 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterveneBench: Benchmarking LLMs for Intervention Reasoning and Causal Study Design in Real Social Systems
Mar 16, 2026Causal inference in social science relies on end-to-end, intervention-centered research-design reasoning grounded in real-world policy interventions, but current benchmarks fail to evaluate this capability of large language models (LLMs). We present InterveneBench, a benchmark designed to assess such reasoning in realistic social settings. Each instance in InterveneBench is derived from an empirical social science study and requires models to reason about policy interventions and identification assumptions without access to predefined causal graphs or structural equations. InterveneBench comprises 744 peer-reviewed studies across diverse policy domains. Experimental results show that state-of-the-art LLMs struggle under this setting. To address this limitation, we further propose a multi-agent framework, STRIDES. It achieves significant performance improvements over state-of-the-art reasoning models. Our code and data are available at https://github.com/Sii-yuning/STRIDES.
Reflective Personalization Optimization: A Post-hoc Rewriting Framework for Black-Box Large Language Models
Nov 07, 2025The personalization of black-box large language models (LLMs) is a critical yet challenging task. Existing approaches predominantly rely on context injection, where user history is embedded into the prompt to directly guide the generation process. However, this single-step paradigm imposes a dual burden on the model: generating accurate content while simultaneously aligning with user-specific styles. This often results in a trade-off that compromises output quality and limits precise control. To address this fundamental tension, we propose Reflective Personalization Optimization (RPO), a novel framework that redefines the personalization paradigm by decoupling content generation from alignment. RPO operates in two distinct stages: first, a base model generates a high-quality, generic response; then, an external reflection module explicitly rewrites this output to align with the user's preferences. This reflection module is trained using a two-stage process. Initially, supervised fine-tuning is employed on structured rewriting trajectories to establish a core personalized reasoning policy that models the transformation from generic to user-aligned responses. Subsequently, reinforcement learning is applied to further refine and enhance the quality of the personalized outputs. Comprehensive experiments on the LaMP benchmark demonstrate that RPO, by decoupling content generation from personalization, significantly outperforms state-of-the-art baselines. These findings underscore the superiority of explicit response shaping over implicit context injection. Moreover, RPO introduces an efficient, model-agnostic personalization layer that can be seamlessly integrated with any underlying base model, paving the way for a new and effective direction in user-centric generation scenarios.
Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling
Jul 02, 2025Existing post-training techniques for large language models are broadly categorized into Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT). Each paradigm presents a distinct trade-off: SFT excels at mimicking demonstration data but can lead to problematic generalization as a form of behavior cloning. Conversely, RFT can significantly enhance a model's performance but is prone to learn unexpected behaviors, and its performance is highly sensitive to the initial policy. In this paper, we propose a unified view of these methods and introduce Prefix-RFT, a hybrid approach that synergizes learning from both demonstration and exploration. Using mathematical reasoning problems as a testbed, we empirically demonstrate that Prefix-RFT is both simple and effective. It not only surpasses the performance of standalone SFT and RFT but also outperforms parallel mixed-policy RFT methods. A key advantage is its seamless integration into existing open-source frameworks, requiring only minimal modifications to the standard RFT pipeline. Our analysis highlights the complementary nature of SFT and RFT, and validates that Prefix-RFT effectively harmonizes these two learning paradigms. Furthermore, ablation studies confirm the method's robustness to variations in the quality and quantity of demonstration data. We hope this work offers a new perspective on LLM post-training, suggesting that a unified paradigm that judiciously integrates demonstration and exploration could be a promising direction for future research.
AI2Agent: An End-to-End Framework for Deploying AI Projects as Autonomous Agents
Mar 31, 2025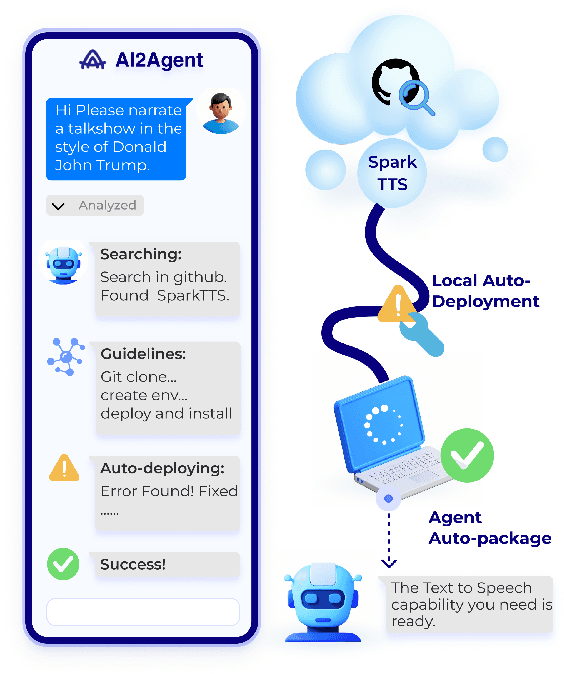
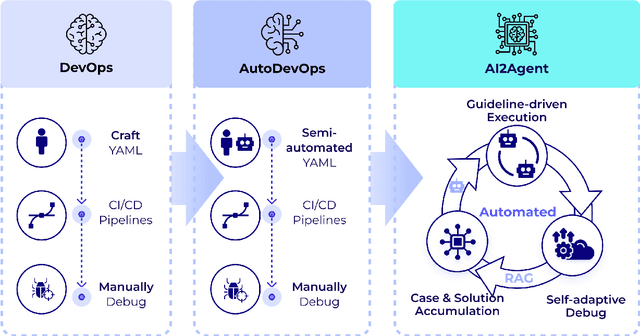
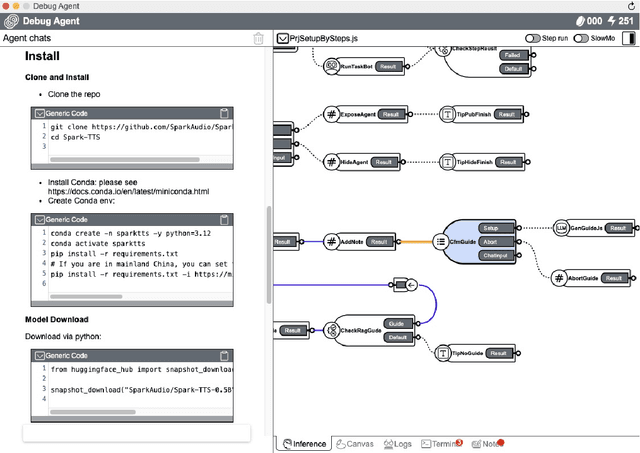
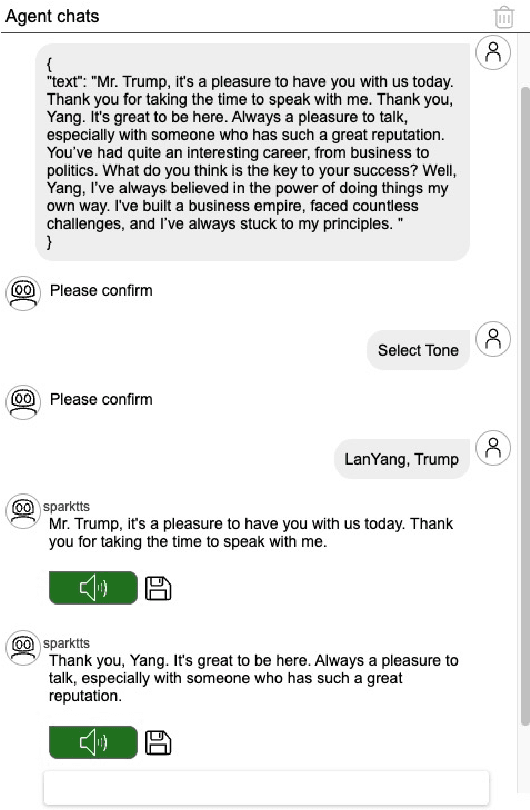
As AI technology advances, it is driving innovation across industries, increasing the demand for scalable AI project deployment. However, deployment remains a critical challenge due to complex environment configurations, dependency conflicts, cross-platform adaptation, and debugging difficulties, which hinder automation and adoption. This paper introduces AI2Agent, an end-to-end framework that automates AI project deployment through guideline-driven execution, self-adaptive debugging, and case \& solution accumulation. AI2Agent dynamically analyzes deployment challenges, learns from past cases, and iteratively refines its approach, significantly reducing human intervention. To evaluate its effectiveness, we conducted experiments on 30 AI deployment cases, covering TTS, text-to-image generation, image editing, and other AI applications. Results show that AI2Agent significantly reduces deployment time and improves success rates. The code and demo video are now publicly accessible.
Guess What I am Thinking: A Benchmark for Inner Thought Reasoning of Role-Playing Language Agents
Mar 11, 2025

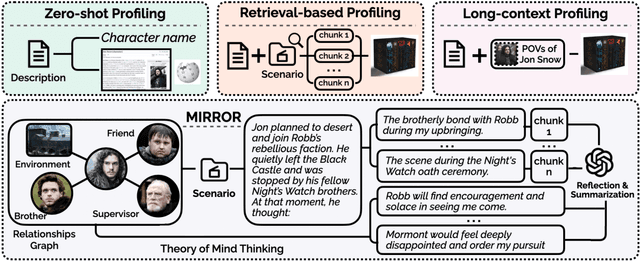
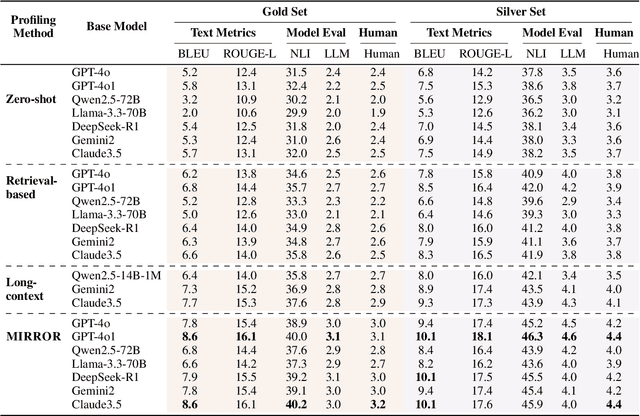
Recent advances in LLM-based role-playing language agents (RPLAs) have attracted broad attention in various applications. While chain-of-thought reasoning has shown importance in many tasks for LLMs, the internal thinking processes of RPLAs remain unexplored. Understanding characters' inner thoughts is crucial for developing advanced RPLAs. In this paper, we introduce ROLETHINK, a novel benchmark constructed from literature for evaluating character thought generation. We propose the task of inner thought reasoning, which includes two sets: the gold set that compares generated thoughts with original character monologues, and the silver set that uses expert synthesized character analyses as references. To address this challenge, we propose MIRROR, a chain-of-thought approach that generates character thoughts by retrieving memories, predicting character reactions, and synthesizing motivations. Through extensive experiments, we demonstrate the importance of inner thought reasoning for RPLAs, and MIRROR consistently outperforms existing methods. Resources are available at https://github.com/airaer1998/RPA_Thought.
AURORA:Automated Training Framework of Universal Process Reward Models via Ensemble Prompting and Reverse Verification
Feb 17, 2025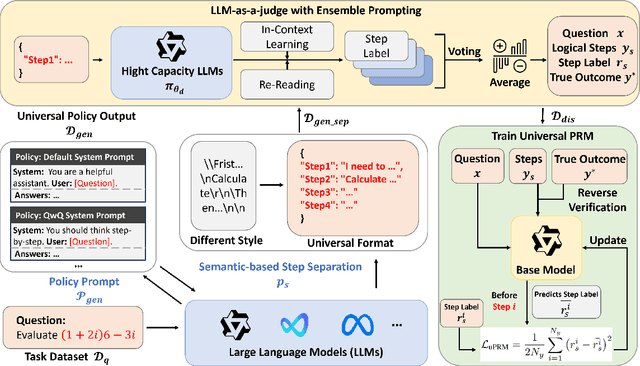
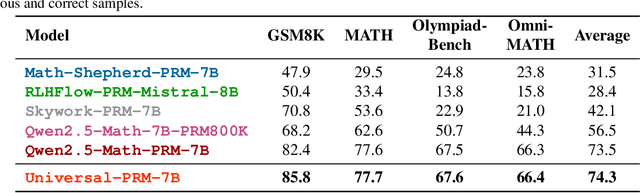
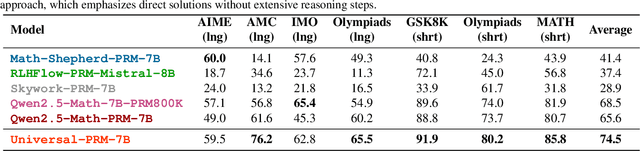
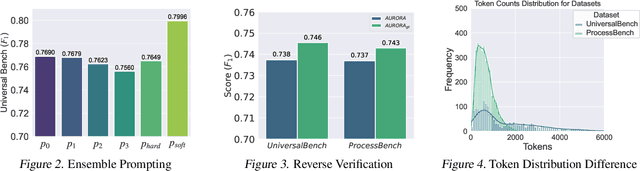
The reasoning capabilities of advanced large language models (LLMs) like o1 have revolutionized artificial intelligence applications. Nevertheless, evaluating and optimizing complex reasoning processes remain significant challenges due to diverse policy distributions and the inherent limitations of human effort and accuracy. In this paper, we present AURORA, a novel automated framework for training universal process reward models (PRMs) using ensemble prompting and reverse verification. The framework employs a two-phase approach: First, it uses diverse prompting strategies and ensemble methods to perform automated annotation and evaluation of processes, ensuring robust assessments for reward learning. Second, it leverages practical reference answers for reverse verification, enhancing the model's ability to validate outputs and improving training accuracy. To assess the framework's performance, we extend beyond the existing ProcessBench benchmark by introducing UniversalBench, which evaluates reward predictions across full trajectories under diverse policy distribtion with long Chain-of-Thought (CoT) outputs. Experimental results demonstrate that AURORA enhances process evaluation accuracy, improves PRMs' accuracy for diverse policy distributions and long-CoT responses. The project will be open-sourced at https://auroraprm.github.io/. The Universal-PRM-7B is available at https://huggingface.co/infly/Universal-PRM-7B.
SCP-116K: A High-Quality Problem-Solution Dataset and a Generalized Pipeline for Automated Extraction in the Higher Education Science Domain
Jan 26, 2025

Recent breakthroughs in large language models (LLMs) exemplified by the impressive mathematical and scientific reasoning capabilities of the o1 model have spotlighted the critical importance of high-quality training data in advancing LLM performance across STEM disciplines. While the mathematics community has benefited from a growing body of curated datasets, the scientific domain at the higher education level has long suffered from a scarcity of comparable resources. To address this gap, we present SCP-116K, a new large-scale dataset of 116,756 high-quality problem-solution pairs, automatically extracted from heterogeneous sources using a streamlined and highly generalizable pipeline. Our approach involves stringent filtering to ensure the scientific rigor and educational level of the extracted materials, while maintaining adaptability for future expansions or domain transfers. By openly releasing both the dataset and the extraction pipeline, we seek to foster research on scientific reasoning, enable comprehensive performance evaluations of new LLMs, and lower the barrier to replicating the successes of advanced models like o1 in the broader science community. We believe SCP-116K will serve as a critical resource, catalyzing progress in high-level scientific reasoning tasks and promoting further innovations in LLM development. The dataset and code are publicly available at https://github.com/AQA6666/SCP-116K-open.
An Attentive Dual-Encoder Framework Leveraging Multimodal Visual and Semantic Information for Automatic OSAHS Diagnosis
Dec 25, 2024



Obstructive sleep apnea-hypopnea syndrome (OSAHS) is a common sleep disorder caused by upper airway blockage, leading to oxygen deprivation and disrupted sleep. Traditional diagnosis using polysomnography (PSG) is expensive, time-consuming, and uncomfortable. Existing deep learning methods using facial image analysis lack accuracy due to poor facial feature capture and limited sample sizes. To address this, we propose a multimodal dual encoder model that integrates visual and language inputs for automated OSAHS diagnosis. The model balances data using randomOverSampler, extracts key facial features with attention grids, and converts physiological data into meaningful text. Cross-attention combines image and text data for better feature extraction, and ordered regression loss ensures stable learning. Our approach improves diagnostic efficiency and accuracy, achieving 91.3% top-1 accuracy in a four-class severity classification task, demonstrating state-of-the-art performance. Code will be released upon acceptance.
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
Nov 07, 2024



Large language models (LLMs) for code have become indispensable in various domains, including code generation, reasoning tasks and agent systems.While open-access code LLMs are increasingly approaching the performance levels of proprietary models, high-quality code LLMs suitable for rigorous scientific investigation, particularly those with reproducible data processing pipelines and transparent training protocols, remain limited. The scarcity is due to various challenges, including resource constraints, ethical considerations, and the competitive advantages of keeping models advanced. To address the gap, we introduce OpenCoder, a top-tier code LLM that not only achieves performance comparable to leading models but also serves as an ``open cookbook'' for the research community. Unlike most prior efforts, we release not only model weights and inference code, but also the reproducible training data, complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols for open scientific research. Through this comprehensive release, we identify the key ingredients for building a top-tier code LLM: (1) code optimized heuristic rules for data cleaning and methods for data deduplication, (2) recall of text corpus related to code and (3) high-quality synthetic data in both annealing and supervised fine-tuning stages. By offering this level of openness, we aim to broaden access to all aspects of a top-tier code LLM, with OpenCoder serving as both a powerful model and an open foundation to accelerate research, and enable reproducible advancements in code AI.
LMGT: Optimizing Exploration-Exploitation Balance in Reinforcement Learning through Language Model Guided Trade-offs
Sep 07, 2024



The uncertainty inherent in the environmental transition model of Reinforcement Learning (RL) necessitates a careful balance between exploration and exploitation to optimize the use of computational resources for accurately estimating an agent's expected reward. Achieving balance in control systems is particularly challenging in scenarios with sparse rewards. However, given the extensive prior knowledge available for many environments, it is redundant to begin learning from scratch in such settings. To address this, we introduce \textbf{L}anguage \textbf{M}odel \textbf{G}uided \textbf{T}rade-offs (i.e., \textbf{LMGT}), a novel, sample-efficient framework that leverages the comprehensive prior knowledge embedded in Large Language Models (LLMs) and their adeptness at processing non-standard data forms, such as wiki tutorials. LMGT proficiently manages the exploration-exploitation trade-off by employing reward shifts guided by LLMs, which direct agents' exploration endeavors, thereby improving sample efficiency. We have thoroughly tested LMGT across various RL tasks and deployed it in industrial-grade RL recommendation systems, where it consistently outperforms baseline methods. The results indicate that our framework can significantly reduce the time cost required during the training phase in RL.