 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr3: Ask Large Language Models Not to Give Off-Topic Answers in Open Domain Multi-Hop Question Answering
Mar 19, 2024



Open Domain Multi-Hop Question Answering (ODMHQA) plays a crucial role in Natural Language Processing (NLP) by aiming to answer complex questions through multi-step reasoning over retrieved information from external knowledge sources. Recently, Large Language Models (LLMs) have demonstrated remarkable performance in solving ODMHQA owing to their capabilities including planning, reasoning, and utilizing tools. However, LLMs may generate off-topic answers when attempting to solve ODMHQA, namely the generated answers are irrelevant to the original questions. This issue of off-topic answers accounts for approximately one-third of incorrect answers, yet remains underexplored despite its significance. To alleviate this issue, we propose the Discriminate->Re-Compose->Re- Solve->Re-Decompose (Dr3) mechanism. Specifically, the Discriminator leverages the intrinsic capabilities of LLMs to judge whether the generated answers are off-topic. In cases where an off-topic answer is detected, the Corrector performs step-wise revisions along the reversed reasoning chain (Re-Compose->Re-Solve->Re-Decompose) until the final answer becomes on-topic. Experimental results on the HotpotQA and 2WikiMultiHopQA datasets demonstrate that our Dr3 mechanism considerably reduces the occurrence of off-topic answers in ODMHQA by nearly 13%, improving the performance in Exact Match (EM) by nearly 3% compared to the baseline method without the Dr3 mechanism.
An Online Algorithm for Chance Constrained Resource Allocation
Mar 06, 2023
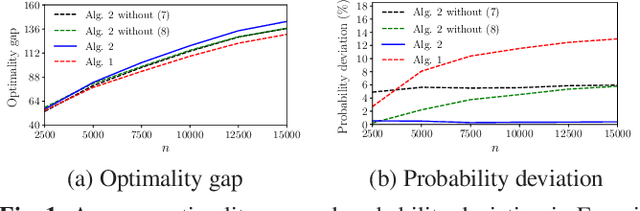
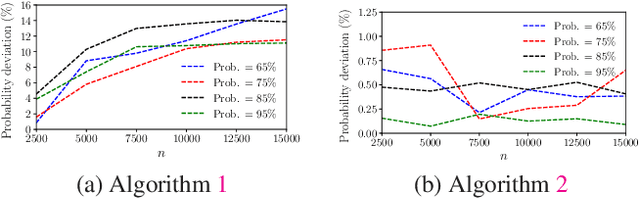
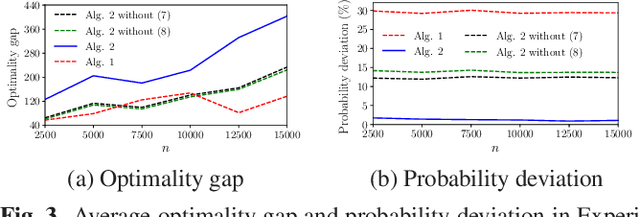
This paper studies the online stochastic resource allocation problem (RAP) with chance constraints. The online RAP is a 0-1 integer linear programming problem where the resource consumption coefficients are revealed column by column along with the corresponding revenue coefficients. When a column is revealed, the corresponding decision variables are determined instantaneously without future information. Moreover, in online applications, the resource consumption coefficients are often obtained by prediction. To model their uncertainties, we take the chance constraints into the consideration. To the best of our knowledge, this is the first time chance constraints are introduced in the online RAP problem. Assuming that the uncertain variables have known Gaussian distributions, the stochastic RAP can be transformed into a deterministic but nonlinear problem with integer second-order cone constraints. Next, we linearize this nonlinear problem and analyze the performance of vanilla online primal-dual algorithm for solving the linearized stochastic RAP. Under mild technical assumptions, the optimality gap and constraint violation are both on the order of $\sqrt{n}$. Then, to further improve the performance of the algorithm, several modified online primal-dual algorithms with heuristic corrections are proposed. Finally, extensive numerical experiments on both synthetic and real data demonstrate the applicability and effectiveness of our methods.
Can Sophisticated Dispatching Strategy Acquired by Reinforcement Learning? - A Case Study in Dynamic Courier Dispatching System
Mar 07, 2019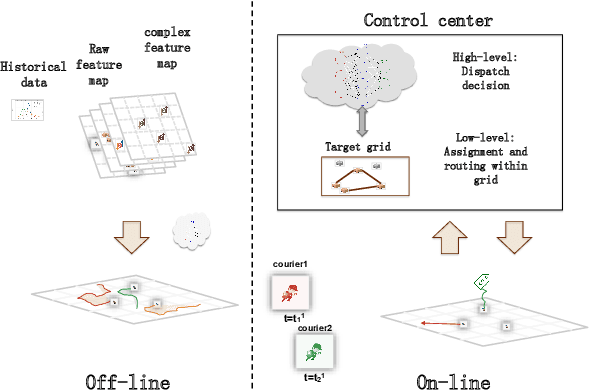

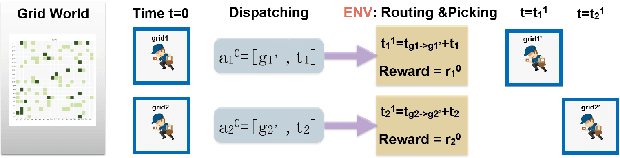
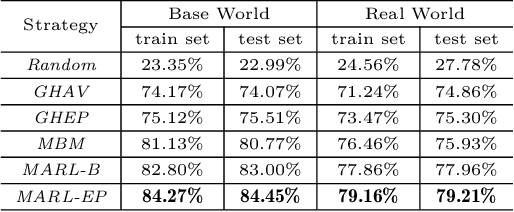
In this paper, we study a courier dispatching problem (CDP) raised from an online pickup-service platform of Alibaba. The CDP aims to assign a set of couriers to serve pickup requests with stochastic spatial and temporal arrival rate among urban regions. The objective is to maximize the revenue of served requests given a limited number of couriers over a period of time. Many online algorithms such as dynamic matching and vehicle routing strategy from existing literature could be applied to tackle this problem. However, these methods rely on appropriately predefined optimization objectives at each decision point, which is hard in dynamic situations. This paper formulates the CDP as a Markov decision process (MDP) and proposes a data-driven approach to derive the optimal dispatching rule-set under different scenarios. Our method stacks multi-layer images of the spatial-and-temporal map and apply multi-agent reinforcement learning (MARL) techniques to evolve dispatching models. This method solves the learning inefficiency caused by traditional centralized MDP modeling. Through comprehensive experiments on both artificial dataset and real-world dataset, we show: 1) By utilizing historical data and considering long-term revenue gains, MARL achieves better performance than myopic online algorithms; 2) MARL is able to construct the mapping between complex scenarios to sophisticated decisions such as the dispatching rule. 3) MARL has the scalability to adopt in large-scale real-world scenarios.