 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedImageInsight: An Open-Source Embedding Model for General Domain Medical Imaging
Oct 09, 2024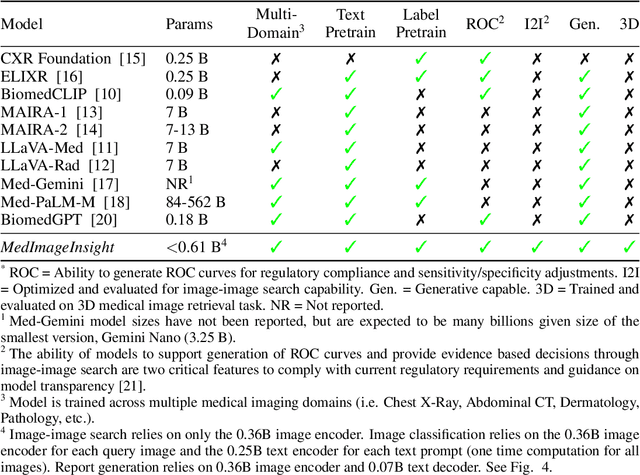
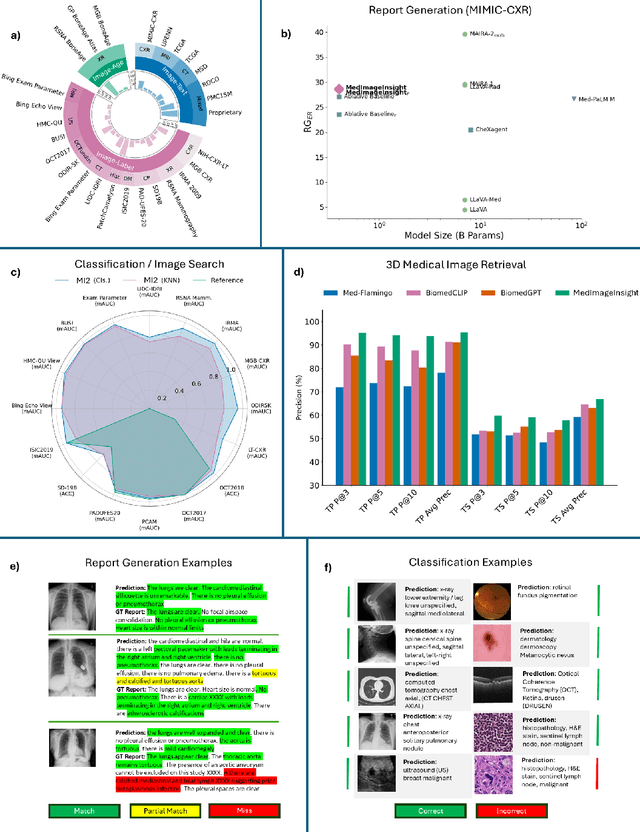
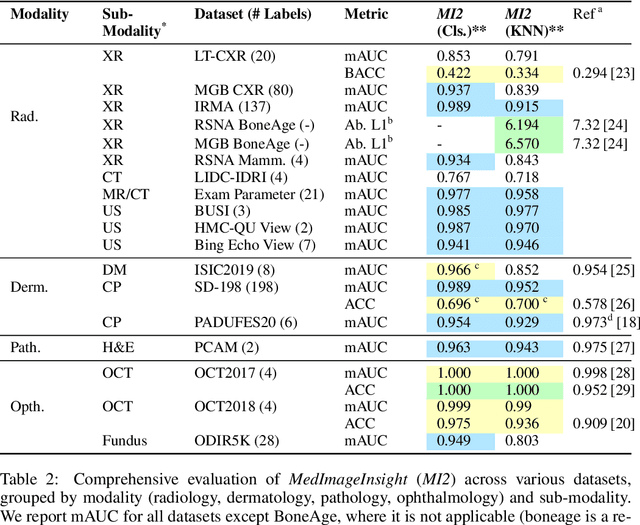
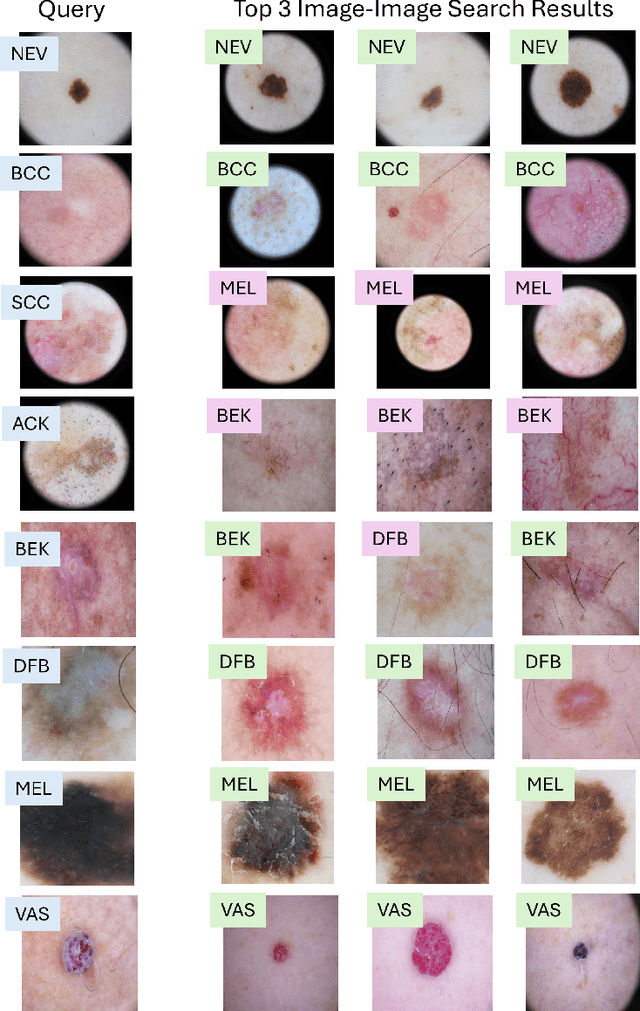
In this work, we present MedImageInsight, an open-source medical imaging embedding model. MedImageInsight is trained on medical images with associated text and labels across a diverse collection of domains, including X-Ray, CT, MRI, dermoscopy, OCT, fundus photography, ultrasound, histopathology, and mammography. Rigorous evaluations demonstrate MedImageInsight's ability to achieve state-of-the-art (SOTA) or human expert level performance across classification, image-image search, and fine-tuning tasks. Specifically, on public datasets, MedImageInsight achieves SOTA in CT 3D medical image retrieval, as well as SOTA in disease classification and search for chest X-ray, dermatology, and OCT imaging. Furthermore, MedImageInsight achieves human expert performance in bone age estimation (on both public and partner data), as well as AUC above 0.9 in most other domains. When paired with a text decoder, MedImageInsight achieves near SOTA level single image report findings generation with less than 10\% the parameters of other models. Compared to fine-tuning GPT-4o with only MIMIC-CXR data for the same task, MedImageInsight outperforms in clinical metrics, but underperforms on lexical metrics where GPT-4o sets a new SOTA. Importantly for regulatory purposes, MedImageInsight can generate ROC curves, adjust sensitivity and specificity based on clinical need, and provide evidence-based decision support through image-image search (which can also enable retrieval augmented generation). In an independent clinical evaluation of image-image search in chest X-ray, MedImageInsight outperformed every other publicly available foundation model evaluated by large margins (over 6 points AUC), and significantly outperformed other models in terms of AI fairness (across age and gender). We hope releasing MedImageInsight will help enhance collective progress in medical imaging AI research and development.
An X-Ray Is Worth 15 Features: Sparse Autoencoders for Interpretable Radiology Report Generation
Oct 04, 2024Radiological services are experiencing unprecedented demand, leading to increased interest in automating radiology report generation. Existing Vision-Language Models (VLMs) suffer from hallucinations, lack interpretability, and require expensive fine-tuning. We introduce SAE-Rad, which uses sparse autoencoders (SAEs) to decompose latent representations from a pre-trained vision transformer into human-interpretable features. Our hybrid architecture combines state-of-the-art SAE advancements, achieving accurate latent reconstructions while maintaining sparsity. Using an off-the-shelf language model, we distil ground-truth reports into radiological descriptions for each SAE feature, which we then compile into a full report for each image, eliminating the need for fine-tuning large models for this task. To the best of our knowledge, SAE-Rad represents the first instance of using mechanistic interpretability techniques explicitly for a downstream multi-modal reasoning task. On the MIMIC-CXR dataset, SAE-Rad achieves competitive radiology-specific metrics compared to state-of-the-art models while using significantly fewer computational resources for training. Qualitative analysis reveals that SAE-Rad learns meaningful visual concepts and generates reports aligning closely with expert interpretations. Our results suggest that SAEs can enhance multimodal reasoning in healthcare, providing a more interpretable alternative to existing VLMs.
Exploring the Boundaries of GPT-4 in Radiology
Oct 23, 2023



The recent success of general-domain large language models (LLMs) has significantly changed the natural language processing paradigm towards a unified foundation model across domains and applications. In this paper, we focus on assessing the performance of GPT-4, the most capable LLM so far, on the text-based applications for radiology reports, comparing against state-of-the-art (SOTA) radiology-specific models. Exploring various prompting strategies, we evaluated GPT-4 on a diverse range of common radiology tasks and we found GPT-4 either outperforms or is on par with current SOTA radiology models. With zero-shot prompting, GPT-4 already obtains substantial gains ($\approx$ 10% absolute improvement) over radiology models in temporal sentence similarity classification (accuracy) and natural language inference ($F_1$). For tasks that require learning dataset-specific style or schema (e.g. findings summarisation), GPT-4 improves with example-based prompting and matches supervised SOTA. Our extensive error analysis with a board-certified radiologist shows GPT-4 has a sufficient level of radiology knowledge with only occasional errors in complex context that require nuanced domain knowledge. For findings summarisation, GPT-4 outputs are found to be overall comparable with existing manually-written impressions.
Learning to Exploit Temporal Structure for Biomedical Vision-Language Processing
Jan 11, 2023


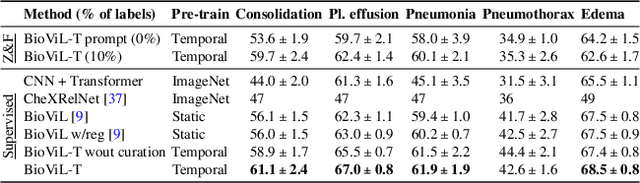
Self-supervised learning in vision-language processing exploits semantic alignment between imaging and text modalities. Prior work in biomedical VLP has mostly relied on the alignment of single image and report pairs even though clinical notes commonly refer to prior images. This does not only introduce poor alignment between the modalities but also a missed opportunity to exploit rich self-supervision through existing temporal content in the data. In this work, we explicitly account for prior images and reports when available during both training and fine-tuning. Our approach, named BioViL-T, uses a CNN-Transformer hybrid multi-image encoder trained jointly with a text model. It is designed to be versatile to arising challenges such as pose variations and missing input images across time. The resulting model excels on downstream tasks both in single- and multi-image setups, achieving state-of-the-art performance on (I) progression classification, (II) phrase grounding, and (III) report generation, whilst offering consistent improvements on disease classification and sentence-similarity tasks. We release a novel multi-modal temporal benchmark dataset, MS-CXR-T, to quantify the quality of vision-language representations in terms of temporal semantics. Our experimental results show the advantages of incorporating prior images and reports to make most use of the data.
Making the Most of Text Semantics to Improve Biomedical Vision--Language Processing
Apr 21, 2022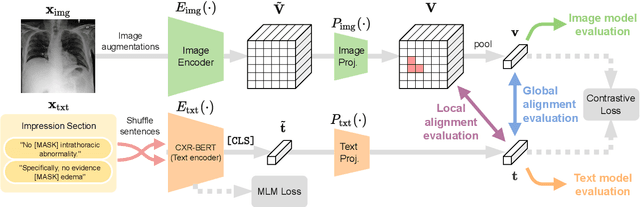

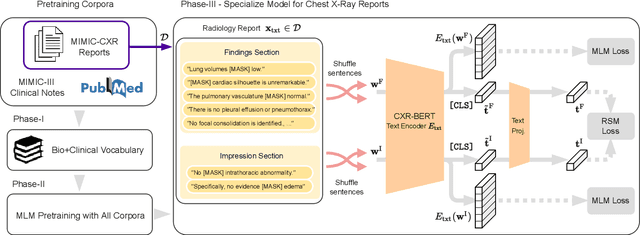

Multi-modal data abounds in biomedicine, such as radiology images and reports. Interpreting this data at scale is essential for improving clinical care and accelerating clinical research. Biomedical text with its complex semantics poses additional challenges in vision-language modelling compared to the general domain, and previous work has used insufficiently adapted models that lack domain-specific language understanding. In this paper, we show that principled textual semantic modelling can substantially improve contrastive learning in self-supervised vision--language processing. We release a language model that achieves state-of-the-art results in radiology natural language inference through its improved vocabulary and novel language pretraining objective leveraging semantics and discourse characteristics in radiology reports. Further, we propose a self-supervised joint vision--language approach with a focus on better text modelling. It establishes new state of the art results on a wide range of publicly available benchmarks, in part by leveraging our new domain-specific language model. We release a new dataset with locally-aligned phrase grounding annotations by radiologists to facilitate the study of complex semantic modelling in biomedical vision--language processing. A broad evaluation, including on this new dataset, shows that our contrastive learning approach, aided by textual-semantic modelling, outperforms prior methods in segmentation tasks, despite only using a global-alignment objective.
Predicting the impact of treatments over time with uncertainty aware neural differential equations
Feb 24, 2022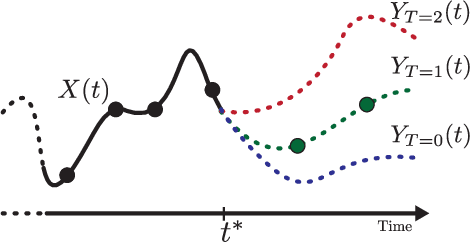
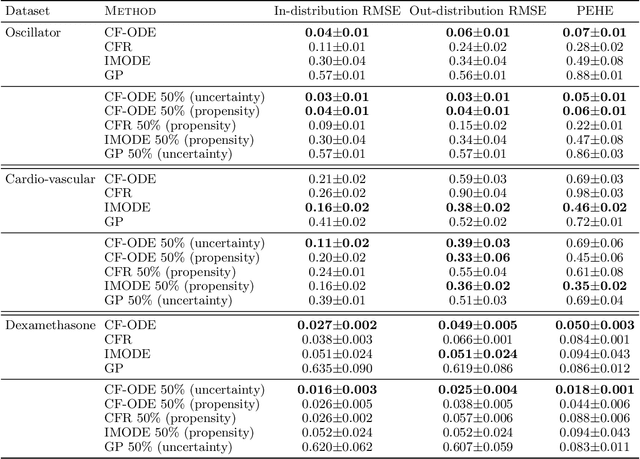
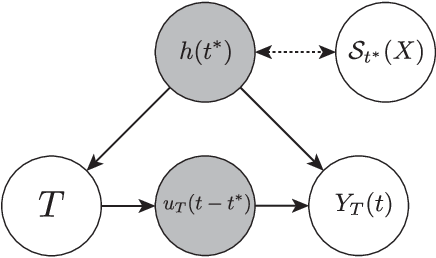
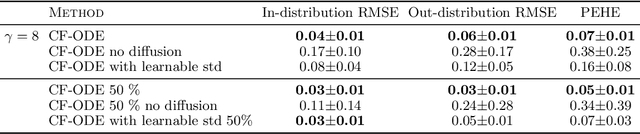
Predicting the impact of treatments from observational data only still represents a majorchallenge despite recent significant advances in time series modeling. Treatment assignments are usually correlated with the predictors of the response, resulting in a lack of data support for counterfactual predictions and therefore in poor quality estimates. Developments in causal inference have lead to methods addressing this confounding by requiring a minimum level of overlap. However,overlap is difficult to assess and usually notsatisfied in practice. In this work, we propose Counterfactual ODE (CF-ODE), a novel method to predict the impact of treatments continuously over time using Neural Ordinary Differential Equations equipped with uncertainty estimates. This allows to specifically assess which treatment outcomes can be reliably predicted. We demonstrate over several longitudinal data sets that CF-ODE provides more accurate predictions and more reliable uncertainty estimates than previously available methods.
Temporal Pointwise Convolutional Networks for Length of Stay Prediction in the Intensive Care Unit
Jul 18, 2020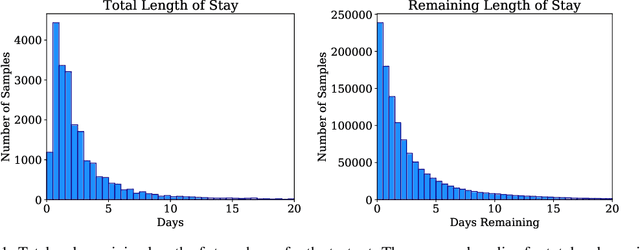
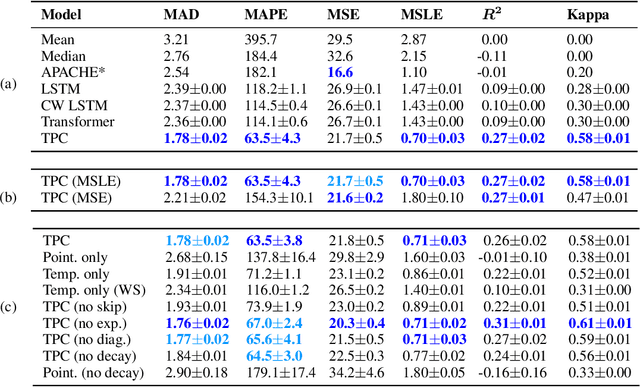
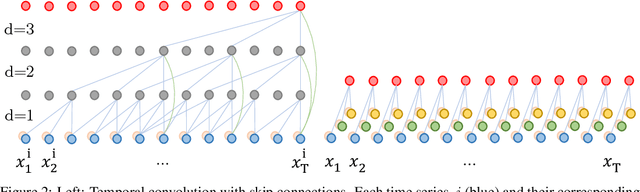
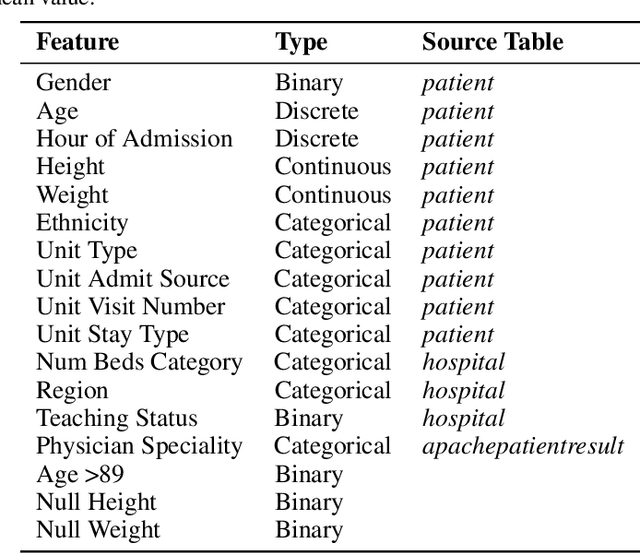
The pressure of ever-increasing patient demand and budget restrictions make hospital bed management a daily challenge for clinical staff. Most critical is the efficient allocation of resource-heavy Intensive Care Unit (ICU) beds to the patients who need life support. Central to solving this problem is knowing for how long the current set of ICU patients are likely to stay in the unit. In this work, we propose a new deep learning model based on the combination of temporal convolution and pointwise (1x1) convolution, to solve the length of stay prediction task on the eICU critical care dataset. The model - which we refer to as Temporal Pointwise Convolution (TPC) - is specifically designed to mitigate for common challenges with Electronic Health Records, such as skewness, irregular sampling and missing data. In doing so, we have achieved significant performance benefits of 18-51% (metric dependent) over the commonly used Long-Short Term Memory (LSTM) network, and the multi-head self-attention network known as the Transformer.
Predicting Length of Stay in the Intensive Care Unit with Temporal Pointwise Convolutional Networks
Jun 29, 2020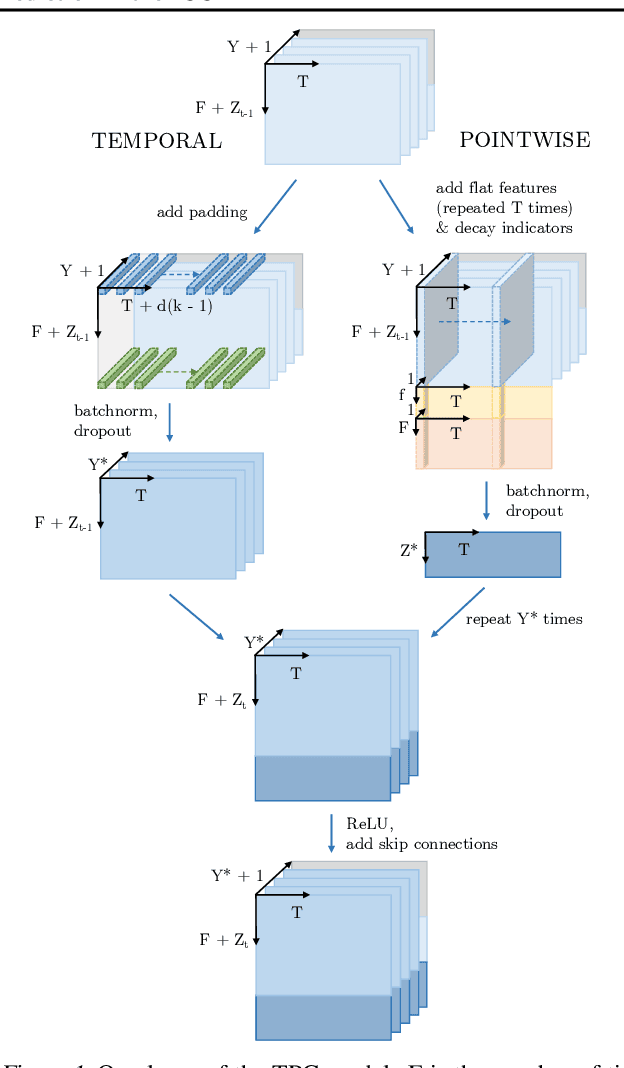
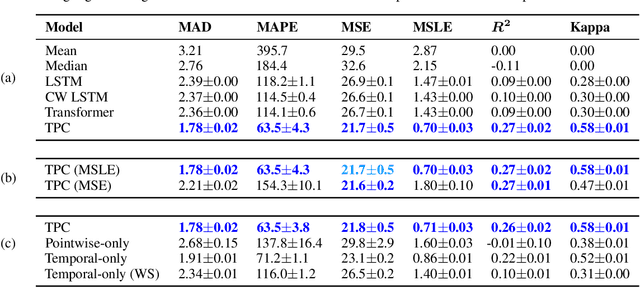
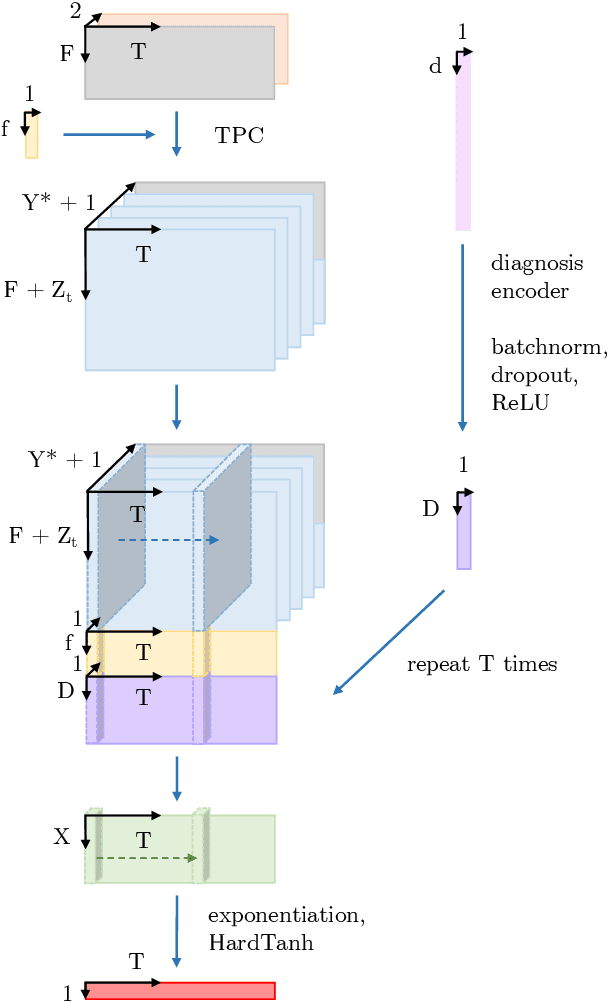
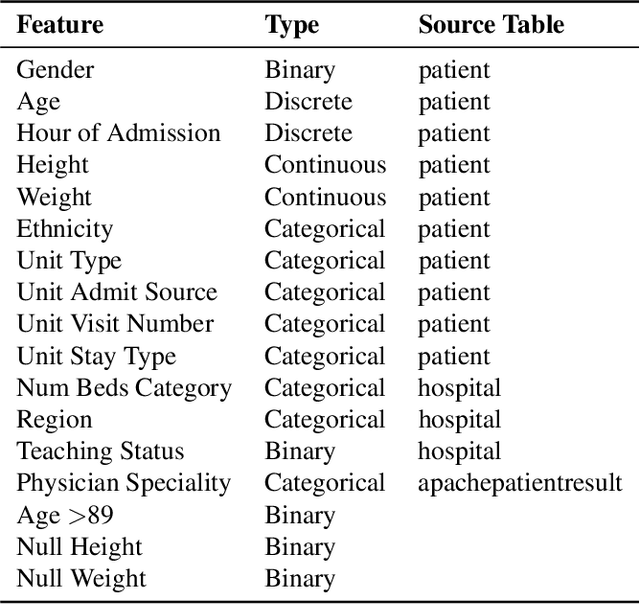
The pressure of ever-increasing patient demand and budget restrictions make hospital bed management a daily challenge for clinical staff. Most critical is the efficient allocation of resource-heavy Intensive Care Unit (ICU) beds to the patients who need life support. Central to solving this problem is knowing for how long the current set of ICU patients are likely to stay in the unit. In this work, we propose a new deep learning model based on the combination of temporal convolution and pointwise (1x1) convolution, to solve the length of stay prediction task on the eICU critical care dataset. The model - which we refer to as Temporal Pointwise Convolution (TPC) - is specifically designed to mitigate for common challenges with Electronic Health Records, such as skewness, irregular sampling and missing data. In doing so, we have achieved significant performance benefits of 18-51% (metric dependent) over the commonly used Long-Short Term Memory (LSTM) network, and the multi-head self-attention network known as the Transformer.