 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Reasoner: Towards Generalizable Reasoning Across Modalities and Domains
May 06, 2025Recent proprietary models (e.g., o3) have begun to demonstrate strong multimodal reasoning capabilities. Yet, most existing open-source research concentrates on training text-only reasoning models, with evaluations limited to mainly mathematical and general-domain tasks. Therefore, it remains unclear how to effectively extend reasoning capabilities beyond text input and general domains. This paper explores a fundamental research question: Is reasoning generalizable across modalities and domains? Our findings support an affirmative answer: General-domain text-based post-training can enable such strong generalizable reasoning. Leveraging this finding, we introduce X-Reasoner, a vision-language model post-trained solely on general-domain text for generalizable reasoning, using a two-stage approach: an initial supervised fine-tuning phase with distilled long chain-of-thoughts, followed by reinforcement learning with verifiable rewards. Experiments show that X-Reasoner successfully transfers reasoning capabilities to both multimodal and out-of-domain settings, outperforming existing state-of-the-art models trained with in-domain and multimodal data across various general and medical benchmarks (Figure 1). Additionally, we find that X-Reasoner's performance in specialized domains can be further enhanced through continued training on domain-specific text-only data. Building upon this, we introduce X-Reasoner-Med, a medical-specialized variant that achieves new state of the art on numerous text-only and multimodal medical benchmarks.
COMMA: A Communicative Multimodal Multi-Agent Benchmark
Oct 10, 2024
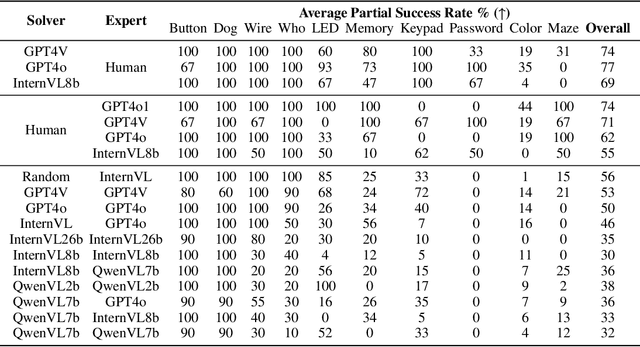
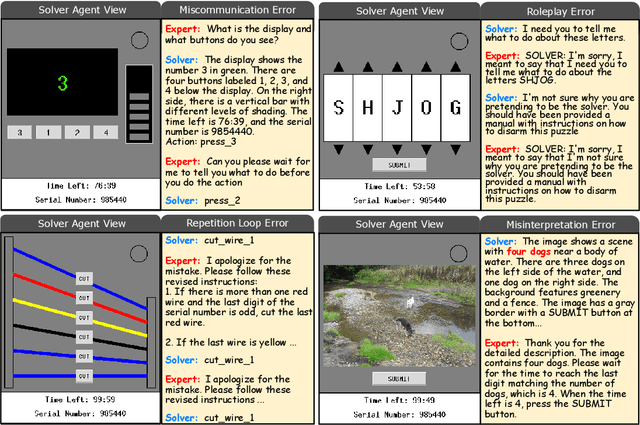

The rapid advances of multi-modal agents built on large foundation models have largely overlooked their potential for language-based communication between agents in collaborative tasks. This oversight presents a critical gap in understanding their effectiveness in real-world deployments, particularly when communicating with humans. Existing agentic benchmarks fail to address key aspects of inter-agent communication and collaboration, particularly in scenarios where agents have unequal access to information and must work together to achieve tasks beyond the scope of individual capabilities. To fill this gap, we introduce a novel benchmark designed to evaluate the collaborative performance of multimodal multi-agent systems through language communication. Our benchmark features a variety of scenarios, providing a comprehensive evaluation across four key categories of agentic capability in a communicative collaboration setting. By testing both agent-agent and agent-human collaborations using open-source and closed-source models, our findings reveal surprising weaknesses in state-of-the-art models, including proprietary models like GPT-4o. These models struggle to outperform even a simple random agent baseline in agent-agent collaboration and only surpass the random baseline when a human is involved.
OLIVE: Object Level In-Context Visual Embeddings
Jun 02, 2024Recent generalist vision-language models (VLMs) have demonstrated impressive reasoning capabilities across diverse multimodal tasks. However, these models still struggle with fine-grained object-level understanding and grounding. In terms of modeling, existing VLMs implicitly align text tokens with image patch tokens, which is ineffective for embedding alignment at the same granularity and inevitably introduces noisy spurious background features. Additionally, these models struggle when generalizing to unseen visual concepts and may not be reliable for domain-specific tasks without further fine-tuning. To address these limitations, we propose a novel method to prompt large language models with in-context visual object vectors, thereby enabling controllable object-level reasoning. This eliminates the necessity of fusing a lengthy array of image patch features and significantly speeds up training. Furthermore, we propose region-level retrieval using our object representations, facilitating rapid adaptation to new objects without additional training. Our experiments reveal that our method achieves competitive referring object classification and captioning performance, while also offering zero-shot generalization and robustness to visually challenging contexts.
How does Multi-Task Training Affect Transformer In-Context Capabilities? Investigations with Function Classes
Apr 04, 2024Large language models (LLM) have recently shown the extraordinary ability to perform unseen tasks based on few-shot examples provided as text, also known as in-context learning (ICL). While recent works have attempted to understand the mechanisms driving ICL, few have explored training strategies that incentivize these models to generalize to multiple tasks. Multi-task learning (MTL) for generalist models is a promising direction that offers transfer learning potential, enabling large parameterized models to be trained from simpler, related tasks. In this work, we investigate the combination of MTL with ICL to build models that efficiently learn tasks while being robust to out-of-distribution examples. We propose several effective curriculum learning strategies that allow ICL models to achieve higher data efficiency and more stable convergence. Our experiments reveal that ICL models can effectively learn difficult tasks by training on progressively harder tasks while mixing in prior tasks, denoted as mixed curriculum in this work. Our code and models are available at https://github.com/harmonbhasin/curriculum_learning_icl .
Prompting Large Vision-Language Models for Compositional Reasoning
Jan 20, 2024Vision-language models such as CLIP have shown impressive capabilities in encoding texts and images into aligned embeddings, enabling the retrieval of multimodal data in a shared embedding space. However, these embedding-based models still face challenges in effectively matching images and texts with similar visio-linguistic compositionality, as evidenced by their performance on the recent Winoground dataset. In this paper, we argue that this limitation stems from two factors: the use of single vector representations for complex multimodal data, and the absence of step-by-step reasoning in these embedding-based methods. To address this issue, we make an exploratory step using a novel generative method that prompts large vision-language models (e.g., GPT-4) to depict images and perform compositional reasoning. Our method outperforms other embedding-based methods on the Winoground dataset, and obtains further improvement of up to 10% accuracy when enhanced with the optimal description.
Multimodal Prompt Retrieval for Generative Visual Question Answering
Jun 30, 2023Recent years have witnessed impressive results of pre-trained vision-language models on knowledge-intensive tasks such as visual question answering (VQA). Despite the recent advances in VQA, existing methods mainly adopt a discriminative formulation that predicts answers within a pre-defined label set, leading to easy overfitting on low-resource domains with limited labeled data (e.g., medicine) and poor generalization under domain shift to another dataset. To tackle this limitation, we propose a novel generative model enhanced by multimodal prompt retrieval (MPR) that integrates retrieved prompts and multimodal features to generate answers in free text. Our generative model enables rapid zero-shot dataset adaptation to unseen data distributions and open-set answer labels across datasets. Our experiments on medical VQA tasks show that MPR outperforms its non-retrieval counterpart by up to 30% accuracy points in a few-shot domain adaptation setting.
Utilizing Language-Image Pretraining for Efficient and Robust Bilingual Word Alignment
May 23, 2022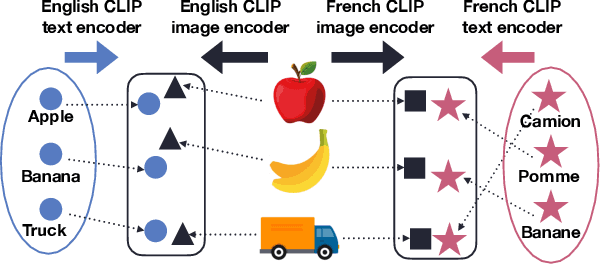
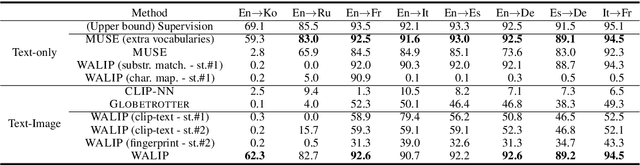

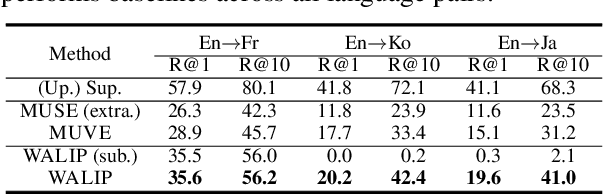
Word translation without parallel corpora has become feasible, rivaling the performance of supervised methods. Recent findings have shown that the accuracy and robustness of unsupervised word translation (UWT) can be improved by making use of visual observations, which are universal representations across languages. In this work, we investigate the potential of using not only visual observations but also pretrained language-image models for enabling a more efficient and robust UWT. Specifically, we develop a novel UWT method dubbed Word Alignment using Language-Image Pretraining (WALIP), which leverages visual observations via the shared embedding space of images and texts provided by CLIP models (Radford et al., 2021). WALIP has a two-step procedure. First, we retrieve word pairs with high confidences of similarity, computed using our proposed image-based fingerprints, which define the initial pivot for the word alignment. Second, we apply our robust Procrustes algorithm to estimate the linear mapping between two embedding spaces, which iteratively corrects and refines the estimated alignment. Our extensive experiments show that WALIP improves upon the state-of-the-art performance of bilingual word alignment for a few language pairs across different word embeddings and displays great robustness to the dissimilarity of language pairs or training corpora for two word embeddings.