 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM enhanced graph inference for long-term disease progression modelling
Nov 14, 2025Understanding the interactions between biomarkers among brain regions during neurodegenerative disease is essential for unravelling the mechanisms underlying disease progression. For example, pathophysiological models of Alzheimer's Disease (AD) typically describe how variables, such as regional levels of toxic proteins, interact spatiotemporally within a dynamical system driven by an underlying biological substrate, often based on brain connectivity. However, current methods grossly oversimplify the complex relationship between brain connectivity by assuming a single-modality brain connectome as the disease-spreading substrate. This leads to inaccurate predictions of pathology spread, especially during the long-term progression period. Meanhwile, other methods of learning such a graph in a purely data-driven way face the identifiability issue due to lack of proper constraint. We thus present a novel framework that uses Large Language Models (LLMs) as expert guides on the interaction of regional variables to enhance learning of disease progression from irregularly sampled longitudinal patient data. By leveraging LLMs' ability to synthesize multi-modal relationships and incorporate diverse disease-driving mechanisms, our method simultaneously optimizes 1) the construction of long-term disease trajectories from individual-level observations and 2) the biologically-constrained graph structure that captures interactions among brain regions with better identifiability. We demonstrate the new approach by estimating the pathology propagation using tau-PET imaging data from an Alzheimer's disease cohort. The new framework demonstrates superior prediction accuracy and interpretability compared to traditional approaches while revealing additional disease-driving factors beyond conventional connectivity measures.
DeCoRe: Decoding by Contrasting Retrieval Heads to Mitigate Hallucinations
Oct 24, 2024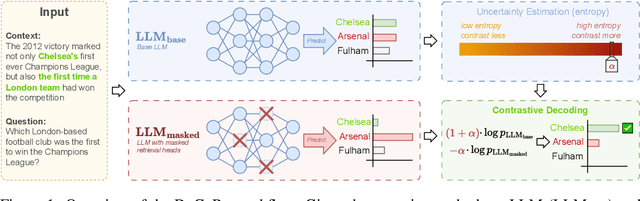
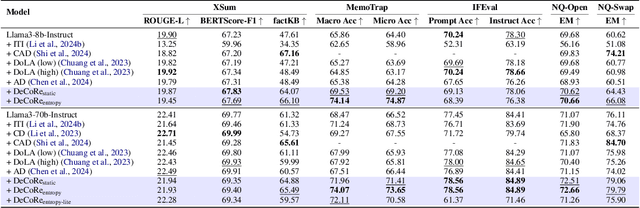
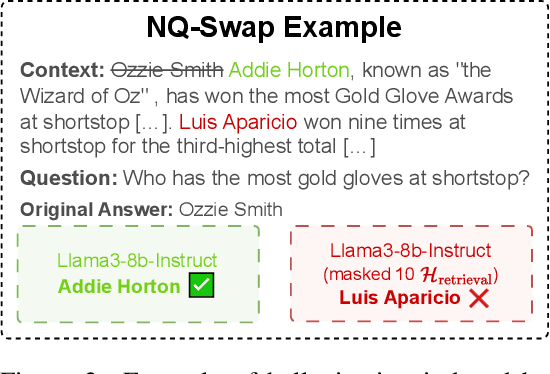

Large Language Models (LLMs) often hallucinate, producing unfaithful or factually incorrect outputs by misrepresenting the provided context or incorrectly recalling internal knowledge. Recent studies have identified specific attention heads within the Transformer architecture, known as retrieval heads, responsible for extracting relevant contextual information. We hypothesise that masking these retrieval heads can induce hallucinations and that contrasting the outputs of the base LLM and the masked LLM can reduce hallucinations. To this end, we propose Decoding by Contrasting Retrieval Heads (DeCoRe), a novel training-free decoding strategy that amplifies information found in the context and model parameters. DeCoRe mitigates potentially hallucinated responses by dynamically contrasting the outputs of the base LLM and the masked LLM, using conditional entropy as a guide. Our extensive experiments confirm that DeCoRe significantly improves performance on tasks requiring high contextual faithfulness, such as summarisation (XSum by 18.6%), instruction following (MemoTrap by 10.9%), and open-book question answering (NQ-Open by 2.4% and NQ-Swap by 5.5%).
An X-Ray Is Worth 15 Features: Sparse Autoencoders for Interpretable Radiology Report Generation
Oct 04, 2024Radiological services are experiencing unprecedented demand, leading to increased interest in automating radiology report generation. Existing Vision-Language Models (VLMs) suffer from hallucinations, lack interpretability, and require expensive fine-tuning. We introduce SAE-Rad, which uses sparse autoencoders (SAEs) to decompose latent representations from a pre-trained vision transformer into human-interpretable features. Our hybrid architecture combines state-of-the-art SAE advancements, achieving accurate latent reconstructions while maintaining sparsity. Using an off-the-shelf language model, we distil ground-truth reports into radiological descriptions for each SAE feature, which we then compile into a full report for each image, eliminating the need for fine-tuning large models for this task. To the best of our knowledge, SAE-Rad represents the first instance of using mechanistic interpretability techniques explicitly for a downstream multi-modal reasoning task. On the MIMIC-CXR dataset, SAE-Rad achieves competitive radiology-specific metrics compared to state-of-the-art models while using significantly fewer computational resources for training. Qualitative analysis reveals that SAE-Rad learns meaningful visual concepts and generates reports aligning closely with expert interpretations. Our results suggest that SAEs can enhance multimodal reasoning in healthcare, providing a more interpretable alternative to existing VLMs.
Disentangled Diffusion Autoencoder for Harmonization of Multi-site Neuroimaging Data
Aug 28, 2024



Combining neuroimaging datasets from multiple sites and scanners can help increase statistical power and thus provide greater insight into subtle neuroanatomical effects. However, site-specific effects pose a challenge by potentially obscuring the biological signal and introducing unwanted variance. Existing harmonization techniques, which use statistical models to remove such effects, have been shown to incompletely remove site effects while also failing to preserve biological variability. More recently, generative models using GANs or autoencoder-based approaches, have been proposed for site adjustment. However, such methods are known for instability during training or blurry image generation. In recent years, diffusion models have become increasingly popular for their ability to generate high-quality synthetic images. In this work, we introduce the disentangled diffusion autoencoder (DDAE), a novel diffusion model designed for controlling specific aspects of an image. We apply the DDAE to the task of harmonizing MR images by generating high-quality site-adjusted images that preserve biological variability. We use data from 7 different sites and demonstrate the DDAE's superiority in generating high-resolution, harmonized 2D MR images over previous approaches. As far as we are aware, this work marks the first diffusion-based model for site adjustment of neuroimaging data.
Normative Diffusion Autoencoders: Application to Amyotrophic Lateral Sclerosis
Jul 19, 2024Predicting survival in Amyotrophic Lateral Sclerosis (ALS) is a challenging task. Magnetic resonance imaging (MRI) data provide in vivo insight into brain health, but the low prevalence of the condition and resultant data scarcity limit training set sizes for prediction models. Survival models are further hindered by the subtle and often highly localised profile of ALS-related neurodegeneration. Normative models present a solution as they increase statistical power by leveraging large healthy cohorts. Separately, diffusion models excel in capturing the semantics embedded within images including subtle signs of accelerated brain ageing, which may help predict survival in ALS. Here, we combine the benefits of generative and normative modelling by introducing the normative diffusion autoencoder framework. To our knowledge, this is the first use of normative modelling within a diffusion autoencoder, as well as the first application of normative modelling to ALS. Our approach outperforms generative and non-generative normative modelling benchmarks in ALS prognostication, demonstrating enhanced predictive accuracy in the context of ALS survival prediction and normative modelling in general.
Interpretable Alzheimer's Disease Classification Via a Contrastive Diffusion Autoencoder
Jun 05, 2023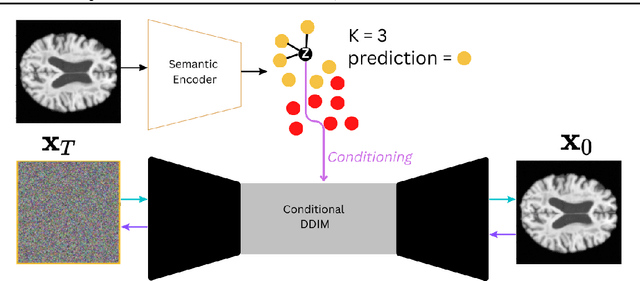
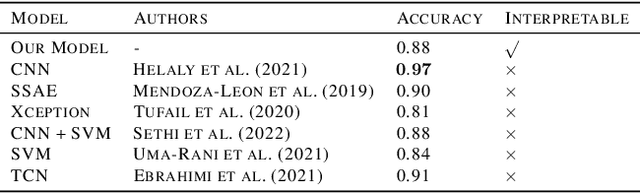
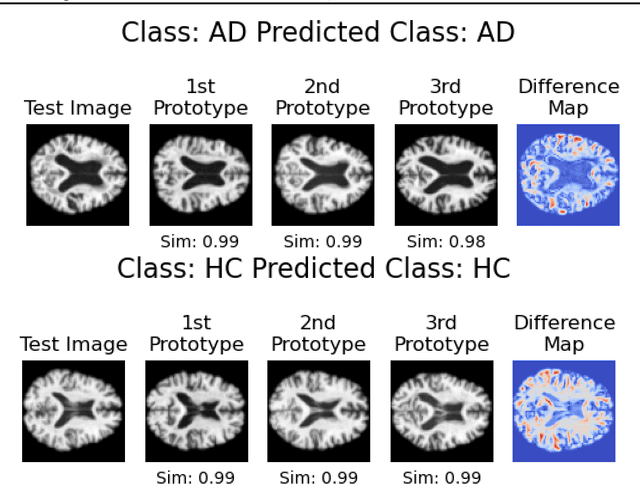
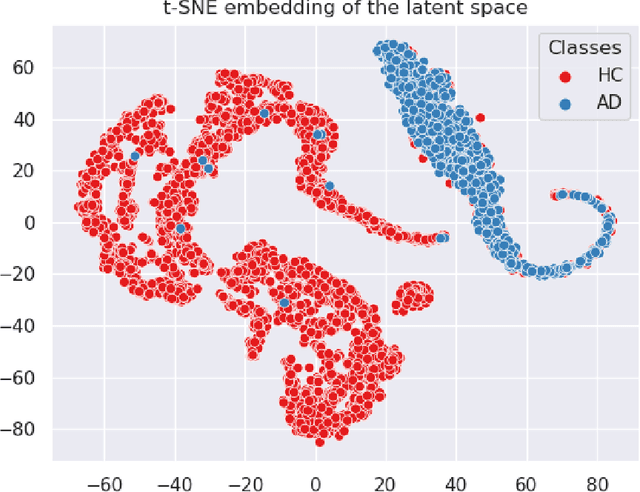
In visual object classification, humans often justify their choices by comparing objects to prototypical examples within that class. We may therefore increase the interpretability of deep learning models by imbuing them with a similar style of reasoning. In this work, we apply this principle by classifying Alzheimer's Disease based on the similarity of images to training examples within the latent space. We use a contrastive loss combined with a diffusion autoencoder backbone, to produce a semantically meaningful latent space, such that neighbouring latents have similar image-level features. We achieve a classification accuracy comparable to black box approaches on a dataset of 2D MRI images, whilst producing human interpretable model explanations. Therefore, this work stands as a contribution to the pertinent development of accurate and interpretable deep learning within medical imaging.