 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Large Neural Language Models for Biomedical Natural Language Processing
Paper and Code
Dec 15, 2021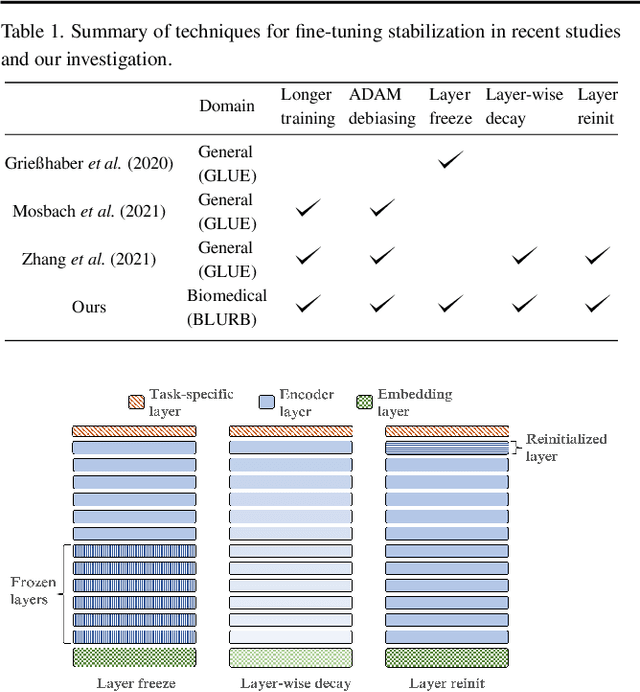
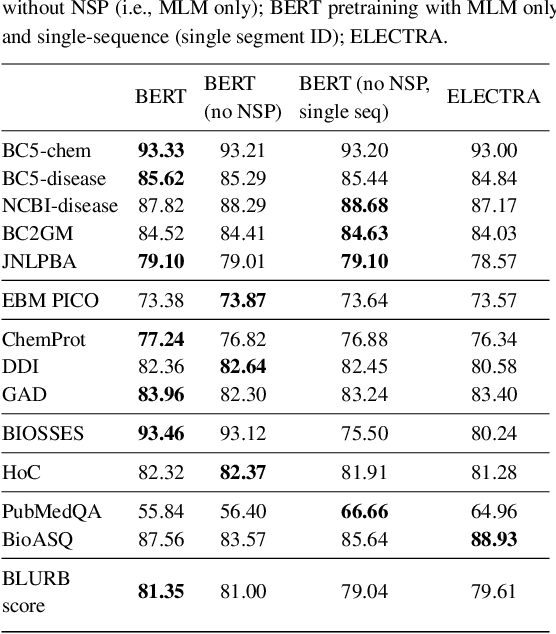
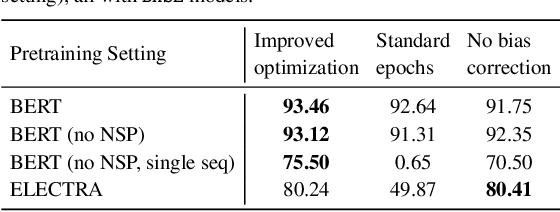
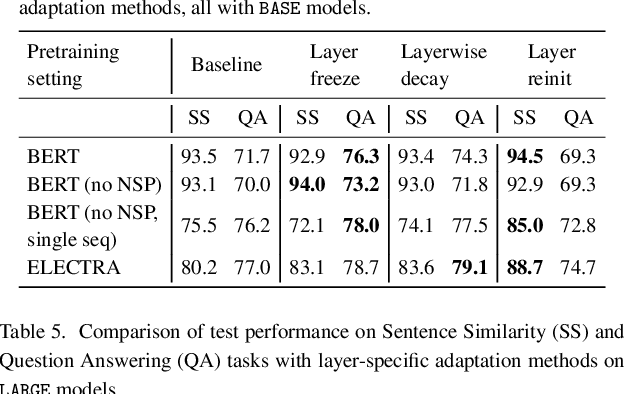
Motivation: A perennial challenge for biomedical researchers and clinical practitioners is to stay abreast with the rapid growth of publications and medical notes. Natural language processing (NLP) has emerged as a promising direction for taming information overload. In particular, large neural language models facilitate transfer learning by pretraining on unlabeled text, as exemplified by the successes of BERT models in various NLP applications. However, fine-tuning such models for an end task remains challenging, especially with small labeled datasets, which are common in biomedical NLP. Results: We conduct a systematic study on fine-tuning stability in biomedical NLP. We show that finetuning performance may be sensitive to pretraining settings, especially in low-resource domains. Large models have potential to attain better performance, but increasing model size also exacerbates finetuning instability. We thus conduct a comprehensive exploration of techniques for addressing fine-tuning instability. We show that these techniques can substantially improve fine-tuning performance for lowresource biomedical NLP applications. Specifically, freezing lower layers is helpful for standard BERT-BASE models, while layerwise decay is more effective for BERT-LARGE and ELECTRA models. For low-resource text similarity tasks such as BIOSSES, reinitializing the top layer is the optimal strategy. Overall, domainspecific vocabulary and pretraining facilitate more robust models for fine-tuning. Based on these findings, we establish new state of the art on a wide range of biomedical NLP applications. Availability and implementation: To facilitate progress in biomedical NLP, we release our state-of-the-art pretrained and fine-tuned models: https://aka.ms/BLURB.