 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeClinic: Evaluating Automation of Coding Skills for Clinical Reasoning Agents
May 10, 2026Clinical reasoning agents based on large language models (LLMs) aim to automate tasks such as intensive care unit (ICU) monitoring and patient state tracking from electronic health records (EHRs). Existing systems typically rely on manually curated clinical tools or skills for concepts such as sepsis detection and organ failure assessment. However, maintaining these tool libraries requires substantial expert effort, while zero-shot querying or code generation often produces inefficient and unreliable reasoning chains, especially under institution-specific clinical policies. We introduce CodeClinic, a benchmark built on MIMIC-IV for evaluating whether LLM agents can synthesize and compose reusable clinical skills instead of relying on fixed toolboxes. The benchmark contains two complementary tasks: longitudinal ICU surveillance and compositional information seeking. The longitudinal setting simulates monitoring patient trajectories with structured decisions every four hours across 25 findings and eight clinical families, while the compositional setting spans 63k instances across 259 tasks in nine domains and is stratified by compositional dependency depth to evaluate increasingly complex multi-step reasoning. We further propose an offline autoformalization pipeline that converts natural-language clinical guidelines into reusable and verified Python skill libraries through iterative LLM refinement. Compared with zero-shot code generation, the resulting libraries improve consistency while reducing per-query token usage by up to 40%.
From Embeddings to Accuracy: Comparing Foundation Models for Radiographic Classification
May 16, 2025Foundation models, pretrained on extensive datasets, have significantly advanced machine learning by providing robust and transferable embeddings applicable to various domains, including medical imaging diagnostics. This study evaluates the utility of embeddings derived from both general-purpose and medical domain-specific foundation models for training lightweight adapter models in multi-class radiography classification, focusing specifically on tube placement assessment. A dataset comprising 8842 radiographs classified into seven distinct categories was employed to extract embeddings using six foundation models: DenseNet121, BiomedCLIP, Med-Flamingo, MedImageInsight, Rad-DINO, and CXR-Foundation. Adapter models were subsequently trained using classical machine learning algorithms. Among these combinations, MedImageInsight embeddings paired with an support vector machine adapter yielded the highest mean area under the curve (mAUC) at 93.8%, followed closely by Rad-DINO (91.1%) and CXR-Foundation (89.0%). In comparison, BiomedCLIP and DenseNet121 exhibited moderate performance with mAUC scores of 83.0% and 81.8%, respectively, whereas Med-Flamingo delivered the lowest performance at 75.1%. Notably, most adapter models demonstrated computational efficiency, achieving training within one minute and inference within seconds on CPU, underscoring their practicality for clinical applications. Furthermore, fairness analyses on adapters trained on MedImageInsight-derived embeddings indicated minimal disparities, with gender differences in performance within 2% and standard deviations across age groups not exceeding 3%. These findings confirm that foundation model embeddings-especially those from MedImageInsight-facilitate accurate, computationally efficient, and equitable diagnostic classification using lightweight adapters for radiographic image analysis.
COMMA: A Communicative Multimodal Multi-Agent Benchmark
Oct 10, 2024
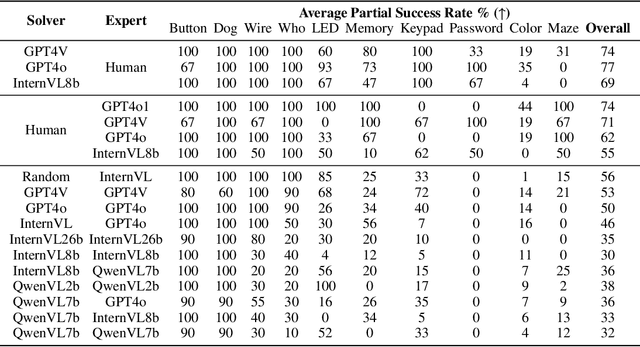
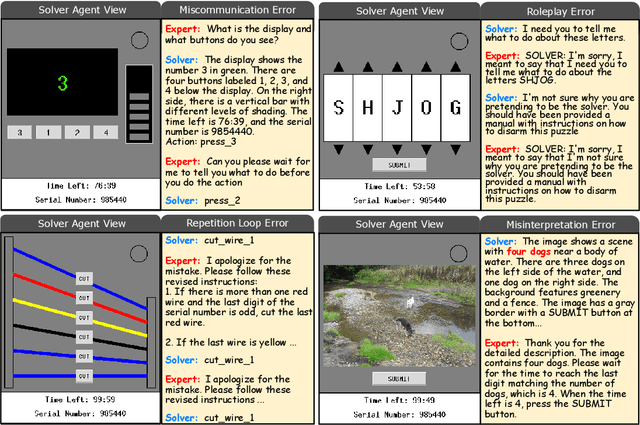

The rapid advances of multi-modal agents built on large foundation models have largely overlooked their potential for language-based communication between agents in collaborative tasks. This oversight presents a critical gap in understanding their effectiveness in real-world deployments, particularly when communicating with humans. Existing agentic benchmarks fail to address key aspects of inter-agent communication and collaboration, particularly in scenarios where agents have unequal access to information and must work together to achieve tasks beyond the scope of individual capabilities. To fill this gap, we introduce a novel benchmark designed to evaluate the collaborative performance of multimodal multi-agent systems through language communication. Our benchmark features a variety of scenarios, providing a comprehensive evaluation across four key categories of agentic capability in a communicative collaboration setting. By testing both agent-agent and agent-human collaborations using open-source and closed-source models, our findings reveal surprising weaknesses in state-of-the-art models, including proprietary models like GPT-4o. These models struggle to outperform even a simple random agent baseline in agent-agent collaboration and only surpass the random baseline when a human is involved.
Knowledge-grounded Adaptation Strategy for Vision-language Models: Building Unique Case-set for Screening Mammograms for Residents Training
May 30, 2024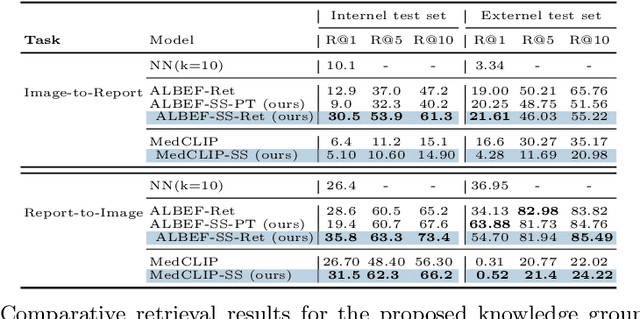
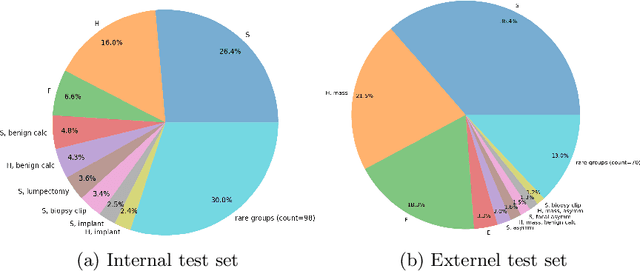
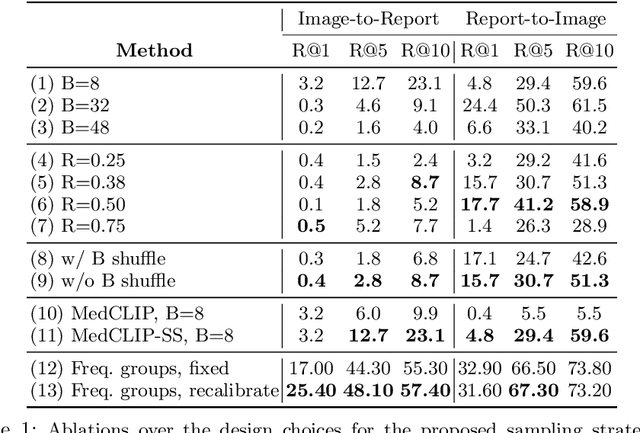
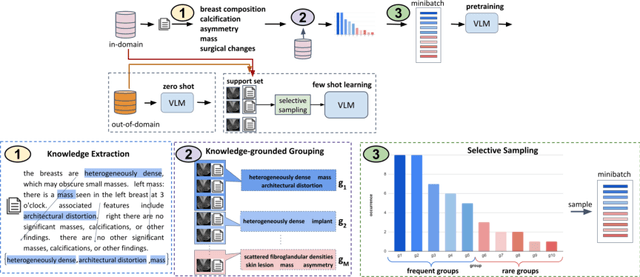
A visual-language model (VLM) pre-trained on natural images and text pairs poses a significant barrier when applied to medical contexts due to domain shift. Yet, adapting or fine-tuning these VLMs for medical use presents considerable hurdles, including domain misalignment, limited access to extensive datasets, and high-class imbalances. Hence, there is a pressing need for strategies to effectively adapt these VLMs to the medical domain, as such adaptations would prove immensely valuable in healthcare applications. In this study, we propose a framework designed to adeptly tailor VLMs to the medical domain, employing selective sampling and hard-negative mining techniques for enhanced performance in retrieval tasks. We validate the efficacy of our proposed approach by implementing it across two distinct VLMs: the in-domain VLM (MedCLIP) and out-of-domain VLMs (ALBEF). We assess the performance of these models both in their original off-the-shelf state and after undergoing our proposed training strategies, using two extensive datasets containing mammograms and their corresponding reports. Our evaluation spans zero-shot, few-shot, and supervised scenarios. Through our approach, we observe a notable enhancement in Recall@K performance for the image-text retrieval task.
ConTEXTual Net: A Multimodal Vision-Language Model for Segmentation of Pneumothorax
Mar 02, 2023



Clinical imaging databases contain not only medical images but also text reports generated by physicians. These narrative reports often describe the location, size, and shape of the disease, but using descriptive text to guide medical image analysis has been understudied. Vision-language models are increasingly used for multimodal tasks like image generation, image captioning, and visual question answering but have been scarcely used in medical imaging. In this work, we develop a vision-language model for the task of pneumothorax segmentation. Our model, ConTEXTual Net, detects and segments pneumothorax in chest radiographs guided by free-form radiology reports. ConTEXTual Net achieved a Dice score of 0.72 $\pm$ 0.02, which was similar to the level of agreement between the primary physician annotator and the other physician annotators (0.71 $\pm$ 0.04). ConTEXTual Net also outperformed a U-Net. We demonstrate that descriptive language can be incorporated into a segmentation model for improved performance. Through an ablative study, we show that it is the text information that is responsible for the performance gains. Additionally, we show that certain augmentation methods worsen ConTEXTual Net's segmentation performance by breaking the image-text concordance. We propose a set of augmentations that maintain this concordance and improve segmentation training.
Domain-adapted large language models for classifying nuclear medicine reports
Mar 01, 2023



With the growing use of transformer-based language models in medicine, it is unclear how well these models generalize to nuclear medicine which has domain-specific vocabulary and unique reporting styles. In this study, we evaluated the value of domain adaptation in nuclear medicine by adapting language models for the purpose of 5-point Deauville score prediction based on clinical 18F-fluorodeoxyglucose (FDG) PET/CT reports. We retrospectively retrieved 4542 text reports and 1664 images for FDG PET/CT lymphoma exams from 2008-2018 in our clinical imaging database. Deauville scores were removed from the reports and then the remaining text in the reports was used as the model input. Multiple general-purpose transformer language models were used to classify the reports into Deauville scores 1-5. We then adapted the models to the nuclear medicine domain using masked language modeling and assessed its impact on classification performance. The language models were compared against vision models, a multimodal vision language model, and a nuclear medicine physician with seven-fold Monte Carlo cross validation, reported are the mean and standard deviations. Domain adaption improved all language models. For example, BERT improved from 61.3% five-class accuracy to 65.7% following domain adaptation. The best performing model (domain-adapted RoBERTa) achieved a five-class accuracy of 77.4%, which was better than the physician's performance (66%), the best vision model's performance (48.1), and was similar to the multimodal model's performance (77.2). Domain adaptation improved the performance of large language models in interpreting nuclear medicine text reports.