 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-grounded Adaptation Strategy for Vision-language Models: Building Unique Case-set for Screening Mammograms for Residents Training
May 30, 2024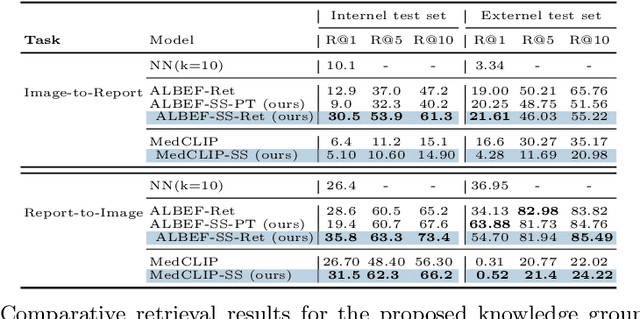
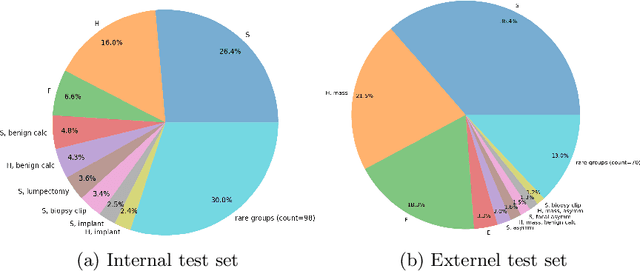
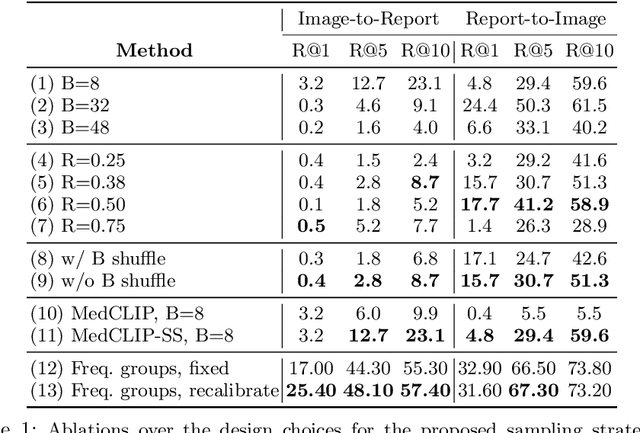
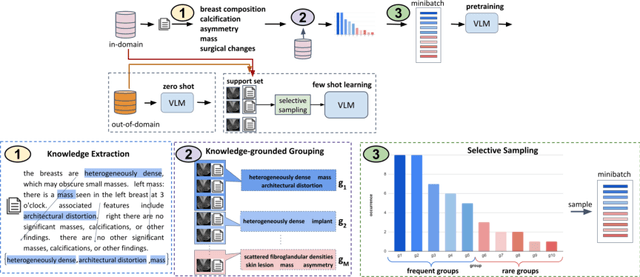
A visual-language model (VLM) pre-trained on natural images and text pairs poses a significant barrier when applied to medical contexts due to domain shift. Yet, adapting or fine-tuning these VLMs for medical use presents considerable hurdles, including domain misalignment, limited access to extensive datasets, and high-class imbalances. Hence, there is a pressing need for strategies to effectively adapt these VLMs to the medical domain, as such adaptations would prove immensely valuable in healthcare applications. In this study, we propose a framework designed to adeptly tailor VLMs to the medical domain, employing selective sampling and hard-negative mining techniques for enhanced performance in retrieval tasks. We validate the efficacy of our proposed approach by implementing it across two distinct VLMs: the in-domain VLM (MedCLIP) and out-of-domain VLMs (ALBEF). We assess the performance of these models both in their original off-the-shelf state and after undergoing our proposed training strategies, using two extensive datasets containing mammograms and their corresponding reports. Our evaluation spans zero-shot, few-shot, and supervised scenarios. Through our approach, we observe a notable enhancement in Recall@K performance for the image-text retrieval task.
Learning Situation Hyper-Graphs for Video Question Answering
Apr 18, 2023



Answering questions about complex situations in videos requires not only capturing the presence of actors, objects, and their relations but also the evolution of these relationships over time. A situation hyper-graph is a representation that describes situations as scene sub-graphs for video frames and hyper-edges for connected sub-graphs and has been proposed to capture all such information in a compact structured form. In this work, we propose an architecture for Video Question Answering (VQA) that enables answering questions related to video content by predicting situation hyper-graphs, coined Situation Hyper-Graph based Video Question Answering (SHG-VQA). To this end, we train a situation hyper-graph decoder to implicitly identify graph representations with actions and object/human-object relationships from the input video clip. and to use cross-attention between the predicted situation hyper-graphs and the question embedding to predict the correct answer. The proposed method is trained in an end-to-end manner and optimized by a VQA loss with the cross-entropy function and a Hungarian matching loss for the situation graph prediction. The effectiveness of the proposed architecture is extensively evaluated on two challenging benchmarks: AGQA and STAR. Our results show that learning the underlying situation hyper-graphs helps the system to significantly improve its performance for novel challenges of video question-answering tasks.
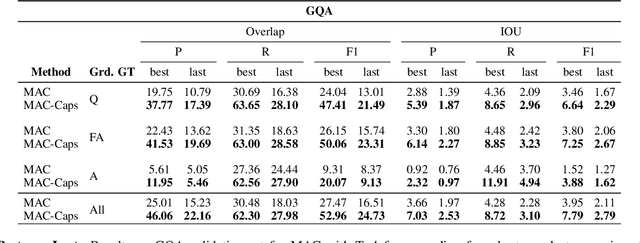
Weakly Supervised Grounding for VQA in Vision-Language Transformers
Jul 05, 2022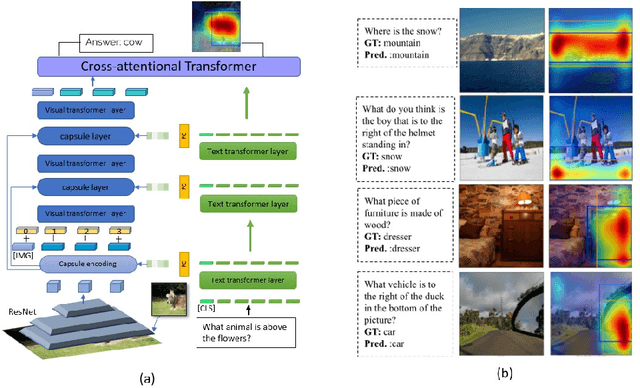
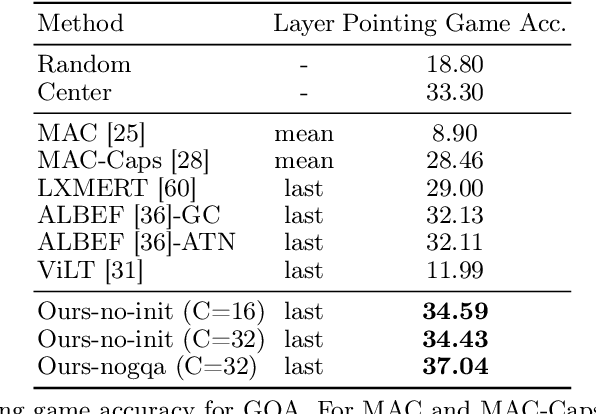
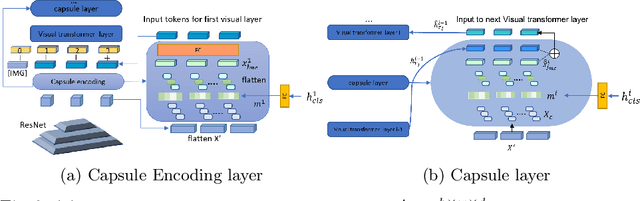
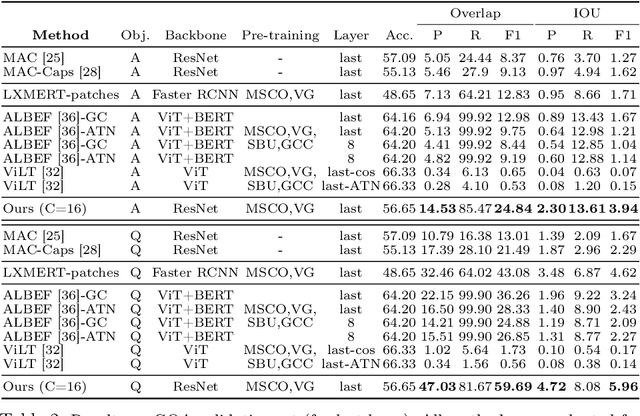
Transformers for visual-language representation learning have been getting a lot of interest and shown tremendous performance on visual question answering (VQA) and grounding. But most systems that show good performance of those tasks still rely on pre-trained object detectors during training, which limits their applicability to the object classes available for those detectors. To mitigate this limitation, the following paper focuses on the problem of weakly supervised grounding in context of visual question answering in transformers. The approach leverages capsules by grouping each visual token in the visual encoder and uses activations from language self-attention layers as a text-guided selection module to mask those capsules before they are forwarded to the next layer. We evaluate our approach on the challenging GQA as well as VQA-HAT dataset for VQA grounding. Our experiments show that: while removing the information of masked objects from standard transformer architectures leads to a significant drop in performance, the integration of capsules significantly improves the grounding ability of such systems and provides new state-of-the-art results compared to other approaches in the field.
Found a Reason for me? Weakly-supervised Grounded Visual Question Answering using Capsules
May 11, 2021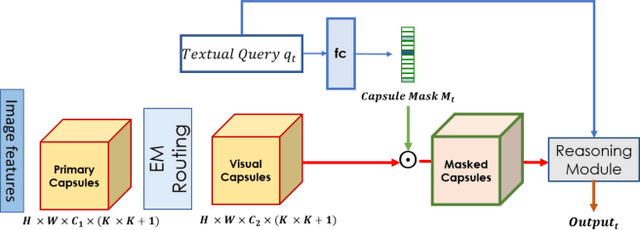
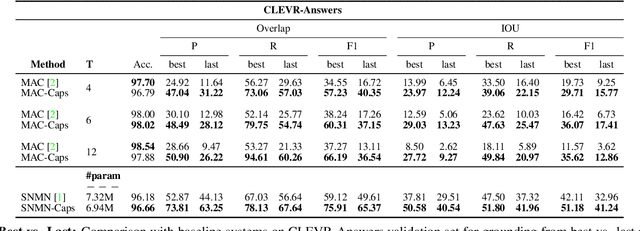

The problem of grounding VQA tasks has seen an increased attention in the research community recently, with most attempts usually focusing on solving this task by using pretrained object detectors. However, pre-trained object detectors require bounding box annotations for detecting relevant objects in the vocabulary, which may not always be feasible for real-life large-scale applications. In this paper, we focus on a more relaxed setting: the grounding of relevant visual entities in a weakly supervised manner by training on the VQA task alone. To address this problem, we propose a visual capsule module with a query-based selection mechanism of capsule features, that allows the model to focus on relevant regions based on the textual cues about visual information in the question. We show that integrating the proposed capsule module in existing VQA systems significantly improves their performance on the weakly supervised grounding task. Overall, we demonstrate the effectiveness of our approach on two state-of-the-art VQA systems, stacked NMN and MAC, on the CLEVR-Answers benchmark, our new evaluation set based on CLEVR scenes with ground truth bounding boxes for objects that are relevant for the correct answer, as well as on GQA, a real world VQA dataset with compositional questions. We show that the systems with the proposed capsule module consistently outperform the respective baseline systems in terms of answer grounding, while achieving comparable performance on VQA task.
MMFT-BERT: Multimodal Fusion Transformer with BERT Encodings for Visual Question Answering
Oct 27, 2020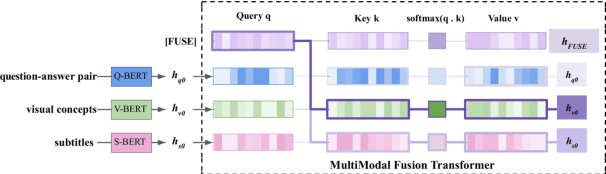
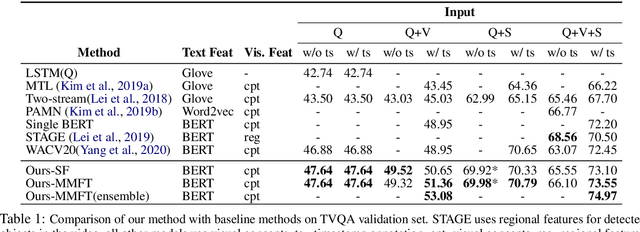
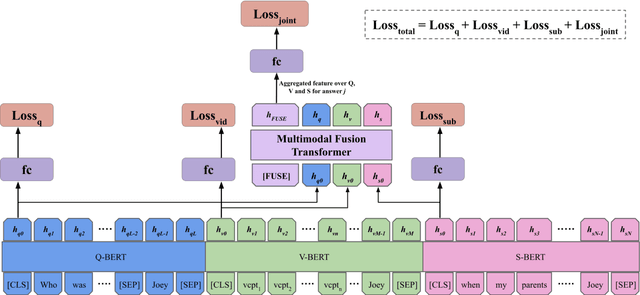
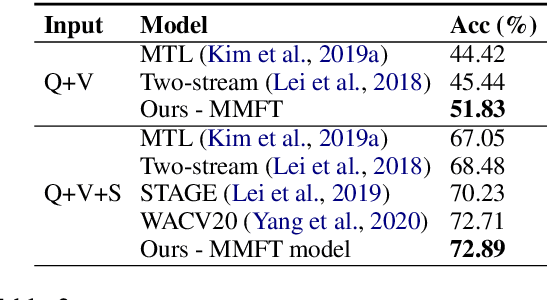
We present MMFT-BERT(MultiModal Fusion Transformer with BERT encodings), to solve Visual Question Answering (VQA) ensuring individual and combined processing of multiple input modalities. Our approach benefits from processing multimodal data (video and text) adopting the BERT encodings individually and using a novel transformer-based fusion method to fuse them together. Our method decomposes the different sources of modalities, into different BERT instances with similar architectures, but variable weights. This achieves SOTA results on the TVQA dataset. Additionally, we provide TVQA-Visual, an isolated diagnostic subset of TVQA, which strictly requires the knowledge of visual (V) modality based on a human annotator's judgment. This set of questions helps us to study the model's behavior and the challenges TVQA poses to prevent the achievement of super human performance. Extensive experiments show the effectiveness and superiority of our method.
Analysis of Hand Segmentation in the Wild
Mar 28, 2018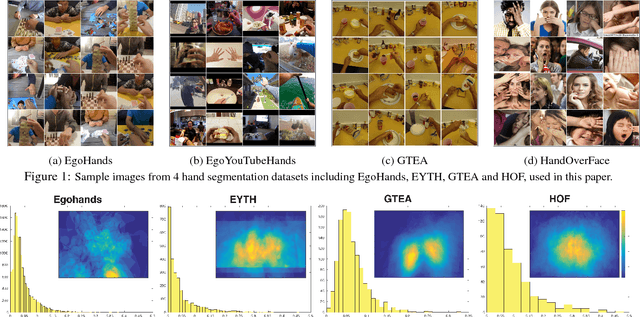
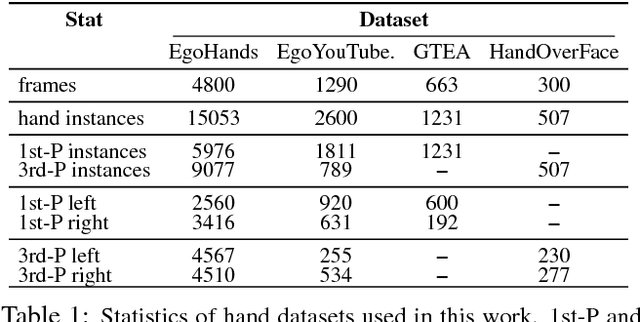

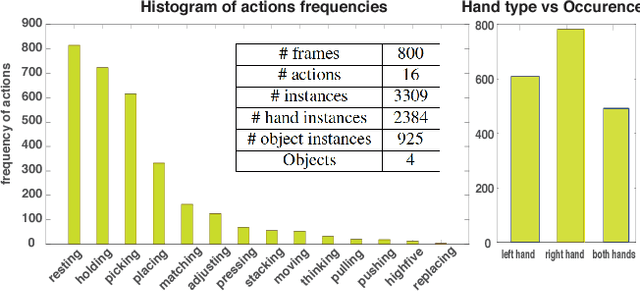
A large number of works in egocentric vision have concentrated on action and object recognition. Detection and segmentation of hands in first-person videos, however, has less been explored. For many applications in this domain, it is necessary to accurately segment not only hands of the camera wearer but also the hands of others with whom he is interacting. Here, we take an in-depth look at the hand segmentation problem. In the quest for robust hand segmentation methods, we evaluated the performance of the state of the art semantic segmentation methods, off the shelf and fine-tuned, on existing datasets. We fine-tune RefineNet, a leading semantic segmentation method, for hand segmentation and find that it does much better than the best contenders. Existing hand segmentation datasets are collected in the laboratory settings. To overcome this limitation, we contribute by collecting two new datasets: a) EgoYouTubeHands including egocentric videos containing hands in the wild, and b) HandOverFace to analyze the performance of our models in presence of similar appearance occlusions. We further explore whether conditional random fields can help refine generated hand segmentations. To demonstrate the benefit of accurate hand maps, we train a CNN for hand-based activity recognition and achieve higher accuracy when a CNN was trained using hand maps produced by the fine-tuned RefineNet. Finally, we annotate a subset of the EgoHands dataset for fine-grained action recognition and show that an accuracy of 58.6% can be achieved by just looking at a single hand pose which is much better than the chance level (12.5%).
Segmenting Sky Pixels in Images
Jan 08, 2018
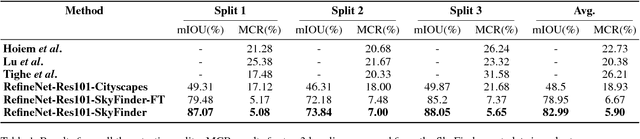


Outdoor scene parsing models are often trained on ideal datasets and produce quality results. However, this leads to a discrepancy when applied to the real world. The quality of scene parsing, particularly sky classification, decreases in night time images, images involving varying weather conditions, and scene changes due to seasonal weather. This project focuses on approaching these challenges by using a state-of-the-art model in conjunction with a non-ideal dataset: SkyFinder and a subset from SUN database with Sky object. We focus specifically on sky segmentation, the task of determining sky and not-sky pixels, and improving upon an existing state-of-the-art model: RefineNet. As a result of our efforts, we have seen an improvement of 10-15% in the average MCR compared to the prior methods on SkyFinder dataset. We have also improved from an off-the shelf-model in terms of average mIOU by nearly 35%. Further, we analyze our trained models on images w.r.t two aspects: times of day and weather, and find that, in spite of facing same challenges as prior methods, our trained models significantly outperform them.
Egocentric Height Estimation
Oct 09, 2016
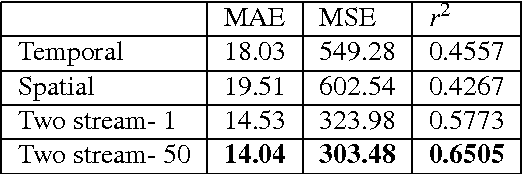
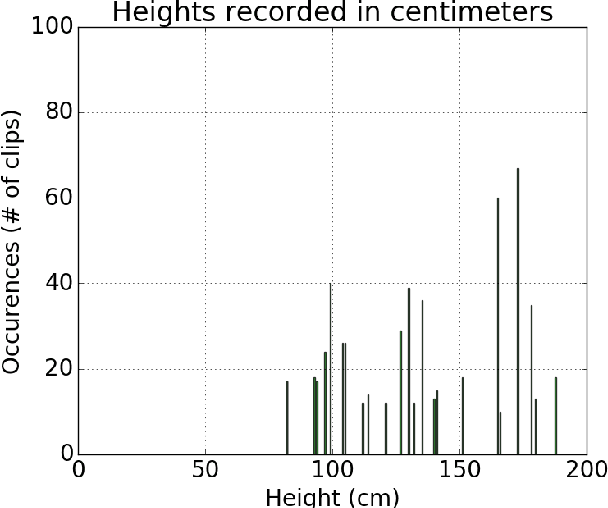
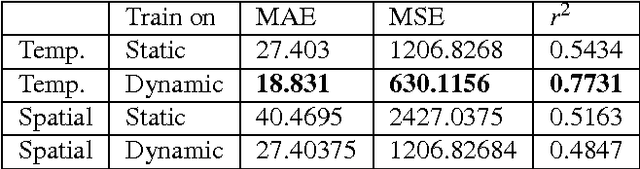
Egocentric, or first-person vision which became popular in recent years with an emerge in wearable technology, is different than exocentric (third-person) vision in some distinguishable ways, one of which being that the camera wearer is generally not visible in the video frames. Recent work has been done on action and object recognition in egocentric videos, as well as work on biometric extraction from first-person videos. Height estimation can be a useful feature for both soft-biometrics and object tracking. Here, we propose a method of estimating the height of an egocentric camera without any calibration or reference points. We used both traditional computer vision approaches and deep learning in order to determine the visual cues that results in best height estimation. Here, we introduce a framework inspired by two stream networks comprising of two Convolutional Neural Networks, one based on spatial information, and one based on information given by optical flow in a frame. Given an egocentric video as an input to the framework, our model yields a height estimate as an output. We also incorporate late fusion to learn a combination of temporal and spatial cues. Comparing our model with other methods we used as baselines, we achieve height estimates for videos with a Mean Average Error of 14.04 cm over a range of 103 cm of data, and classification accuracy for relative height (tall, medium or short) up to 93.75% where chance level is 33%.