 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Boundaries of GPT-4 in Radiology
Oct 23, 2023



The recent success of general-domain large language models (LLMs) has significantly changed the natural language processing paradigm towards a unified foundation model across domains and applications. In this paper, we focus on assessing the performance of GPT-4, the most capable LLM so far, on the text-based applications for radiology reports, comparing against state-of-the-art (SOTA) radiology-specific models. Exploring various prompting strategies, we evaluated GPT-4 on a diverse range of common radiology tasks and we found GPT-4 either outperforms or is on par with current SOTA radiology models. With zero-shot prompting, GPT-4 already obtains substantial gains ($\approx$ 10% absolute improvement) over radiology models in temporal sentence similarity classification (accuracy) and natural language inference ($F_1$). For tasks that require learning dataset-specific style or schema (e.g. findings summarisation), GPT-4 improves with example-based prompting and matches supervised SOTA. Our extensive error analysis with a board-certified radiologist shows GPT-4 has a sufficient level of radiology knowledge with only occasional errors in complex context that require nuanced domain knowledge. For findings summarisation, GPT-4 outputs are found to be overall comparable with existing manually-written impressions.
Large-Scale Domain-Specific Pretraining for Biomedical Vision-Language Processing
Mar 02, 2023Contrastive pretraining on parallel image-text data has attained great success in vision-language processing (VLP), as exemplified by CLIP and related methods. However, prior explorations tend to focus on general domains in the web. Biomedical images and text are rather different, but publicly available datasets are small and skew toward chest X-ray, thus severely limiting progress. In this paper, we conducted by far the largest study on biomedical VLP, using 15 million figure-caption pairs extracted from biomedical research articles in PubMed Central. Our dataset (PMC-15M) is two orders of magnitude larger than existing biomedical image-text datasets such as MIMIC-CXR, and spans a diverse range of biomedical images. The standard CLIP method is suboptimal for the biomedical domain. We propose BiomedCLIP with domain-specific adaptations tailored to biomedical VLP. We conducted extensive experiments and ablation studies on standard biomedical imaging tasks from retrieval to classification to visual question-answering (VQA). BiomedCLIP established new state of the art in a wide range of standard datasets, substantially outperformed prior VLP approaches. Surprisingly, BiomedCLIP even outperformed radiology-specific state-of-the-art models such as BioViL on radiology-specific tasks such as RSNA pneumonia detection, thus highlighting the utility in large-scale pretraining across all biomedical image types. We will release our models at https://aka.ms/biomedclip to facilitate future research in biomedical VLP.
Towards Structuring Real-World Data at Scale: Deep Learning for Extracting Key Oncology Information from Clinical Text with Patient-Level Supervision
Mar 20, 2022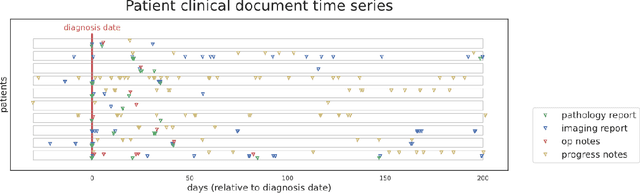
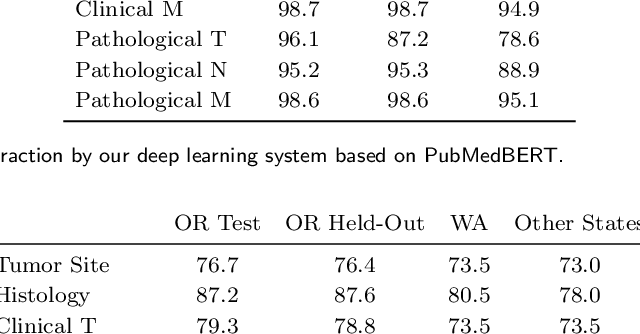
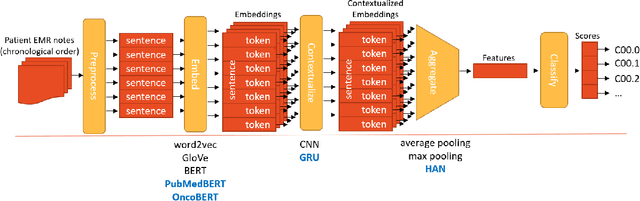
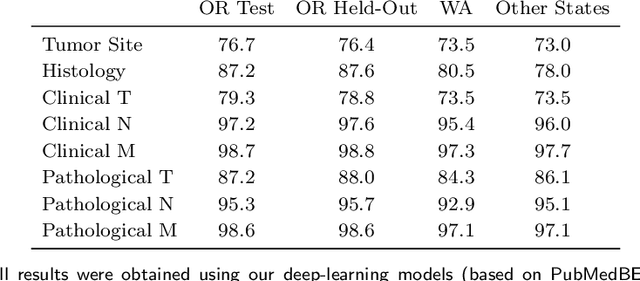
Objective: The majority of detailed patient information in real-world data (RWD) is only consistently available in free-text clinical documents. Manual curation is expensive and time-consuming. Developing natural language processing (NLP) methods for structuring RWD is thus essential for scaling real-world evidence generation. Materials and Methods: Traditional rule-based systems are vulnerable to the prevalent linguistic variations and ambiguities in clinical text, and prior applications of machine-learning methods typically require sentence-level or report-level labeled examples that are hard to produce at scale. We propose leveraging patient-level supervision from medical registries, which are often readily available and capture key patient information, for general RWD applications. To combat the lack of sentence-level or report-level annotations, we explore advanced deep-learning methods by combining domain-specific pretraining, recurrent neural networks, and hierarchical attention. Results: We conduct an extensive study on 135,107 patients from the cancer registry of a large integrated delivery network (IDN) comprising healthcare systems in five western US states. Our deep learning methods attain test AUROC of 94-99% for key tumor attributes and comparable performance on held-out data from separate health systems and states. Discussion and Conclusion: Ablation results demonstrate clear superiority of these advanced deep-learning methods over prior approaches. Error analysis shows that our NLP system sometimes even corrects errors in registrar labels. We also conduct a preliminary investigation in accelerating registry curation and general RWD structuring via assisted curation for over 1.2 million cancer patients in this healthcare network.
Fine-Tuning Large Neural Language Models for Biomedical Natural Language Processing
Dec 15, 2021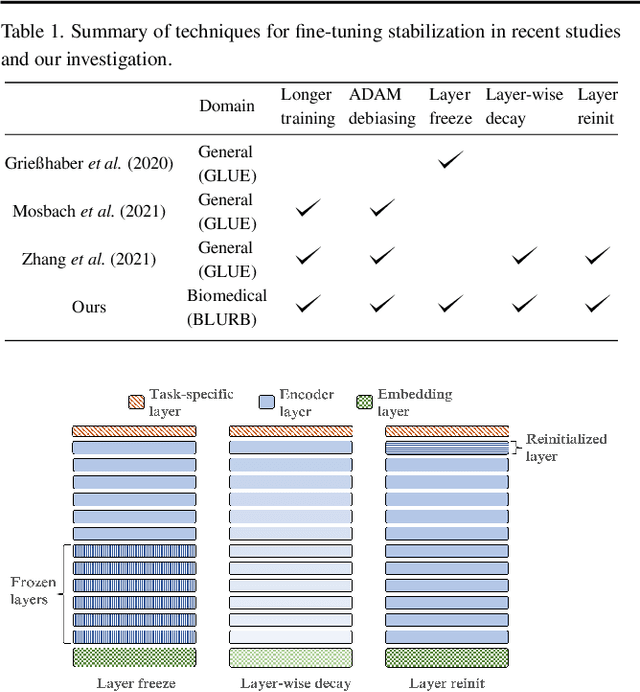
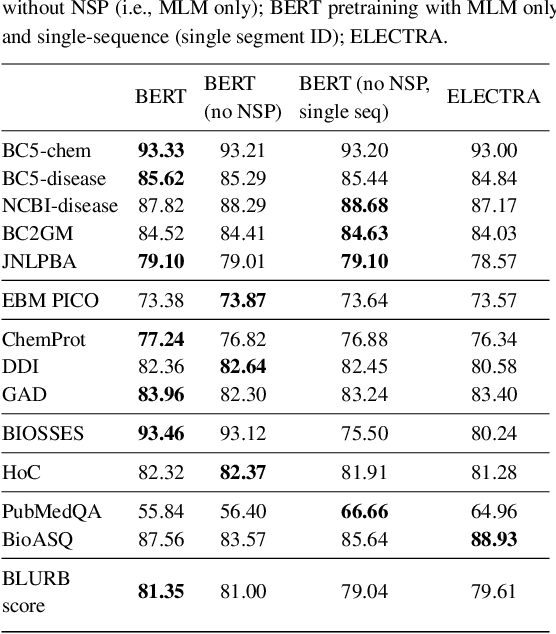
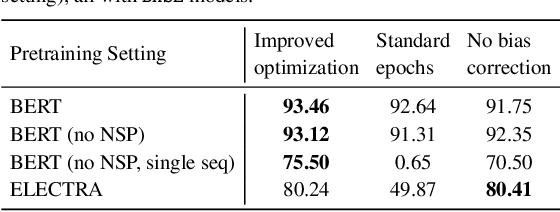
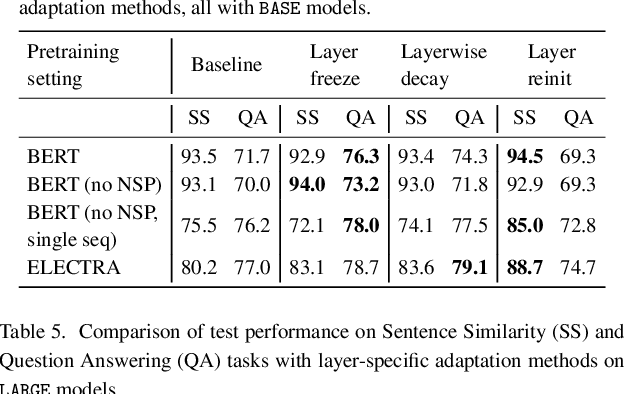
Motivation: A perennial challenge for biomedical researchers and clinical practitioners is to stay abreast with the rapid growth of publications and medical notes. Natural language processing (NLP) has emerged as a promising direction for taming information overload. In particular, large neural language models facilitate transfer learning by pretraining on unlabeled text, as exemplified by the successes of BERT models in various NLP applications. However, fine-tuning such models for an end task remains challenging, especially with small labeled datasets, which are common in biomedical NLP. Results: We conduct a systematic study on fine-tuning stability in biomedical NLP. We show that finetuning performance may be sensitive to pretraining settings, especially in low-resource domains. Large models have potential to attain better performance, but increasing model size also exacerbates finetuning instability. We thus conduct a comprehensive exploration of techniques for addressing fine-tuning instability. We show that these techniques can substantially improve fine-tuning performance for lowresource biomedical NLP applications. Specifically, freezing lower layers is helpful for standard BERT-BASE models, while layerwise decay is more effective for BERT-LARGE and ELECTRA models. For low-resource text similarity tasks such as BIOSSES, reinitializing the top layer is the optimal strategy. Overall, domainspecific vocabulary and pretraining facilitate more robust models for fine-tuning. Based on these findings, we establish new state of the art on a wide range of biomedical NLP applications. Availability and implementation: To facilitate progress in biomedical NLP, we release our state-of-the-art pretrained and fine-tuned models: https://aka.ms/BLURB.
Domain-Specific Pretraining for Vertical Search: Case Study on Biomedical Literature
Jun 25, 2021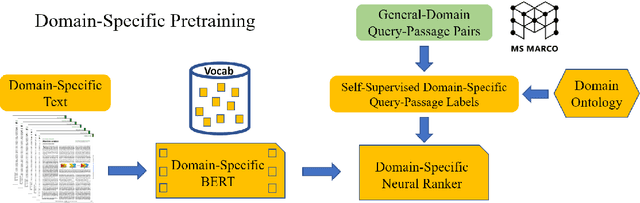
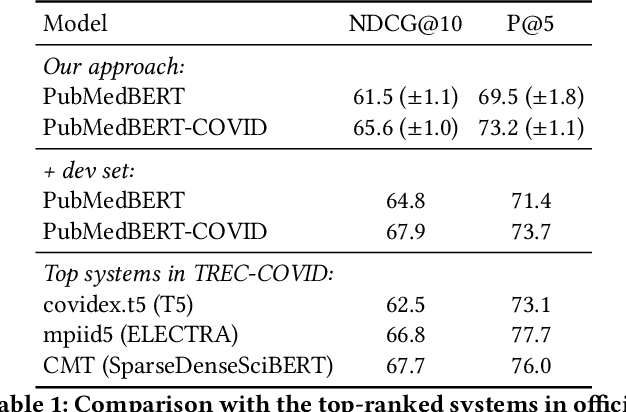

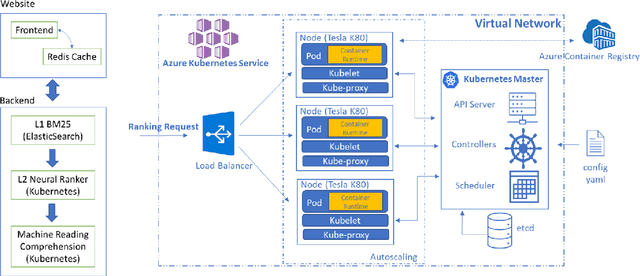
Information overload is a prevalent challenge in many high-value domains. A prominent case in point is the explosion of the biomedical literature on COVID-19, which swelled to hundreds of thousands of papers in a matter of months. In general, biomedical literature expands by two papers every minute, totalling over a million new papers every year. Search in the biomedical realm, and many other vertical domains is challenging due to the scarcity of direct supervision from click logs. Self-supervised learning has emerged as a promising direction to overcome the annotation bottleneck. We propose a general approach for vertical search based on domain-specific pretraining and present a case study for the biomedical domain. Despite being substantially simpler and not using any relevance labels for training or development, our method performs comparably or better than the best systems in the official TREC-COVID evaluation, a COVID-related biomedical search competition. Using distributed computing in modern cloud infrastructure, our system can scale to tens of millions of articles on PubMed and has been deployed as Microsoft Biomedical Search, a new search experience for biomedical literature: https://aka.ms/biomedsearch.
Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing
Aug 20, 2020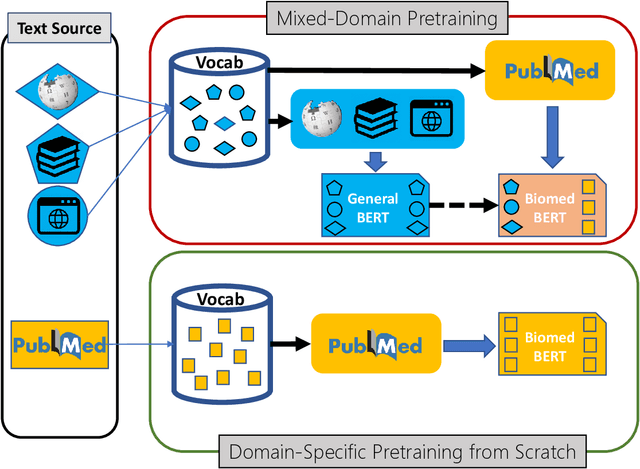
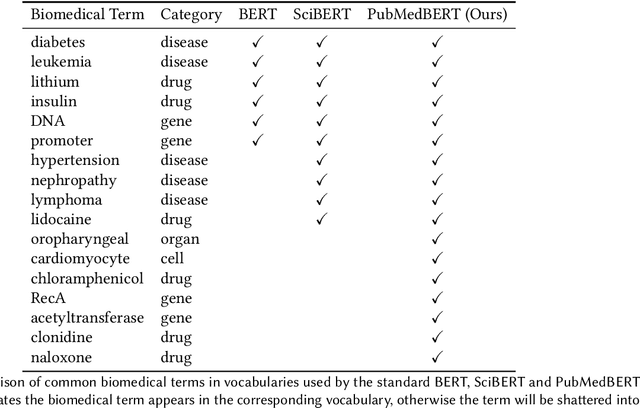
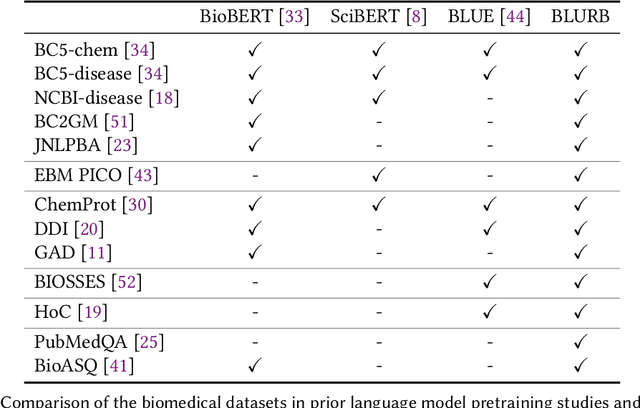
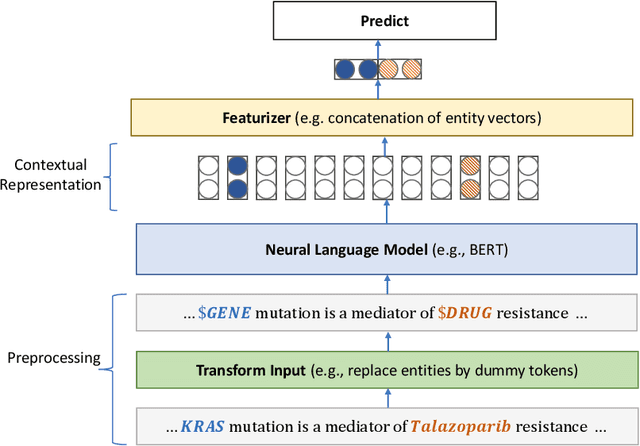
Pretraining large neural language models, such as BERT, has led to impressive gains on many natural language processing (NLP) tasks. However, most pretraining efforts focus on general domain corpora, such as newswire and Web. A prevailing assumption is that even domain-specific pretraining can benefit by starting from general-domain language models. In this paper, we challenge this assumption by showing that for domains with abundant unlabeled text, such as biomedicine, pretraining language models from scratch results in substantial gains over continual pretraining of general-domain language models. To facilitate this investigation, we compile a comprehensive biomedical NLP benchmark from publicly-available datasets. Our experiments show that domain-specific pretraining serves as a solid foundation for a wide range of biomedical NLP tasks, leading to new state-of-the-art results across the board. Further, in conducting a thorough evaluation of modeling choices, both for pretraining and task-specific fine-tuning, we discover that some common practices are unnecessary with BERT models, such as using complex tagging schemes in named entity recognition (NER). To help accelerate research in biomedical NLP, we have released our state-of-the-art pretrained and task-specific models for the community, and created a leaderboard featuring our BLURB benchmark (short for Biomedical Language Understanding & Reasoning Benchmark) at https://aka.ms/BLURB.