 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience
Jan 23, 2026The development of native computer-use agents (CUA) represents a significant leap in multimodal AI. However, their potential is currently bottlenecked by the constraints of static data scaling. Existing paradigms relying primarily on passive imitation of static datasets struggle to capture the intricate causal dynamics inherent in long-horizon computer tasks. In this work, we introduce EvoCUA, a native computer use agentic model. Unlike static imitation, EvoCUA integrates data generation and policy optimization into a self-sustaining evolutionary cycle. To mitigate data scarcity, we develop a verifiable synthesis engine that autonomously generates diverse tasks coupled with executable validators. To enable large-scale experience acquisition, we design a scalable infrastructure orchestrating tens of thousands of asynchronous sandbox rollouts. Building on these massive trajectories, we propose an iterative evolving learning strategy to efficiently internalize this experience. This mechanism dynamically regulates policy updates by identifying capability boundaries -- reinforcing successful routines while transforming failure trajectories into rich supervision through error analysis and self-correction. Empirical evaluations on the OSWorld benchmark demonstrate that EvoCUA achieves a success rate of 56.7%, establishing a new open-source state-of-the-art. Notably, EvoCUA significantly outperforms the previous best open-source model, OpenCUA-72B (45.0%), and surpasses leading closed-weights models such as UI-TARS-2 (53.1%). Crucially, our results underscore the generalizability of this approach: the evolving paradigm driven by learning from experience yields consistent performance gains across foundation models of varying scales, establishing a robust and scalable path for advancing native agent capabilities.
CogDoc: Towards Unified thinking in Documents
Dec 14, 2025Current document reasoning paradigms are constrained by a fundamental trade-off between scalability (processing long-context documents) and fidelity (capturing fine-grained, multimodal details). To bridge this gap, we propose CogDoc, a unified coarse-to-fine thinking framework that mimics human cognitive processes: a low-resolution "Fast Reading" phase for scalable information localization,followed by a high-resolution "Focused Thinking" phase for deep reasoning. We conduct a rigorous investigation into post-training strategies for the unified thinking framework, demonstrating that a Direct Reinforcement Learning (RL) approach outperforms RL with Supervised Fine-Tuning (SFT) initialization. Specifically, we find that direct RL avoids the "policy conflict" observed in SFT. Empirically, our 7B model achieves state-of-the-art performance within its parameter class, notably surpassing significantly larger proprietary models (e.g., GPT-4o) on challenging, visually rich document benchmarks.
A Rigorous Benchmark with Multidimensional Evaluation for Deep Research Agents: From Answers to Reports
Oct 02, 2025Artificial intelligence is undergoing the paradigm shift from closed language models to interconnected agent systems capable of external perception and information integration. As a representative embodiment, Deep Research Agents (DRAs) systematically exhibit the capabilities for task decomposition, cross-source retrieval, multi-stage reasoning, and structured output, which markedly enhance performance on complex and open-ended tasks. However, existing benchmarks remain deficient in evaluation dimensions, response formatting, and scoring mechanisms, limiting their capacity to assess such systems effectively. This paper introduces a rigorous benchmark and a multidimensional evaluation framework tailored to DRAs and report-style responses. The benchmark comprises 214 expert-curated challenging queries distributed across 10 broad thematic domains, each accompanied by manually constructed reference bundles to support composite evaluation. The framework enables comprehensive evaluation of long-form reports generated by DRAs, incorporating integrated scoring metrics for semantic quality, topical focus, and retrieval trustworthiness. Extensive experimentation confirms the superior performance of mainstream DRAs over web-search-tool-augmented reasoning models, yet reveals considerable scope for further improvement. This study provides a robust foundation for capability assessment, architectural refinement, and paradigm advancement in DRA systems.
Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning
Sep 03, 2025



Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaque. Our analysis reveals that puzzling phenomena like ``aha moments", ``length-scaling'' and entropy dynamics are not disparate occurrences but hallmarks of an emergent reasoning hierarchy, akin to the separation of high-level strategic planning from low-level procedural execution in human cognition. We uncover a compelling two-phase dynamic: initially, a model is constrained by procedural correctness and must improve its low-level skills. The learning bottleneck then decisively shifts, with performance gains being driven by the exploration and mastery of high-level strategic planning. This insight exposes a core inefficiency in prevailing RL algorithms like GRPO, which apply optimization pressure agnostically and dilute the learning signal across all tokens. To address this, we propose HIerarchy-Aware Credit Assignment (HICRA), an algorithm that concentrates optimization efforts on high-impact planning tokens. HICRA significantly outperforms strong baselines, demonstrating that focusing on this strategic bottleneck is key to unlocking advanced reasoning. Furthermore, we validate semantic entropy as a superior compass for measuring strategic exploration over misleading metrics such as token-level entropy.
URPlanner: A Universal Paradigm For Collision-Free Robotic Motion Planning Based on Deep Reinforcement Learning
May 26, 2025



Collision-free motion planning for redundant robot manipulators in complex environments is yet to be explored. Although recent advancements at the intersection of deep reinforcement learning (DRL) and robotics have highlighted its potential to handle versatile robotic tasks, current DRL-based collision-free motion planners for manipulators are highly costly, hindering their deployment and application. This is due to an overreliance on the minimum distance between the manipulator and obstacles, inadequate exploration and decision-making by DRL, and inefficient data acquisition and utilization. In this article, we propose URPlanner, a universal paradigm for collision-free robotic motion planning based on DRL. URPlanner offers several advantages over existing approaches: it is platform-agnostic, cost-effective in both training and deployment, and applicable to arbitrary manipulators without solving inverse kinematics. To achieve this, we first develop a parameterized task space and a universal obstacle avoidance reward that is independent of minimum distance. Second, we introduce an augmented policy exploration and evaluation algorithm that can be applied to various DRL algorithms to enhance their performance. Third, we propose an expert data diffusion strategy for efficient policy learning, which can produce a large-scale trajectory dataset from only a few expert demonstrations. Finally, the superiority of the proposed methods is comprehensively verified through experiments.
Benchmarking Multimodal Knowledge Conflict for Large Multimodal Models
May 26, 2025Large Multimodal Models(LMMs) face notable challenges when encountering multimodal knowledge conflicts, particularly under retrieval-augmented generation(RAG) frameworks where the contextual information from external sources may contradict the model's internal parametric knowledge, leading to unreliable outputs. However, existing benchmarks fail to reflect such realistic conflict scenarios. Most focus solely on intra-memory conflicts, while context-memory and inter-context conflicts remain largely investigated. Furthermore, commonly used factual knowledge-based evaluations are often overlooked, and existing datasets lack a thorough investigation into conflict detection capabilities. To bridge this gap, we propose MMKC-Bench, a benchmark designed to evaluate factual knowledge conflicts in both context-memory and inter-context scenarios. MMKC-Bench encompasses three types of multimodal knowledge conflicts and includes 1,573 knowledge instances and 3,381 images across 23 broad types, collected through automated pipelines with human verification. We evaluate three representative series of LMMs on both model behavior analysis and conflict detection tasks. Our findings show that while current LMMs are capable of recognizing knowledge conflicts, they tend to favor internal parametric knowledge over external evidence. We hope MMKC-Bench will foster further research in multimodal knowledge conflict and enhance the development of multimodal RAG systems. The source code is available at https://github.com/MLLMKCBENCH/MLLMKC.
StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs
May 26, 2025
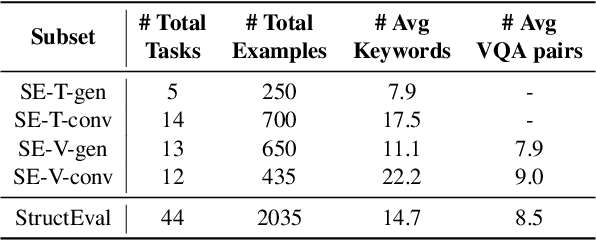

As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs' capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: 1) generation tasks, producing structured output from natural language prompts, and 2) conversion tasks, translating between structured formats. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps, even state-of-the-art models like o1-mini achieve only 75.58 average score, with open-source alternatives lagging approximately 10 points behind. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.
Beyond Distillation: Pushing the Limits of Medical LLM Reasoning with Minimalist Rule-Based RL
May 23, 2025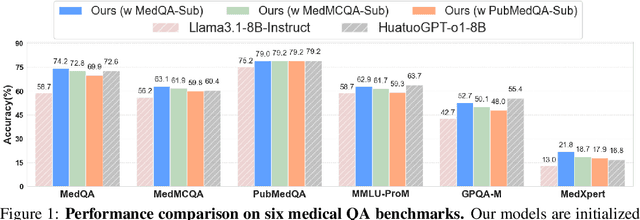
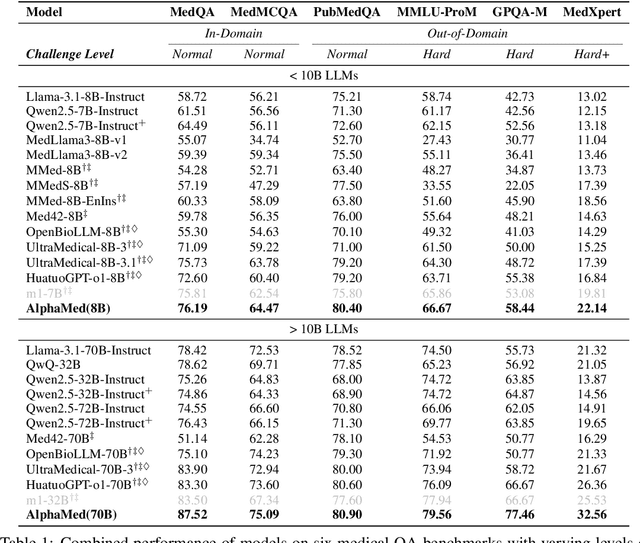
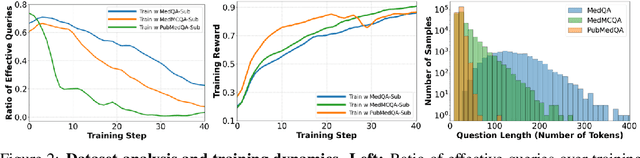

Improving performance on complex tasks and enabling interpretable decision making in large language models (LLMs), especially for clinical applications, requires effective reasoning. Yet this remains challenging without supervised fine-tuning (SFT) on costly chain-of-thought (CoT) data distilled from closed-source models (e.g., GPT-4o). In this work, we present AlphaMed, the first medical LLM to show that reasoning capability can emerge purely through reinforcement learning (RL), using minimalist rule-based rewards on public multiple-choice QA datasets, without relying on SFT or distilled CoT data. AlphaMed achieves state-of-the-art results on six medical QA benchmarks, outperforming models trained with conventional SFT+RL pipelines. On challenging benchmarks (e.g., MedXpert), AlphaMed even surpasses larger or closed-source models such as DeepSeek-V3-671B and Claude-3.5-Sonnet. To understand the factors behind this success, we conduct a comprehensive data-centric analysis guided by three questions: (i) Can minimalist rule-based RL incentivize reasoning without distilled CoT supervision? (ii) How do dataset quantity and diversity impact reasoning? (iii) How does question difficulty shape the emergence and generalization of reasoning? Our findings show that dataset informativeness is a key driver of reasoning performance, and that minimalist RL on informative, multiple-choice QA data is effective at inducing reasoning without CoT supervision. We also observe divergent trends across benchmarks, underscoring limitations in current evaluation and the need for more challenging, reasoning-oriented medical QA benchmarks.
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
May 21, 2025



Chain-of-thought reasoning has significantly improved the performance of Large Language Models (LLMs) across various domains. However, this reasoning process has been confined exclusively to textual space, limiting its effectiveness in visually intensive tasks. To address this limitation, we introduce the concept of reasoning in the pixel-space. Within this novel framework, Vision-Language Models (VLMs) are equipped with a suite of visual reasoning operations, such as zoom-in and select-frame. These operations enable VLMs to directly inspect, interrogate, and infer from visual evidences, thereby enhancing reasoning fidelity for visual tasks. Cultivating such pixel-space reasoning capabilities in VLMs presents notable challenges, including the model's initially imbalanced competence and its reluctance to adopt the newly introduced pixel-space operations. We address these challenges through a two-phase training approach. The first phase employs instruction tuning on synthesized reasoning traces to familiarize the model with the novel visual operations. Following this, a reinforcement learning (RL) phase leverages a curiosity-driven reward scheme to balance exploration between pixel-space reasoning and textual reasoning. With these visual operations, VLMs can interact with complex visual inputs, such as information-rich images or videos to proactively gather necessary information. We demonstrate that this approach significantly improves VLM performance across diverse visual reasoning benchmarks. Our 7B model, \model, achieves 84\% on V* bench, 74\% on TallyQA-Complex, and 84\% on InfographicsVQA, marking the highest accuracy achieved by any open-source model to date. These results highlight the importance of pixel-space reasoning and the effectiveness of our framework.
Zero-shot Autonomous Microscopy for Scalable and Intelligent Characterization of 2D Materials
Apr 14, 2025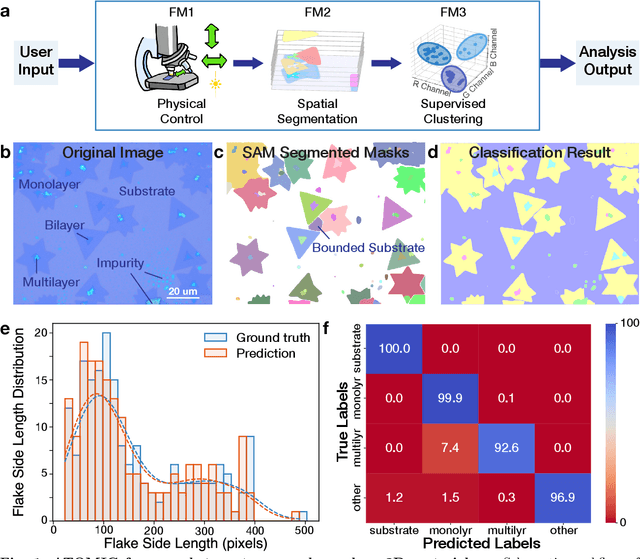
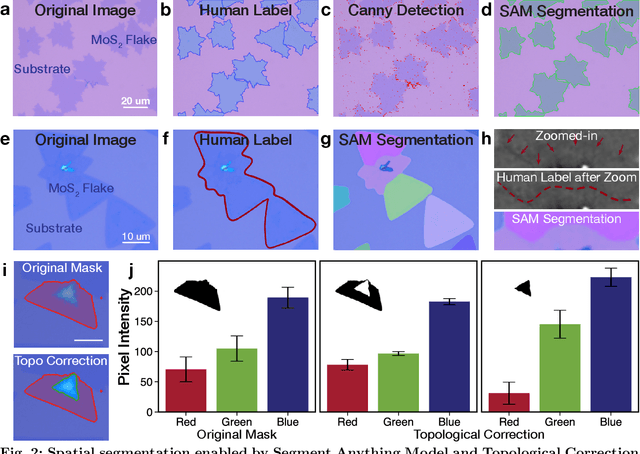
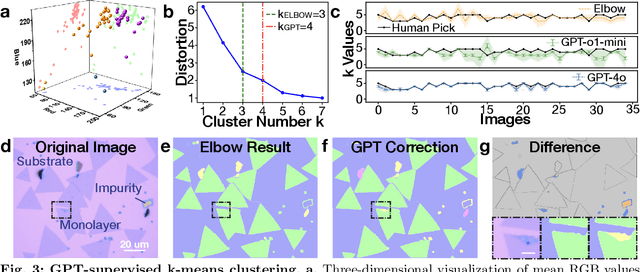
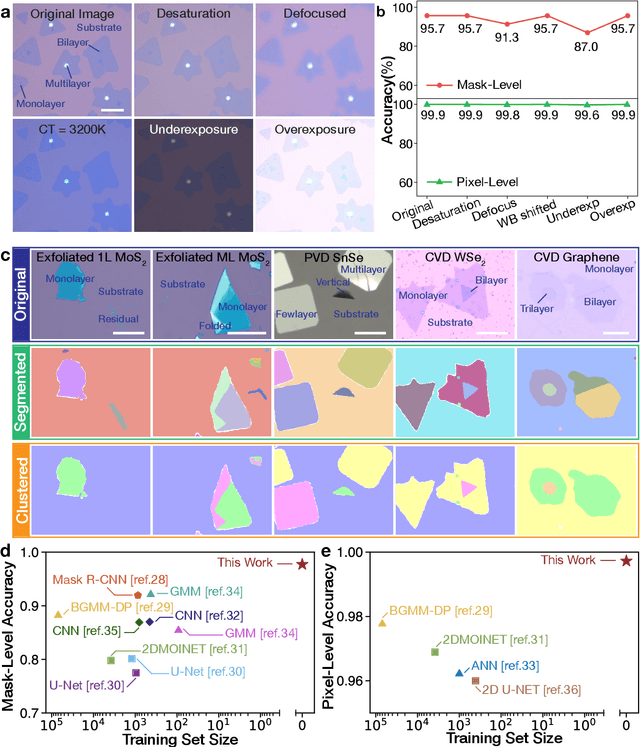
Characterization of atomic-scale materials traditionally requires human experts with months to years of specialized training. Even for trained human operators, accurate and reliable characterization remains challenging when examining newly discovered materials such as two-dimensional (2D) structures. This bottleneck drives demand for fully autonomous experimentation systems capable of comprehending research objectives without requiring large training datasets. In this work, we present ATOMIC (Autonomous Technology for Optical Microscopy & Intelligent Characterization), an end-to-end framework that integrates foundation models to enable fully autonomous, zero-shot characterization of 2D materials. Our system integrates the vision foundation model (i.e., Segment Anything Model), large language models (i.e., ChatGPT), unsupervised clustering, and topological analysis to automate microscope control, sample scanning, image segmentation, and intelligent analysis through prompt engineering, eliminating the need for additional training. When analyzing typical MoS2 samples, our approach achieves 99.7% segmentation accuracy for single layer identification, which is equivalent to that of human experts. In addition, the integrated model is able to detect grain boundary slits that are challenging to identify with human eyes. Furthermore, the system retains robust accuracy despite variable conditions including defocus, color temperature fluctuations, and exposure variations. It is applicable to a broad spectrum of common 2D materials-including graphene, MoS2, WSe2, SnSe-regardless of whether they were fabricated via chemical vapor deposition or mechanical exfoliation. This work represents the implementation of foundation models to achieve autonomous analysis, establishing a scalable and data-efficient characterization paradigm that fundamentally transforms the approach to nanoscale materials research.