 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI-Eyes: Tool-Augmented Perception for Visual Grounding in GUI Agents
Jan 14, 2026Recent advances in vision-language models (VLMs) and reinforcement learning (RL) have driven progress in GUI automation. However, most existing methods rely on static, one-shot visual inputs and passive perception, lacking the ability to adaptively determine when, whether, and how to observe the interface. We present GUI-Eyes, a reinforcement learning framework for active visual perception in GUI tasks. To acquire more informative observations, the agent learns to make strategic decisions on both whether and how to invoke visual tools, such as cropping or zooming, within a two-stage reasoning process. To support this behavior, we introduce a progressive perception strategy that decomposes decision-making into coarse exploration and fine-grained grounding, coordinated by a two-level policy. In addition, we design a spatially continuous reward function tailored to tool usage, which integrates both location proximity and region overlap to provide dense supervision and alleviate the reward sparsity common in GUI environments. On the ScreenSpot-Pro benchmark, GUI-Eyes-3B achieves 44.8% grounding accuracy using only 3k labeled samples, significantly outperforming both supervised and RL-based baselines. These results highlight that tool-aware active perception, enabled by staged policy reasoning and fine-grained reward feedback, is critical for building robust and data-efficient GUI agents.
The Law of Multi-Model Collaboration: Scaling Limits of Model Ensembling for Large Language Models
Dec 29, 2025Recent advances in large language models (LLMs) have been largely driven by scaling laws for individual models, which predict performance improvements as model parameters and data volume increase. However, the capabilities of any single LLM are inherently bounded. One solution originates from intricate interactions among multiple LLMs, rendering their collective performance surpasses that of any constituent model. Despite the rapid proliferation of multi-model integration techniques such as model routing and post-hoc ensembling, a unifying theoretical framework of performance scaling for multi-model collaboration remains absent. In this work, we propose the Law of Multi-model Collaboration, a scaling law that predicts the performance limits of LLM ensembles based on their aggregated parameter budget. To quantify the intrinsic upper bound of multi-model collaboration, we adopt a method-agnostic formulation and assume an idealized integration oracle where the total cross-entropy loss of each sample is determined by the minimum loss of any model in the model pool. Experimental results reveal that multi-model systems follow a power-law scaling with respect to the total parameter count, exhibiting a more significant improvement trend and a lower theoretical loss floor compared to single model scaling. Moreover, ensembles of heterogeneous model families achieve better performance scaling than those formed within a single model family, indicating that model diversity is a primary driver of collaboration gains. These findings suggest that model collaboration represents a critical axis for extending the intelligence frontier of LLMs.
ScRPO: From Errors to Insights
Nov 11, 2025We propose Self-correction Relative Policy Optimization (ScRPO), a novel reinforcement learning framework designed to enhance large language models on challenging mathematical problems by leveraging self-reflection and error correction. Our approach consists of two stages: (1) Trial-and-error learning stage: training the model with GRPO and collecting incorrect answers along with their corresponding questions in an error pool; (2) Self-correction learning stage: guiding the model to reflect on why its previous answers were wrong. Extensive experiments across multiple math reasoning benchmarks, including AIME, AMC, Olympiad, MATH-500, GSM8k, using Deepseek-Distill-Qwen-1.5B and Deepseek-Distill-Qwen-7B. The experimental results demonstrate that ScRPO consistently outperforms several post-training methods. These findings highlight ScRPO as a promising paradigm for enabling language models to self-improve on difficult tasks with limited external feedback, paving the way toward more reliable and capable AI systems.
Guess What I am Thinking: A Benchmark for Inner Thought Reasoning of Role-Playing Language Agents
Mar 11, 2025

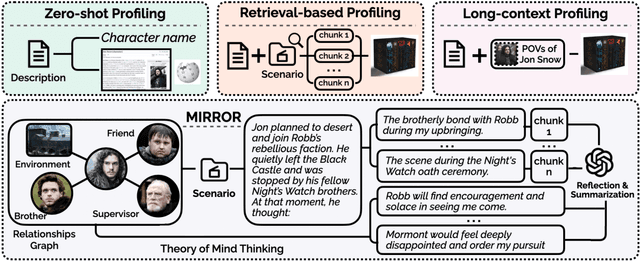
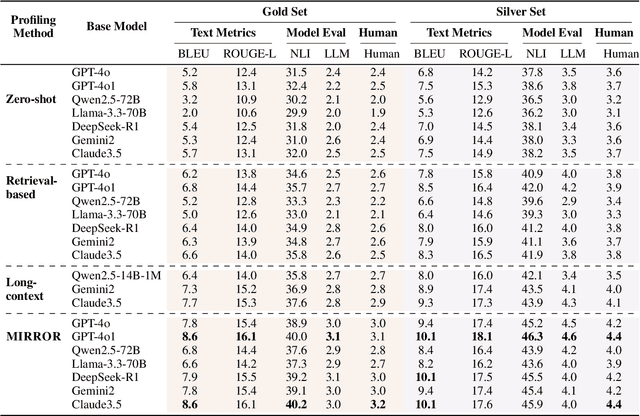
Recent advances in LLM-based role-playing language agents (RPLAs) have attracted broad attention in various applications. While chain-of-thought reasoning has shown importance in many tasks for LLMs, the internal thinking processes of RPLAs remain unexplored. Understanding characters' inner thoughts is crucial for developing advanced RPLAs. In this paper, we introduce ROLETHINK, a novel benchmark constructed from literature for evaluating character thought generation. We propose the task of inner thought reasoning, which includes two sets: the gold set that compares generated thoughts with original character monologues, and the silver set that uses expert synthesized character analyses as references. To address this challenge, we propose MIRROR, a chain-of-thought approach that generates character thoughts by retrieving memories, predicting character reactions, and synthesizing motivations. Through extensive experiments, we demonstrate the importance of inner thought reasoning for RPLAs, and MIRROR consistently outperforms existing methods. Resources are available at https://github.com/airaer1998/RPA_Thought.
AURORA:Automated Training Framework of Universal Process Reward Models via Ensemble Prompting and Reverse Verification
Feb 17, 2025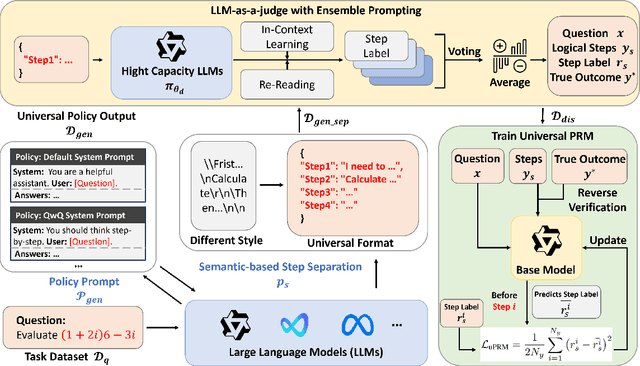
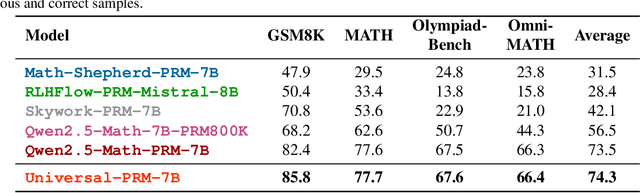
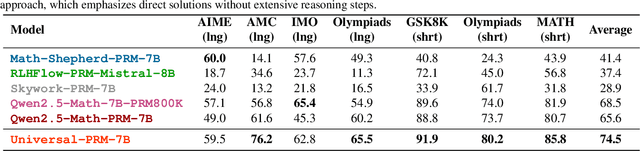
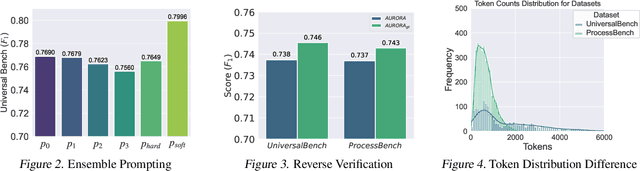
The reasoning capabilities of advanced large language models (LLMs) like o1 have revolutionized artificial intelligence applications. Nevertheless, evaluating and optimizing complex reasoning processes remain significant challenges due to diverse policy distributions and the inherent limitations of human effort and accuracy. In this paper, we present AURORA, a novel automated framework for training universal process reward models (PRMs) using ensemble prompting and reverse verification. The framework employs a two-phase approach: First, it uses diverse prompting strategies and ensemble methods to perform automated annotation and evaluation of processes, ensuring robust assessments for reward learning. Second, it leverages practical reference answers for reverse verification, enhancing the model's ability to validate outputs and improving training accuracy. To assess the framework's performance, we extend beyond the existing ProcessBench benchmark by introducing UniversalBench, which evaluates reward predictions across full trajectories under diverse policy distribtion with long Chain-of-Thought (CoT) outputs. Experimental results demonstrate that AURORA enhances process evaluation accuracy, improves PRMs' accuracy for diverse policy distributions and long-CoT responses. The project will be open-sourced at https://auroraprm.github.io/. The Universal-PRM-7B is available at https://huggingface.co/infly/Universal-PRM-7B.
SCP-116K: A High-Quality Problem-Solution Dataset and a Generalized Pipeline for Automated Extraction in the Higher Education Science Domain
Jan 26, 2025

Recent breakthroughs in large language models (LLMs) exemplified by the impressive mathematical and scientific reasoning capabilities of the o1 model have spotlighted the critical importance of high-quality training data in advancing LLM performance across STEM disciplines. While the mathematics community has benefited from a growing body of curated datasets, the scientific domain at the higher education level has long suffered from a scarcity of comparable resources. To address this gap, we present SCP-116K, a new large-scale dataset of 116,756 high-quality problem-solution pairs, automatically extracted from heterogeneous sources using a streamlined and highly generalizable pipeline. Our approach involves stringent filtering to ensure the scientific rigor and educational level of the extracted materials, while maintaining adaptability for future expansions or domain transfers. By openly releasing both the dataset and the extraction pipeline, we seek to foster research on scientific reasoning, enable comprehensive performance evaluations of new LLMs, and lower the barrier to replicating the successes of advanced models like o1 in the broader science community. We believe SCP-116K will serve as a critical resource, catalyzing progress in high-level scientific reasoning tasks and promoting further innovations in LLM development. The dataset and code are publicly available at https://github.com/AQA6666/SCP-116K-open.
MINDECHO: Role-Playing Language Agents for Key Opinion Leaders
Jul 07, 2024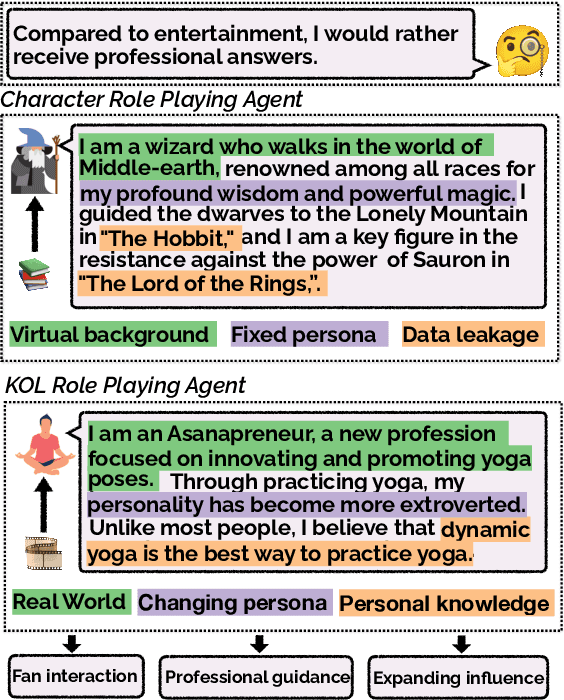

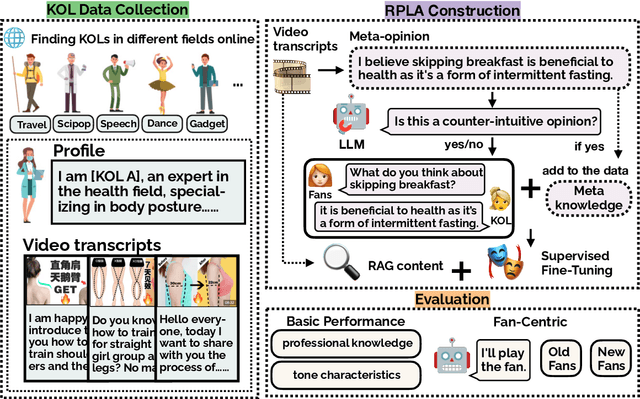
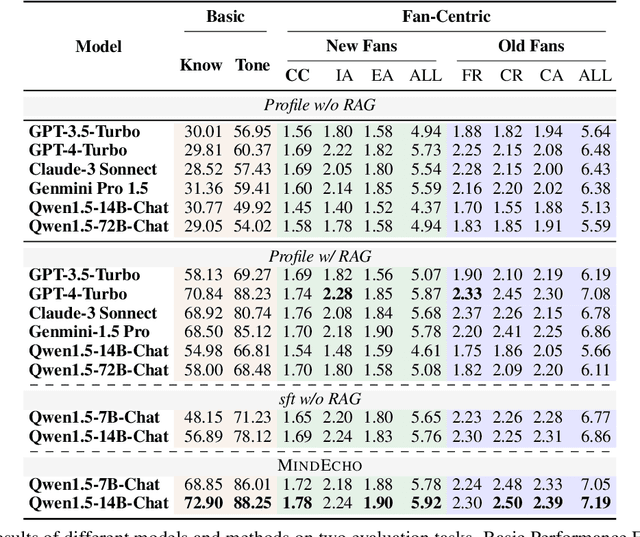
Large language models~(LLMs) have demonstrated impressive performance in various applications, among which role-playing language agents (RPLAs) have engaged a broad user base. Now, there is a growing demand for RPLAs that represent Key Opinion Leaders (KOLs), \ie, Internet celebrities who shape the trends and opinions in their domains. However, research in this line remains underexplored. In this paper, we hence introduce MINDECHO, a comprehensive framework for the development and evaluation of KOL RPLAs. MINDECHO collects KOL data from Internet video transcripts in various professional fields, and synthesizes their conversations leveraging GPT-4. Then, the conversations and the transcripts are used for individualized model training and inference-time retrieval, respectively. Our evaluation covers both general dimensions (\ie, knowledge and tones) and fan-centric dimensions for KOLs. Extensive experiments validate the effectiveness of MINDECHO in developing and evaluating KOL RPLAs.
ConcEPT: Concept-Enhanced Pre-Training for Language Models
Jan 11, 2024Pre-trained language models (PLMs) have been prevailing in state-of-the-art methods for natural language processing, and knowledge-enhanced PLMs are further proposed to promote model performance in knowledge-intensive tasks. However, conceptual knowledge, one essential kind of knowledge for human cognition, still remains understudied in this line of research. This limits PLMs' performance in scenarios requiring human-like cognition, such as understanding long-tail entities with concepts. In this paper, we propose ConcEPT, which stands for Concept-Enhanced Pre-Training for language models, to infuse conceptual knowledge into PLMs. ConcEPT exploits external taxonomies with entity concept prediction, a novel pre-training objective to predict the concepts of entities mentioned in the pre-training contexts. Unlike previous concept-enhanced methods, ConcEPT can be readily adapted to various downstream applications without entity linking or concept mapping. Results of extensive experiments show the effectiveness of ConcEPT in four tasks such as entity typing, which validates that our model gains improved conceptual knowledge with concept-enhanced pre-training.
Source Prompt: Coordinated Pre-training of Language Models on Diverse Corpora from Multiple Sources
Nov 16, 2023
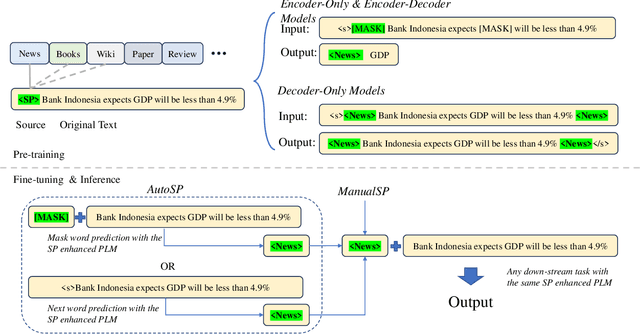

Pre-trained language models (PLMs) have established the new paradigm in the field of NLP. For more powerful PLMs, one of the most popular and successful way is to continuously scale up sizes of the models and the pre-training corpora. These large corpora are generally obtained by converging smaller ones from multiple sources, they are thus growing increasingly diverse. However, the side-effects of these colossal converged corpora remain understudied. In this paper, we identify the disadvantage of heterogeneous corpora from multiple sources for pre-training PLMs. Towards coordinated pre-training on diverse corpora, we further propose source prompts (SP), which explicitly prompt the model of the data source at the pre-training and fine-tuning stages. Results of extensive experiments demonstrate that PLMs pre-trained with SP on diverse corpora gain significant improvement in various downstream tasks.
BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark
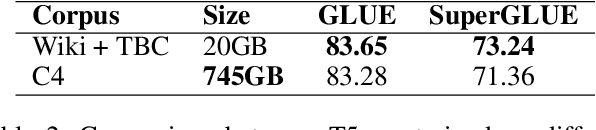
Feb 26, 2023To advance Chinese financial natural language processing (NLP), we introduce BBT-FinT5, a new Chinese financial pre-training language model based on the T5 model. To support this effort, we have built BBT-FinCorpus, a large-scale financial corpus with approximately 300GB of raw text from four different sources. In general domain NLP, comprehensive benchmarks like GLUE and SuperGLUE have driven significant advancements in language model pre-training by enabling head-to-head comparisons among models. Drawing inspiration from these benchmarks, we propose BBT-CFLEB, a Chinese Financial Language understanding and generation Evaluation Benchmark, which includes six datasets covering both understanding and generation tasks. Our aim is to facilitate research in the development of NLP within the Chinese financial domain. Our model, corpus and benchmark are released at https://github.com/ssymmetry/BBT-FinCUGE-Applications. Our work belongs to the Big Bang Transformer (BBT), a large-scale pre-trained language model project.