 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn X-Ray Is Worth 15 Features: Sparse Autoencoders for Interpretable Radiology Report Generation
Oct 04, 2024Radiological services are experiencing unprecedented demand, leading to increased interest in automating radiology report generation. Existing Vision-Language Models (VLMs) suffer from hallucinations, lack interpretability, and require expensive fine-tuning. We introduce SAE-Rad, which uses sparse autoencoders (SAEs) to decompose latent representations from a pre-trained vision transformer into human-interpretable features. Our hybrid architecture combines state-of-the-art SAE advancements, achieving accurate latent reconstructions while maintaining sparsity. Using an off-the-shelf language model, we distil ground-truth reports into radiological descriptions for each SAE feature, which we then compile into a full report for each image, eliminating the need for fine-tuning large models for this task. To the best of our knowledge, SAE-Rad represents the first instance of using mechanistic interpretability techniques explicitly for a downstream multi-modal reasoning task. On the MIMIC-CXR dataset, SAE-Rad achieves competitive radiology-specific metrics compared to state-of-the-art models while using significantly fewer computational resources for training. Qualitative analysis reveals that SAE-Rad learns meaningful visual concepts and generates reports aligning closely with expert interpretations. Our results suggest that SAEs can enhance multimodal reasoning in healthcare, providing a more interpretable alternative to existing VLMs.
Comparing Optimization Targets for Contrast-Consistent Search
Nov 01, 2023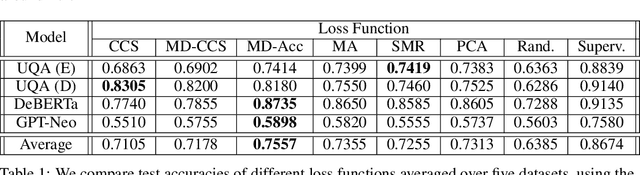
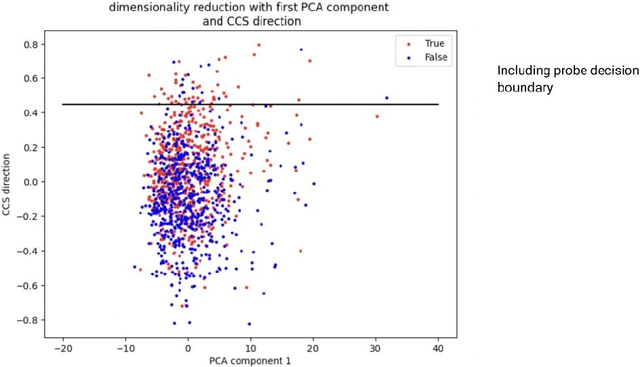
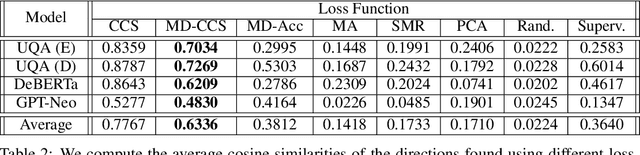
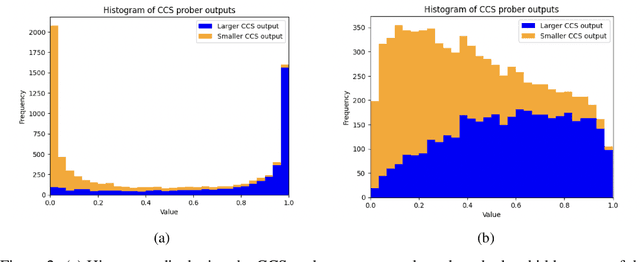
We investigate the optimization target of Contrast-Consistent Search (CCS), which aims to recover the internal representations of truth of a large language model. We present a new loss function that we call the Midpoint-Displacement (MD) loss function. We demonstrate that for a certain hyper-parameter value this MD loss function leads to a prober with very similar weights to CCS. We further show that this hyper-parameter is not optimal and that with a better hyper-parameter the MD loss function attains a higher test accuracy than CCS.