 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealthAgentBench: A Unified Benchmark Suite of Realistic Agentic Healthcare Environments for Challenging Frontier AI Agents
Jun 30, 2026As AI agents become increasingly capable of complex, long-horizon reasoning, rigorous and holistic evaluation is essential for measuring progress toward real-world healthcare applications. We introduce HealthAgentBench, a suite of 54 agentic healthcare tasks across 7 categories each with its unique environment. The benchmark suite spans diverse workflows throughout the patient journey and a broad range of modalities. Each task is designed to replicate an end-to-end clinical workflow: given minimal instructions, an agent must explore raw healthcare data, operate within a complex environment, and execute multi-step solutions that go beyond naive prompting. A final task success rate is reported to provide a single, interpretable metric for HealthAgentBench overall performance for each agent. Evaluating frontier agents on HealthAgentBench, we find that overall task success rate remains low, underscoring the difficulty of the suite. The strongest and the most cost effective agent, Codex GPT-5.5, achieves only approximately 42% success rate. Beyond aggregate performance, HealthAgentBench reveals nuanced strengths and weaknesses across task categories. Frontier agents show promise in automatically developing research modeling pipelines over EHR data, but medical imaging remains especially challenging, particularly for Claude Code models, while Codex GPT-5.5 shows emerging capability. Tasks that combine large search spaces with compositional reasoning requirements remain difficult for all current agents. Together, these results suggest that HealthAgentBench provides a challenging and realistic benchmark with substantial room for future progress. We release our benchmark at https://github.com/microsoft/HealthAgentBench.
Learning Sparse Visual Representations via Spatial-Semantic Factorization
Feb 02, 2026Self-supervised learning (SSL) faces a fundamental conflict between semantic understanding and image reconstruction. High-level semantic SSL (e.g., DINO) relies on global tokens that are forced to be location-invariant for augmentation alignment, a process that inherently discards the spatial coordinates required for reconstruction. Conversely, generative SSL (e.g., MAE) preserves dense feature grids for reconstruction but fails to produce high-level abstractions. We introduce STELLAR, a framework that resolves this tension by factorizing visual features into a low-rank product of semantic concepts and their spatial distributions. This disentanglement allows us to perform DINO-style augmentation alignment on the semantic tokens while maintaining the precise spatial mapping in the localization matrix necessary for pixel-level reconstruction. We demonstrate that as few as 16 sparse tokens under this factorized form are sufficient to simultaneously support high-quality reconstruction (2.60 FID) and match the semantic performance of dense backbones (79.10% ImageNet accuracy). Our results highlight STELLAR as a versatile sparse representation that bridges the gap between discriminative and generative vision by strategically separating semantic identity from spatial geometry. Code available at https://aka.ms/stellar.
Scaling medical imaging report generation with multimodal reinforcement learning
Jan 23, 2026Frontier models have demonstrated remarkable capabilities in understanding and reasoning with natural-language text, but they still exhibit major competency gaps in multimodal understanding and reasoning especially in high-value verticals such as biomedicine. Medical imaging report generation is a prominent example. Supervised fine-tuning can substantially improve performance, but they are prone to overfitting to superficial boilerplate patterns. In this paper, we introduce Universal Report Generation (UniRG) as a general framework for medical imaging report generation. By leveraging reinforcement learning as a unifying mechanism to directly optimize for evaluation metrics designed for end applications, UniRG can significantly improve upon supervised fine-tuning and attain durable generalization across diverse institutions and clinical practices. We trained UniRG-CXR on publicly available chest X-ray (CXR) data and conducted a thorough evaluation in CXR report generation with rigorous evaluation scenarios. On the authoritative ReXrank benchmark, UniRG-CXR sets new overall SOTA, outperforming prior state of the art by a wide margin.
CancerGUIDE: Cancer Guideline Understanding via Internal Disagreement Estimation
Sep 09, 2025
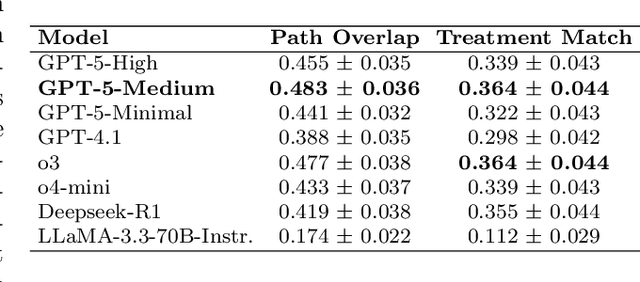
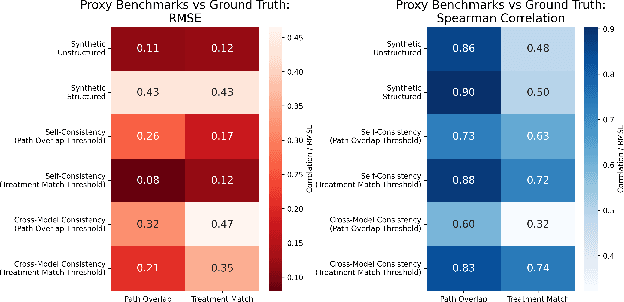

The National Comprehensive Cancer Network (NCCN) provides evidence-based guidelines for cancer treatment. Translating complex patient presentations into guideline-compliant treatment recommendations is time-intensive, requires specialized expertise, and is prone to error. Advances in large language model (LLM) capabilities promise to reduce the time required to generate treatment recommendations and improve accuracy. We present an LLM agent-based approach to automatically generate guideline-concordant treatment trajectories for patients with non-small cell lung cancer (NSCLC). Our contributions are threefold. First, we construct a novel longitudinal dataset of 121 cases of NSCLC patients that includes clinical encounters, diagnostic results, and medical histories, each expertly annotated with the corresponding NCCN guideline trajectories by board-certified oncologists. Second, we demonstrate that existing LLMs possess domain-specific knowledge that enables high-quality proxy benchmark generation for both model development and evaluation, achieving strong correlation (Spearman coefficient r=0.88, RMSE = 0.08) with expert-annotated benchmarks. Third, we develop a hybrid approach combining expensive human annotations with model consistency information to create both the agent framework that predicts the relevant guidelines for a patient, as well as a meta-classifier that verifies prediction accuracy with calibrated confidence scores for treatment recommendations (AUROC=0.800), a critical capability for communicating the accuracy of outputs, custom-tailoring tradeoffs in performance, and supporting regulatory compliance. This work establishes a framework for clinically viable LLM-based guideline adherence systems that balance accuracy, interpretability, and regulatory requirements while reducing annotation costs, providing a scalable pathway toward automated clinical decision support.
AURAD: Anatomy-Pathology Unified Radiology Synthesis with Progressive Representations
Sep 05, 2025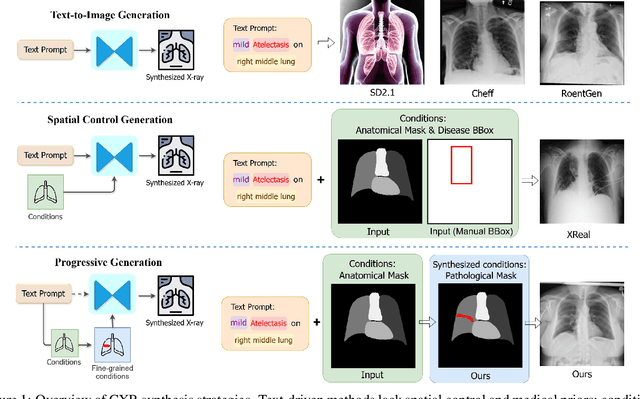

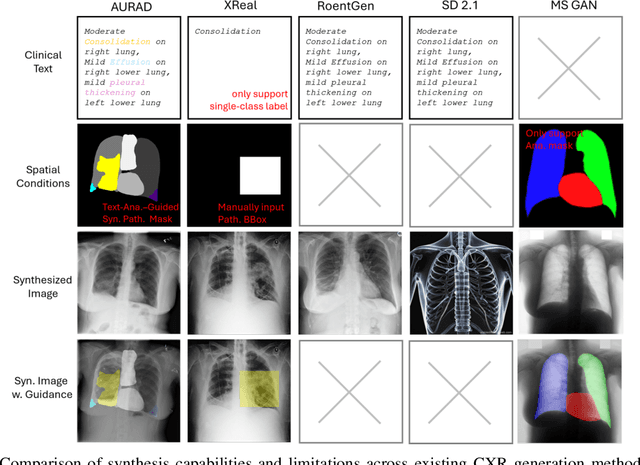
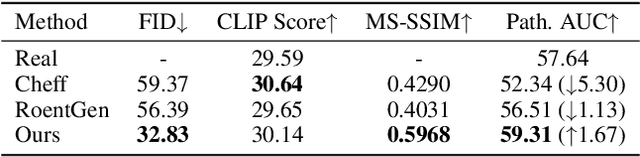
Medical image synthesis has become an essential strategy for augmenting datasets and improving model generalization in data-scarce clinical settings. However, fine-grained and controllable synthesis remains difficult due to limited high-quality annotations and domain shifts across datasets. Existing methods, often designed for natural images or well-defined tumors, struggle to generalize to chest radiographs, where disease patterns are morphologically diverse and tightly intertwined with anatomical structures. To address these challenges, we propose AURAD, a controllable radiology synthesis framework that jointly generates high-fidelity chest X-rays and pseudo semantic masks. Unlike prior approaches that rely on randomly sampled masks-limiting diversity, controllability, and clinical relevance-our method learns to generate masks that capture multi-pathology coexistence and anatomical-pathological consistency. It follows a progressive pipeline: pseudo masks are first generated from clinical prompts conditioned on anatomical structures, and then used to guide image synthesis. We also leverage pretrained expert medical models to filter outputs and ensure clinical plausibility. Beyond visual realism, the synthesized masks also serve as labels for downstream tasks such as detection and segmentation, bridging the gap between generative modeling and real-world clinical applications. Extensive experiments and blinded radiologist evaluations demonstrate the effectiveness and generalizability of our method across tasks and datasets. In particular, 78% of our synthesized images are classified as authentic by board-certified radiologists, and over 40% of predicted segmentation overlays are rated as clinically useful. All code, pre-trained models, and the synthesized dataset will be released upon publication.
X-Reasoner: Towards Generalizable Reasoning Across Modalities and Domains
May 06, 2025Recent proprietary models (e.g., o3) have begun to demonstrate strong multimodal reasoning capabilities. Yet, most existing open-source research concentrates on training text-only reasoning models, with evaluations limited to mainly mathematical and general-domain tasks. Therefore, it remains unclear how to effectively extend reasoning capabilities beyond text input and general domains. This paper explores a fundamental research question: Is reasoning generalizable across modalities and domains? Our findings support an affirmative answer: General-domain text-based post-training can enable such strong generalizable reasoning. Leveraging this finding, we introduce X-Reasoner, a vision-language model post-trained solely on general-domain text for generalizable reasoning, using a two-stage approach: an initial supervised fine-tuning phase with distilled long chain-of-thoughts, followed by reinforcement learning with verifiable rewards. Experiments show that X-Reasoner successfully transfers reasoning capabilities to both multimodal and out-of-domain settings, outperforming existing state-of-the-art models trained with in-domain and multimodal data across various general and medical benchmarks (Figure 1). Additionally, we find that X-Reasoner's performance in specialized domains can be further enhanced through continued training on domain-specific text-only data. Building upon this, we introduce X-Reasoner-Med, a medical-specialized variant that achieves new state of the art on numerous text-only and multimodal medical benchmarks.
Boltzmann Attention Sampling for Image Analysis with Small Objects
Mar 04, 2025Detecting and segmenting small objects, such as lung nodules and tumor lesions, remains a critical challenge in image analysis. These objects often occupy less than 0.1% of an image, making traditional transformer architectures inefficient and prone to performance degradation due to redundant attention computations on irrelevant regions. Existing sparse attention mechanisms rely on rigid hierarchical structures, which are poorly suited for detecting small, variable, and uncertain object locations. In this paper, we propose BoltzFormer, a novel transformer-based architecture designed to address these challenges through dynamic sparse attention. BoltzFormer identifies and focuses attention on relevant areas by modeling uncertainty using a Boltzmann distribution with an annealing schedule. Initially, a higher temperature allows broader area sampling in early layers, when object location uncertainty is greatest. As the temperature decreases in later layers, attention becomes more focused, enhancing efficiency and accuracy. BoltzFormer seamlessly integrates into existing transformer architectures via a modular Boltzmann attention sampling mechanism. Comprehensive evaluations on benchmark datasets demonstrate that BoltzFormer significantly improves segmentation performance for small objects while reducing attention computation by an order of magnitude compared to previous state-of-the-art methods.
Universal Abstraction: Harnessing Frontier Models to Structure Real-World Data at Scale
Feb 02, 2025



The vast majority of real-world patient information resides in unstructured clinical text, and the process of medical abstraction seeks to extract and normalize structured information from this unstructured input. However, traditional medical abstraction methods can require significant manual efforts that can include crafting rules or annotating training labels, limiting scalability. In this paper, we propose UniMedAbstractor (UMA), a zero-shot medical abstraction framework leveraging Large Language Models (LLMs) through a modular and customizable prompt template. We refer to our approach as universal abstraction as it can quickly scale to new attributes through its universal prompt template without curating attribute-specific training labels or rules. We evaluate UMA for oncology applications, focusing on fifteen key attributes representing the cancer patient journey, from short-context attributes (e.g., performance status, treatment) to complex long-context attributes requiring longitudinal reasoning (e.g., tumor site, histology, TNM staging). Experiments on real-world data show UMA's strong performance and generalizability. Compared to supervised and heuristic baselines, UMA with GPT-4o achieves on average an absolute 2-point F1/accuracy improvement for both short-context and long-context attribute abstraction. For pathologic T staging, UMA even outperforms the supervised model by 20 points in accuracy.
MedImageInsight: An Open-Source Embedding Model for General Domain Medical Imaging
Oct 09, 2024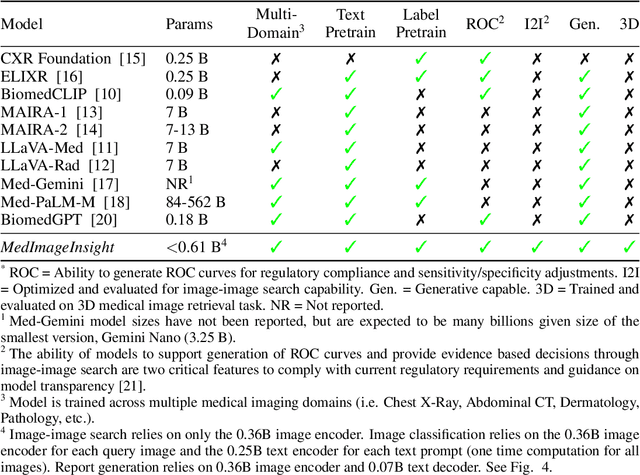
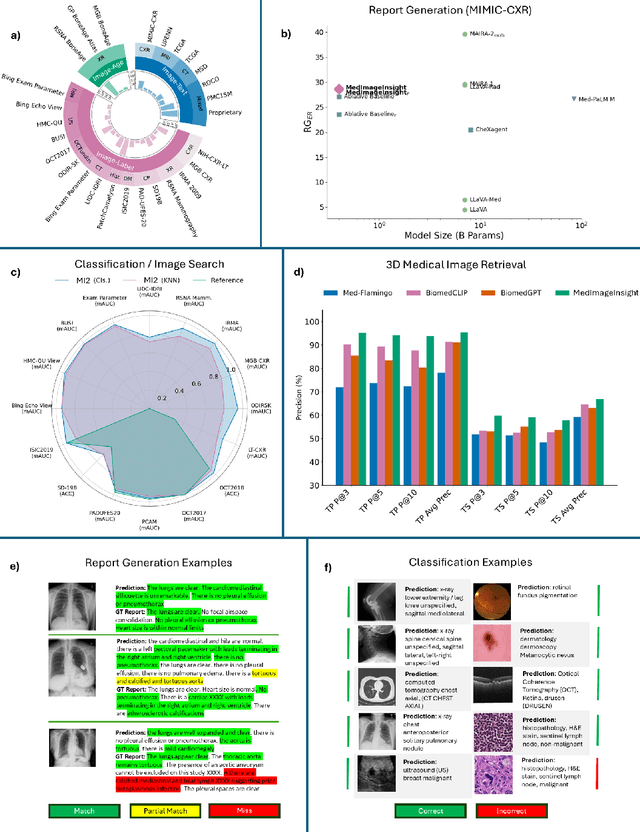
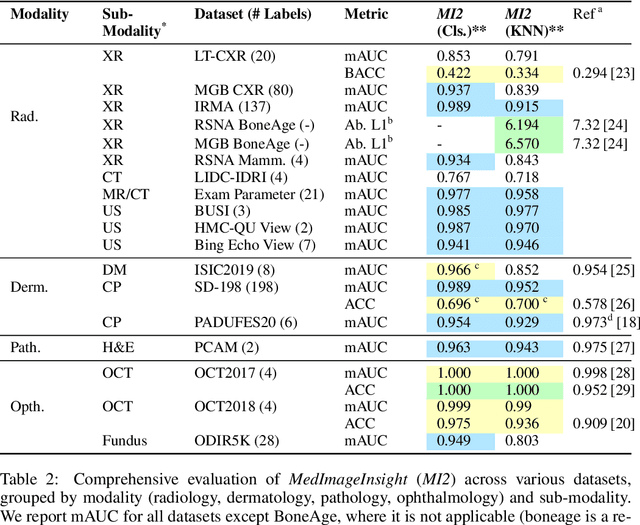
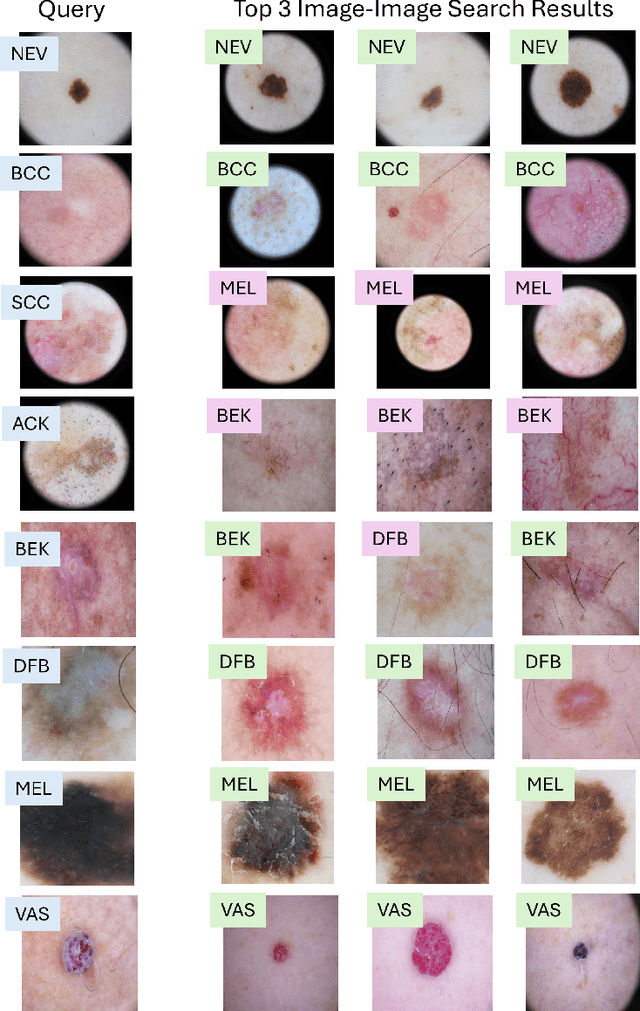
In this work, we present MedImageInsight, an open-source medical imaging embedding model. MedImageInsight is trained on medical images with associated text and labels across a diverse collection of domains, including X-Ray, CT, MRI, dermoscopy, OCT, fundus photography, ultrasound, histopathology, and mammography. Rigorous evaluations demonstrate MedImageInsight's ability to achieve state-of-the-art (SOTA) or human expert level performance across classification, image-image search, and fine-tuning tasks. Specifically, on public datasets, MedImageInsight achieves SOTA in CT 3D medical image retrieval, as well as SOTA in disease classification and search for chest X-ray, dermatology, and OCT imaging. Furthermore, MedImageInsight achieves human expert performance in bone age estimation (on both public and partner data), as well as AUC above 0.9 in most other domains. When paired with a text decoder, MedImageInsight achieves near SOTA level single image report findings generation with less than 10\% the parameters of other models. Compared to fine-tuning GPT-4o with only MIMIC-CXR data for the same task, MedImageInsight outperforms in clinical metrics, but underperforms on lexical metrics where GPT-4o sets a new SOTA. Importantly for regulatory purposes, MedImageInsight can generate ROC curves, adjust sensitivity and specificity based on clinical need, and provide evidence-based decision support through image-image search (which can also enable retrieval augmented generation). In an independent clinical evaluation of image-image search in chest X-ray, MedImageInsight outperformed every other publicly available foundation model evaluated by large margins (over 6 points AUC), and significantly outperformed other models in terms of AI fairness (across age and gender). We hope releasing MedImageInsight will help enhance collective progress in medical imaging AI research and development.
BiomedParse: a biomedical foundation model for image parsing of everything everywhere all at once
May 21, 2024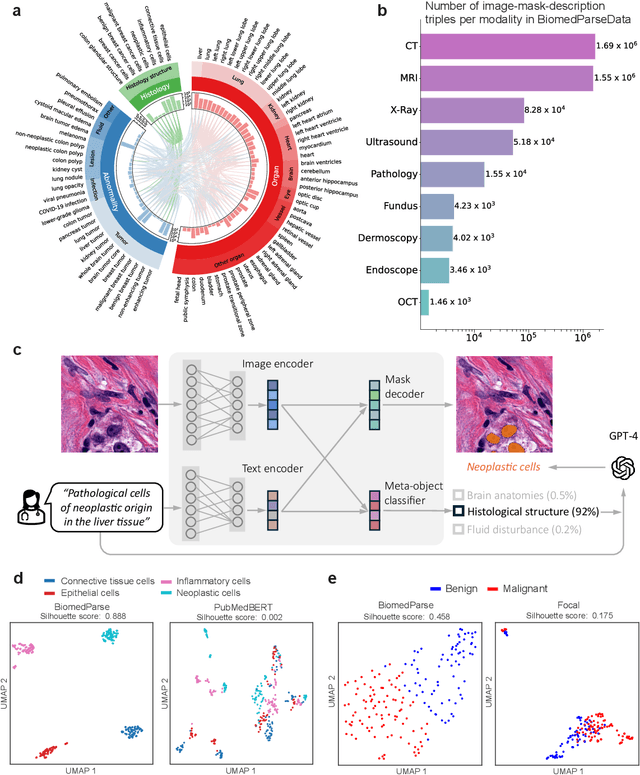
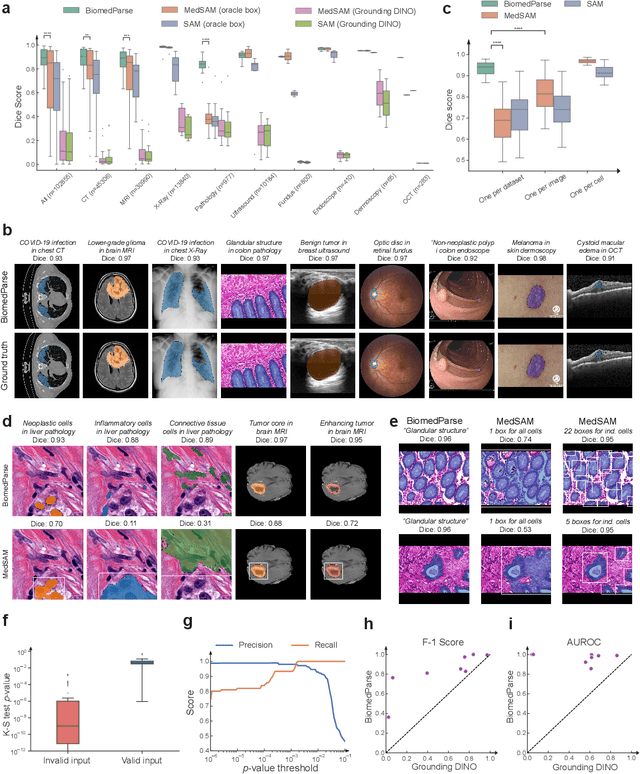
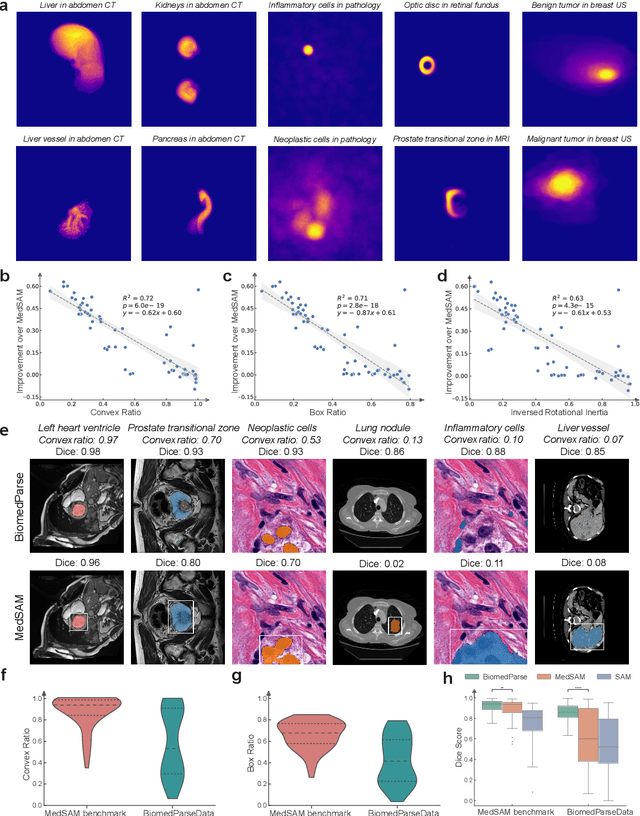
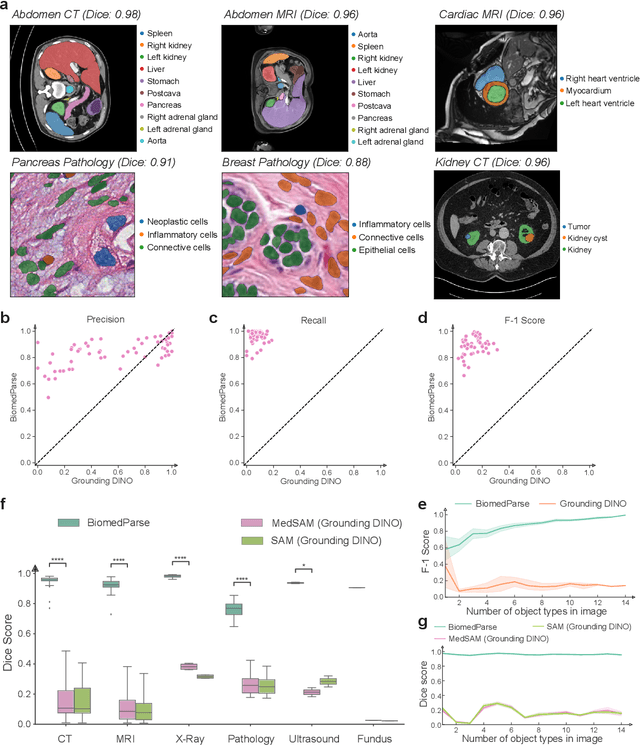
Biomedical image analysis is fundamental for biomedical discovery in cell biology, pathology, radiology, and many other biomedical domains. Holistic image analysis comprises interdependent subtasks such as segmentation, detection, and recognition of relevant objects. Here, we propose BiomedParse, a biomedical foundation model for imaging parsing that can jointly conduct segmentation, detection, and recognition for 82 object types across 9 imaging modalities. Through joint learning, we can improve accuracy for individual tasks and enable novel applications such as segmenting all relevant objects in an image through a text prompt, rather than requiring users to laboriously specify the bounding box for each object. We leveraged readily available natural-language labels or descriptions accompanying those datasets and use GPT-4 to harmonize the noisy, unstructured text information with established biomedical object ontologies. We created a large dataset comprising over six million triples of image, segmentation mask, and textual description. On image segmentation, we showed that BiomedParse is broadly applicable, outperforming state-of-the-art methods on 102,855 test image-mask-label triples across 9 imaging modalities (everything). On object detection, which aims to locate a specific object of interest, BiomedParse again attained state-of-the-art performance, especially on objects with irregular shapes (everywhere). On object recognition, which aims to identify all objects in a given image along with their semantic types, we showed that BiomedParse can simultaneously segment and label all biomedical objects in an image (all at once). In summary, BiomedParse is an all-in-one tool for biomedical image analysis by jointly solving segmentation, detection, and recognition for all major biomedical image modalities, paving the path for efficient and accurate image-based biomedical discovery.