 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Feature Labeling with Token-Space Gradient Descent
Apr 01, 2025We present a novel approach to feature labeling using gradient descent in token-space. While existing methods typically use language models to generate hypotheses about feature meanings, our method directly optimizes label representations by using a language model as a discriminator to predict feature activations. We formulate this as a multi-objective optimization problem in token-space, balancing prediction accuracy, entropy minimization, and linguistic naturalness. Our proof-of-concept experiments demonstrate successful convergence to interpretable single-token labels across diverse domains, including features for detecting animals, mammals, Chinese text, and numbers. Although our current implementation is constrained to single-token labels and relatively simple features, the results suggest that token-space gradient descent could become a valuable addition to the interpretability researcher's toolkit.
Comparing Optimization Targets for Contrast-Consistent Search
Nov 01, 2023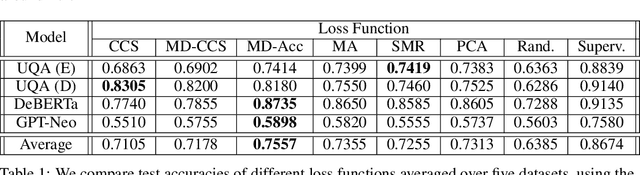
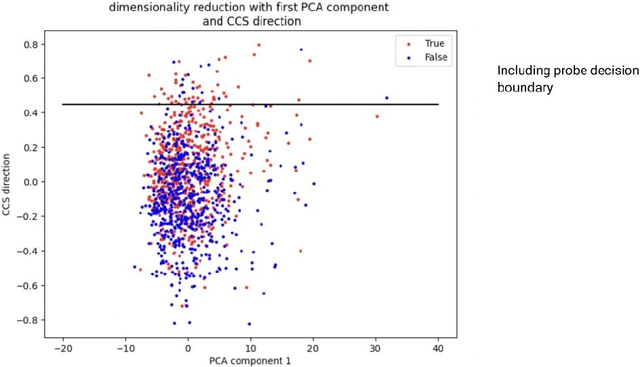
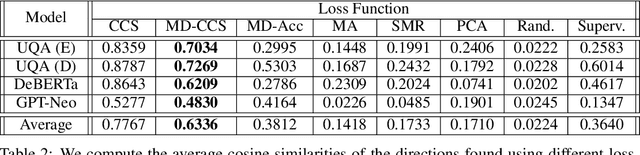
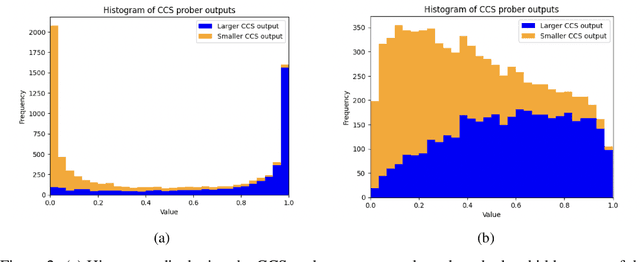
We investigate the optimization target of Contrast-Consistent Search (CCS), which aims to recover the internal representations of truth of a large language model. We present a new loss function that we call the Midpoint-Displacement (MD) loss function. We demonstrate that for a certain hyper-parameter value this MD loss function leads to a prober with very similar weights to CCS. We further show that this hyper-parameter is not optimal and that with a better hyper-parameter the MD loss function attains a higher test accuracy than CCS.