 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAURORA:Automated Training Framework of Universal Process Reward Models via Ensemble Prompting and Reverse Verification
Feb 17, 2025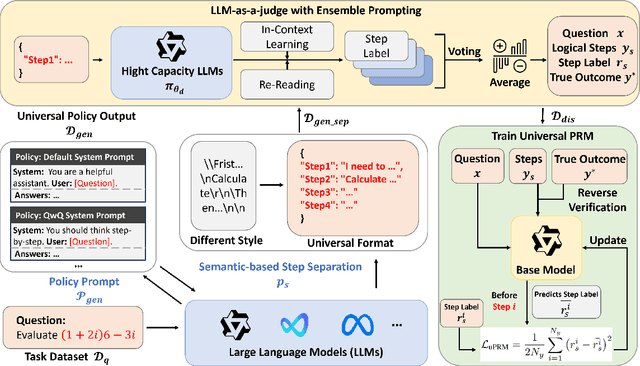
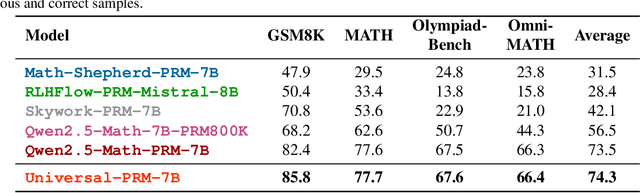
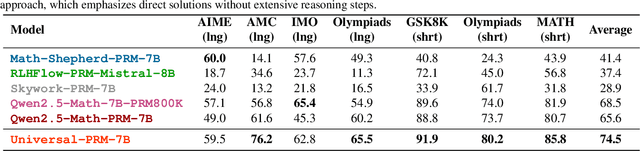
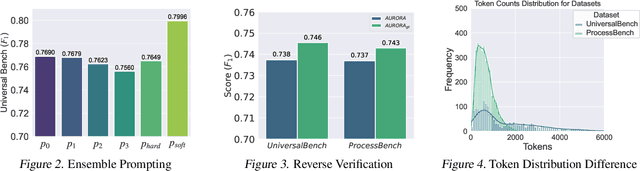
The reasoning capabilities of advanced large language models (LLMs) like o1 have revolutionized artificial intelligence applications. Nevertheless, evaluating and optimizing complex reasoning processes remain significant challenges due to diverse policy distributions and the inherent limitations of human effort and accuracy. In this paper, we present AURORA, a novel automated framework for training universal process reward models (PRMs) using ensemble prompting and reverse verification. The framework employs a two-phase approach: First, it uses diverse prompting strategies and ensemble methods to perform automated annotation and evaluation of processes, ensuring robust assessments for reward learning. Second, it leverages practical reference answers for reverse verification, enhancing the model's ability to validate outputs and improving training accuracy. To assess the framework's performance, we extend beyond the existing ProcessBench benchmark by introducing UniversalBench, which evaluates reward predictions across full trajectories under diverse policy distribtion with long Chain-of-Thought (CoT) outputs. Experimental results demonstrate that AURORA enhances process evaluation accuracy, improves PRMs' accuracy for diverse policy distributions and long-CoT responses. The project will be open-sourced at https://auroraprm.github.io/. The Universal-PRM-7B is available at https://huggingface.co/infly/Universal-PRM-7B.
SCP-116K: A High-Quality Problem-Solution Dataset and a Generalized Pipeline for Automated Extraction in the Higher Education Science Domain
Jan 26, 2025

Recent breakthroughs in large language models (LLMs) exemplified by the impressive mathematical and scientific reasoning capabilities of the o1 model have spotlighted the critical importance of high-quality training data in advancing LLM performance across STEM disciplines. While the mathematics community has benefited from a growing body of curated datasets, the scientific domain at the higher education level has long suffered from a scarcity of comparable resources. To address this gap, we present SCP-116K, a new large-scale dataset of 116,756 high-quality problem-solution pairs, automatically extracted from heterogeneous sources using a streamlined and highly generalizable pipeline. Our approach involves stringent filtering to ensure the scientific rigor and educational level of the extracted materials, while maintaining adaptability for future expansions or domain transfers. By openly releasing both the dataset and the extraction pipeline, we seek to foster research on scientific reasoning, enable comprehensive performance evaluations of new LLMs, and lower the barrier to replicating the successes of advanced models like o1 in the broader science community. We believe SCP-116K will serve as a critical resource, catalyzing progress in high-level scientific reasoning tasks and promoting further innovations in LLM development. The dataset and code are publicly available at https://github.com/AQA6666/SCP-116K-open.