paper, we introduce RealDex, a pioneering dataset capturing authentic dexterous hand grasping motions infused with human behavioral patterns, enriched by multi-view and multimodal visual data. Utilizing a teleoperation system, we seamlessly synchronize human-robot hand poses in real time. This collection of human-like motions is crucial for training dexterous hands to mimic human movements more naturally and precisely. RealDex holds immense promise in advancing humanoid robot for automated perception, cognition, and manipulation in real-world scenarios. Moreover, we introduce a cutting-edge dexterous grasping motion generation framework, which aligns with human experience and enhances real-world applicability through effectively utilizing Multimodal Large Language Models. Extensive experiments have demonstrated the superior performance of our method on RealDex and other open datasets. The complete dataset and code will be made available upon the publication of this work.
Human-centric Scene Understanding for 3D Large-scale Scenarios
Jul 26, 2023



Human-centric scene understanding is significant for real-world applications, but it is extremely challenging due to the existence of diverse human poses and actions, complex human-environment interactions, severe occlusions in crowds, etc. In this paper, we present a large-scale multi-modal dataset for human-centric scene understanding, dubbed HuCenLife, which is collected in diverse daily-life scenarios with rich and fine-grained annotations. Our HuCenLife can benefit many 3D perception tasks, such as segmentation, detection, action recognition, etc., and we also provide benchmarks for these tasks to facilitate related research. In addition, we design novel modules for LiDAR-based segmentation and action recognition, which are more applicable for large-scale human-centric scenarios and achieve state-of-the-art performance.
Can Sophisticated Dispatching Strategy Acquired by Reinforcement Learning? - A Case Study in Dynamic Courier Dispatching System
Mar 07, 2019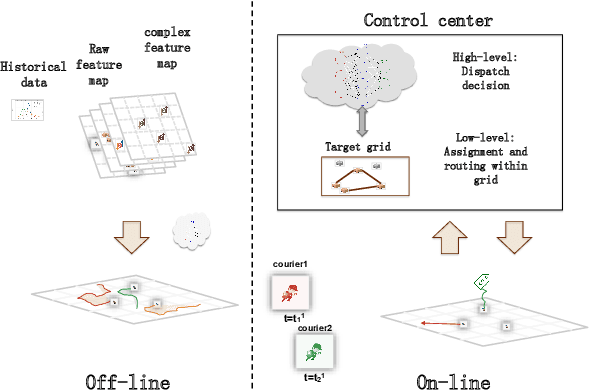

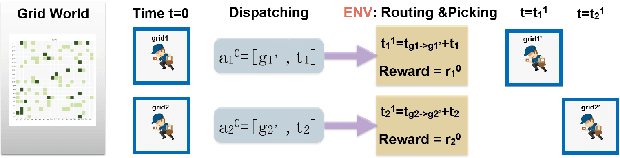
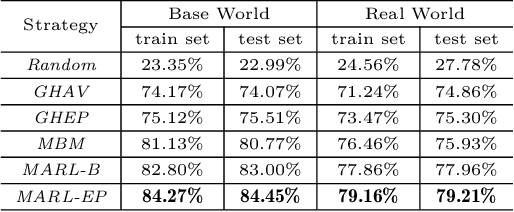
In this paper, we study a courier dispatching problem (CDP) raised from an online pickup-service platform of Alibaba. The CDP aims to assign a set of couriers to serve pickup requests with stochastic spatial and temporal arrival rate among urban regions. The objective is to maximize the revenue of served requests given a limited number of couriers over a period of time. Many online algorithms such as dynamic matching and vehicle routing strategy from existing literature could be applied to tackle this problem. However, these methods rely on appropriately predefined optimization objectives at each decision point, which is hard in dynamic situations. This paper formulates the CDP as a Markov decision process (MDP) and proposes a data-driven approach to derive the optimal dispatching rule-set under different scenarios. Our method stacks multi-layer images of the spatial-and-temporal map and apply multi-agent reinforcement learning (MARL) techniques to evolve dispatching models. This method solves the learning inefficiency caused by traditional centralized MDP modeling. Through comprehensive experiments on both artificial dataset and real-world dataset, we show: 1) By utilizing historical data and considering long-term revenue gains, MARL achieves better performance than myopic online algorithms; 2) MARL is able to construct the mapping between complex scenarios to sophisticated decisions such as the dispatching rule. 3) MARL has the scalability to adopt in large-scale real-world scenarios.