 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein generation with embedding learning for motif diversification
Oct 21, 2025A fundamental challenge in protein design is the trade-off between generating structural diversity while preserving motif biological function. Current state-of-the-art methods, such as partial diffusion in RFdiffusion, often fail to resolve this trade-off: small perturbations yield motifs nearly identical to the native structure, whereas larger perturbations violate the geometric constraints necessary for biological function. We introduce Protein Generation with Embedding Learning (PGEL), a general framework that learns high-dimensional embeddings encoding sequence and structural features of a target motif in the representation space of a diffusion model's frozen denoiser, and then enhances motif diversity by introducing controlled perturbations in the embedding space. PGEL is thus able to loosen geometric constraints while satisfying typical design metrics, leading to more diverse yet viable structures. We demonstrate PGEL on three representative cases: a monomer, a protein-protein interface, and a cancer-related transcription factor complex. In all cases, PGEL achieves greater structural diversity, better designability, and improved self-consistency, as compared to partial diffusion. Our results establish PGEL as a general strategy for embedding-driven protein generation allowing for systematic, viable diversification of functional motifs.
Segment Anyword: Mask Prompt Inversion for Open-Set Grounded Segmentation
May 23, 2025Open-set image segmentation poses a significant challenge because existing methods often demand extensive training or fine-tuning and generally struggle to segment unified objects consistently across diverse text reference expressions. Motivated by this, we propose Segment Anyword, a novel training-free visual concept prompt learning approach for open-set language grounded segmentation that relies on token-level cross-attention maps from a frozen diffusion model to produce segmentation surrogates or mask prompts, which are then refined into targeted object masks. Initial prompts typically lack coherence and consistency as the complexity of the image-text increases, resulting in suboptimal mask fragments. To tackle this issue, we further introduce a novel linguistic-guided visual prompt regularization that binds and clusters visual prompts based on sentence dependency and syntactic structural information, enabling the extraction of robust, noise-tolerant mask prompts, and significant improvements in segmentation accuracy. The proposed approach is effective, generalizes across different open-set segmentation tasks, and achieves state-of-the-art results of 52.5 (+6.8 relative) mIoU on Pascal Context 59, 67.73 (+25.73 relative) cIoU on gRefCOCO, and 67.4 (+1.1 relative to fine-tuned methods) mIoU on GranDf, which is the most complex open-set grounded segmentation task in the field.
BOTM: Echocardiography Segmentation via Bi-directional Optimal Token Matching
May 23, 2025Existed echocardiography segmentation methods often suffer from anatomical inconsistency challenge caused by shape variation, partial observation and region ambiguity with similar intensity across 2D echocardiographic sequences, resulting in false positive segmentation with anatomical defeated structures in challenging low signal-to-noise ratio conditions. To provide a strong anatomical guarantee across different echocardiographic frames, we propose a novel segmentation framework named BOTM (Bi-directional Optimal Token Matching) that performs echocardiography segmentation and optimal anatomy transportation simultaneously. Given paired echocardiographic images, BOTM learns to match two sets of discrete image tokens by finding optimal correspondences from a novel anatomical transportation perspective. We further extend the token matching into a bi-directional cross-transport attention proxy to regulate the preserved anatomical consistency within the cardiac cyclic deformation in temporal domain. Extensive experimental results show that BOTM can generate stable and accurate segmentation outcomes (e.g. -1.917 HD on CAMUS2H LV, +1.9% Dice on TED), and provide a better matching interpretation with anatomical consistency guarantee.
Tackling Hallucination from Conditional Models for Medical Image Reconstruction with DynamicDPS
Mar 03, 2025Hallucinations are spurious structures not present in the ground truth, posing a critical challenge in medical image reconstruction, especially for data-driven conditional models. We hypothesize that combining an unconditional diffusion model with data consistency, trained on a diverse dataset, can reduce these hallucinations. Based on this, we propose DynamicDPS, a diffusion-based framework that integrates conditional and unconditional diffusion models to enhance low-quality medical images while systematically reducing hallucinations. Our approach first generates an initial reconstruction using a conditional model, then refines it with an adaptive diffusion-based inverse problem solver. DynamicDPS skips early stage in the reverse process by selecting an optimal starting time point per sample and applies Wolfe's line search for adaptive step sizes, improving both efficiency and image fidelity. Using diffusion priors and data consistency, our method effectively reduces hallucinations from any conditional model output. We validate its effectiveness in Image Quality Transfer for low-field MRI enhancement. Extensive evaluations on synthetic and real MR scans, including a downstream task for tissue volume estimation, show that DynamicDPS reduces hallucinations, improving relative volume estimation by over 15% for critical tissues while using only 5% of the sampling steps required by baseline diffusion models. As a model-agnostic and fine-tuning-free approach, DynamicDPS offers a robust solution for hallucination reduction in medical imaging. The code will be made publicly available upon publication.
DeCoRe: Decoding by Contrasting Retrieval Heads to Mitigate Hallucinations
Oct 24, 2024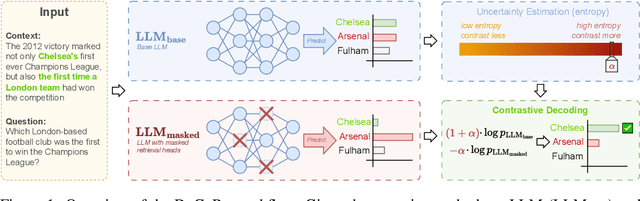
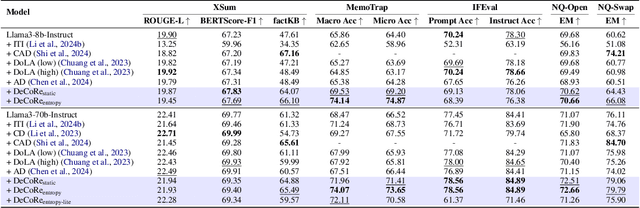
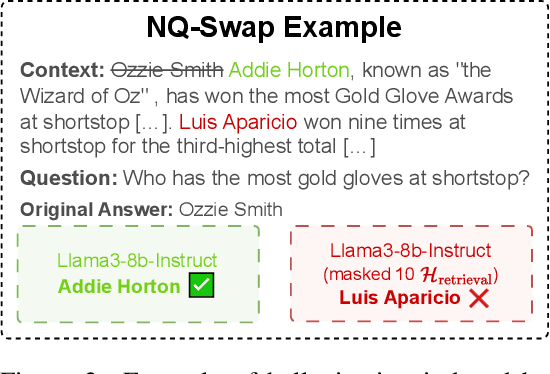

Large Language Models (LLMs) often hallucinate, producing unfaithful or factually incorrect outputs by misrepresenting the provided context or incorrectly recalling internal knowledge. Recent studies have identified specific attention heads within the Transformer architecture, known as retrieval heads, responsible for extracting relevant contextual information. We hypothesise that masking these retrieval heads can induce hallucinations and that contrasting the outputs of the base LLM and the masked LLM can reduce hallucinations. To this end, we propose Decoding by Contrasting Retrieval Heads (DeCoRe), a novel training-free decoding strategy that amplifies information found in the context and model parameters. DeCoRe mitigates potentially hallucinated responses by dynamically contrasting the outputs of the base LLM and the masked LLM, using conditional entropy as a guide. Our extensive experiments confirm that DeCoRe significantly improves performance on tasks requiring high contextual faithfulness, such as summarisation (XSum by 18.6%), instruction following (MemoTrap by 10.9%), and open-book question answering (NQ-Open by 2.4% and NQ-Swap by 5.5%).
Can Medical Vision-Language Pre-training Succeed with Purely Synthetic Data?
Oct 17, 2024



Medical Vision-Language Pre-training (MedVLP) has made significant progress in enabling zero-shot tasks for medical image understanding. However, training MedVLP models typically requires large-scale datasets with paired, high-quality image-text data, which are scarce in the medical domain. Recent advancements in Large Language Models (LLMs) and diffusion models have made it possible to generate large-scale synthetic image-text pairs. This raises the question: *Can MedVLP succeed using purely synthetic data?* To address this, we use off-the-shelf generative models to create synthetic radiology reports and paired Chest X-ray (CXR) images, and propose an automated pipeline to build a diverse, high-quality synthetic dataset, enabling a rigorous study that isolates model and training settings, focusing entirely from the data perspective. Our results show that MedVLP models trained *exclusively on synthetic data* outperform those trained on real data by **3.8%** in averaged AUC on zero-shot classification. Moreover, using a combination of synthetic and real data leads to a further improvement of **9.07%**. Additionally, MedVLP models trained on synthetic or mixed data consistently outperform those trained on real data in zero-shot grounding, as well as in fine-tuned classification and segmentation tasks. Our analysis suggests MedVLP trained on well-designed synthetic data can outperform models trained on real datasets, which may be limited by low-quality samples and long-tailed distributions.
Tackling Structural Hallucination in Image Translation with Local Diffusion
Apr 13, 2024



Recent developments in diffusion models have advanced conditioned image generation, yet they struggle with reconstructing out-of-distribution (OOD) images, such as unseen tumors in medical images, causing ``image hallucination'' and risking misdiagnosis. We hypothesize such hallucinations result from local OOD regions in the conditional images. We verify that partitioning the OOD region and conducting separate image generations alleviates hallucinations in several applications. From this, we propose a training-free diffusion framework that reduces hallucination with multiple Local Diffusion processes. Our approach involves OOD estimation followed by two modules: a ``branching'' module generates locally both within and outside OOD regions, and a ``fusion'' module integrates these predictions into one. Our evaluation shows our method mitigates hallucination over baseline models quantitatively and qualitatively, reducing misdiagnosis by 40% and 25% in the real-world medical and natural image datasets, respectively. It also demonstrates compatibility with various pre-trained diffusion models.
An Image is Worth Multiple Words: Learning Object Level Concepts using Multi-Concept Prompt Learning
Oct 18, 2023Textural Inversion, a prompt learning method, learns a singular embedding for a new "word" to represent image style and appearance, allowing it to be integrated into natural language sentences to generate novel synthesised images. However, identifying and integrating multiple object-level concepts within one scene poses significant challenges even when embeddings for individual concepts are attainable. This is further confirmed by our empirical tests. To address this challenge, we introduce a framework for Multi-Concept Prompt Learning (MCPL), where multiple new "words" are simultaneously learned from a single sentence-image pair. To enhance the accuracy of word-concept correlation, we propose three regularisation techniques: Attention Masking (AttnMask) to concentrate learning on relevant areas; Prompts Contrastive Loss (PromptCL) to separate the embeddings of different concepts; and Bind adjective (Bind adj.) to associate new "words" with known words. We evaluate via image generation, editing, and attention visualisation with diverse images. Extensive quantitative comparisons demonstrate that our method can learn more semantically disentangled concepts with enhanced word-concept correlation. Additionally, we introduce a novel dataset and evaluation protocol tailored for this new task of learning object-level concepts.
CAMIL: Context-Aware Multiple Instance Learning for Whole Slide Image Classification
May 09, 2023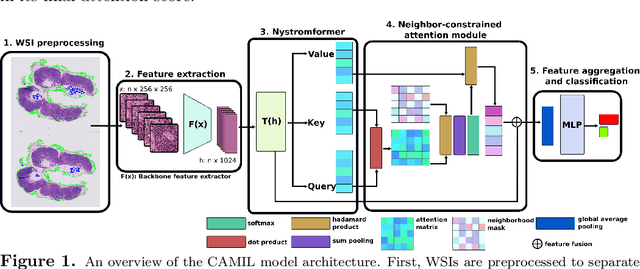
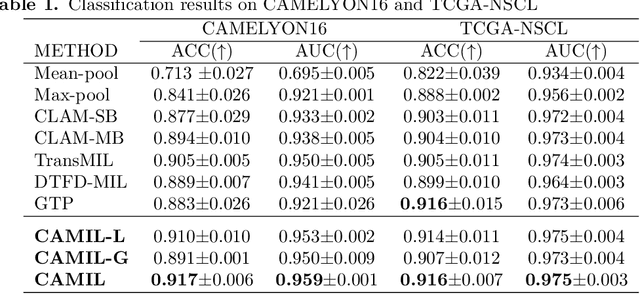
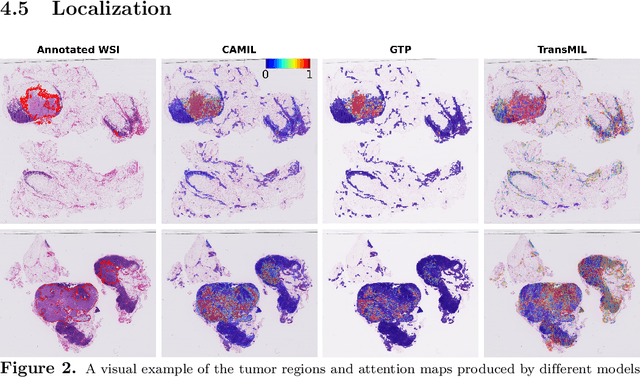
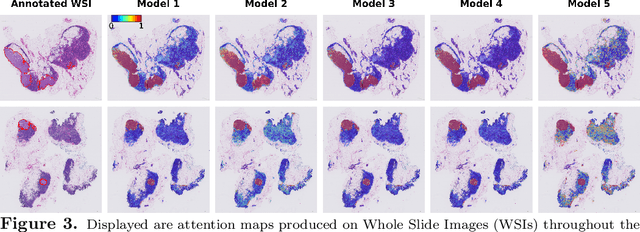
Cancer diagnoses typically involve human pathologists examining whole slide images (WSIs) of tissue section biopsies to identify tumor cells and their subtypes. However, artificial intelligence (AI)-based models, particularly weakly supervised approaches, have recently emerged as viable alternatives. Weakly supervised approaches often use image subsections or tiles as input, with the overall classification of the WSI based on attention scores assigned to each tile. However, this method overlooks the potential for false positives/negatives because tumors can be heterogeneous, with cancer and normal cells growing in patterns larger than a single tile. Such errors at the tile level could lead to misclassification at the tumor level. To address this limitation, we developed a novel deep learning pooling operator called CHARM (Contrastive Histopathology Attention Resolved Models). CHARM leverages the dependencies among single tiles within a WSI and imposes contextual constraints as prior knowledge to multiple instance learning models. We tested CHARM on the subtyping of non-small cell lung cancer (NSLC) and lymph node (LN) metastasis, and the results demonstrated its superiority over other state-of-the-art weakly supervised classification algorithms. Furthermore, CHARM facilitates interpretability by visualizing regions of attention.
Expectation Maximization Pseudo Labelling for Segmentation with Limited Annotations
May 02, 2023We study pseudo labelling and its generalisation for semi-supervised segmentation of medical images. Pseudo labelling has achieved great empirical successes in semi-supervised learning, by utilising raw inferences on unlabelled data as pseudo labels for self-training. In our paper, we build a connection between pseudo labelling and the Expectation Maximization algorithm which partially explains its empirical successes. We thereby realise that the original pseudo labelling is an empirical estimation of its underlying full formulation. Following this insight, we demonstrate the full generalisation of pseudo labels under Bayes' principle, called Bayesian Pseudo Labels. We then provide a variational approach to learn to approximate Bayesian Pseudo Labels, by learning a threshold to select good quality pseudo labels. In the rest of the paper, we demonstrate the applications of Pseudo Labelling and its generalisation Bayesian Psuedo Labelling in semi-supervised segmentation of medical images on: 1) 3D binary segmentation of lung vessels from CT volumes; 2) 2D multi class segmentation of brain tumours from MRI volumes; 3) 3D binary segmentation of brain tumours from MRI volumes. We also show that pseudo labels can enhance the robustness of the learnt representations.