 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDLNet: Statistical Deep Learning Network for Co-Occurring Object Detection and Identification
Jul 24, 2024With the growing advances in deep learning based technologies the detection and identification of co-occurring objects is a challenging task which has many applications in areas such as, security and surveillance. In this paper, we propose a novel framework called SDLNet- Statistical analysis with Deep Learning Network that identifies co-occurring objects in conjunction with base objects in multilabel object categories. The pipeline of proposed work is implemented in two stages: in the first stage of SDLNet we deal with multilabel detectors for discovering labels, and in the second stage we perform co-occurrence matrix analysis. In co-occurrence matrix analysis, we learn co-occurrence statistics by setting base classes and frequently occurring classes, following this we build association rules and generate frequent patterns. The crucial part of SDLNet is recognizing base classes and making consideration for co-occurring classes. Finally, the generated co-occurrence matrix based on frequent patterns will show base classes and their corresponding co-occurring classes. SDLNet is evaluated on two publicly available datasets: Pascal VOC and MS-COCO. The experimental results on these benchmark datasets are reported in Sec 4.
* 8 pages, 3 figures, ICMLT-2024. arXiv admin note: text overlap with arXiv:2403.17223
Co-Occurring of Object Detection and Identification towards unlabeled object discovery
Mar 25, 2024In this paper, we propose a novel deep learning based approach for identifying co-occurring objects in conjunction with base objects in multilabel object categories. Nowadays, with the advancement in computer vision based techniques we need to know about co-occurring objects with respect to base object for various purposes. The pipeline of the proposed work is composed of two stages: in the first stage of the proposed model we detect all the bounding boxes present in the image and their corresponding labels, then in the second stage we perform co-occurrence matrix analysis. In co-occurrence matrix analysis, we set base classes based on the maximum occurrences of the labels and build association rules and generate frequent patterns. These frequent patterns will show base classes and their corresponding co-occurring classes. We performed our experiments on two publicly available datasets: Pascal VOC and MS-COCO. The experimental results on public benchmark dataset is reported in Sec 4. Further we extend this work by considering all frequently objects as unlabeled and what if they are occluded as well.
Weakly Supervised Grounding for VQA in Vision-Language Transformers
Jul 05, 2022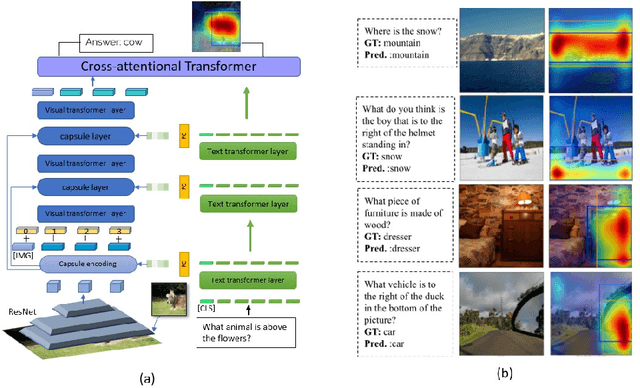
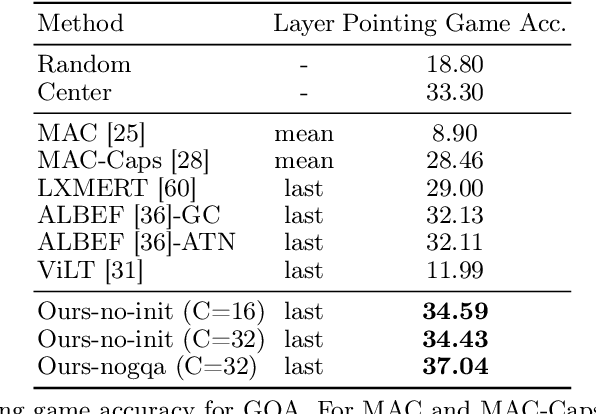
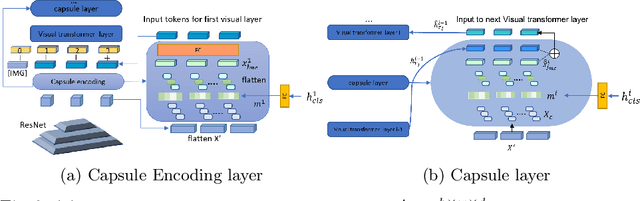
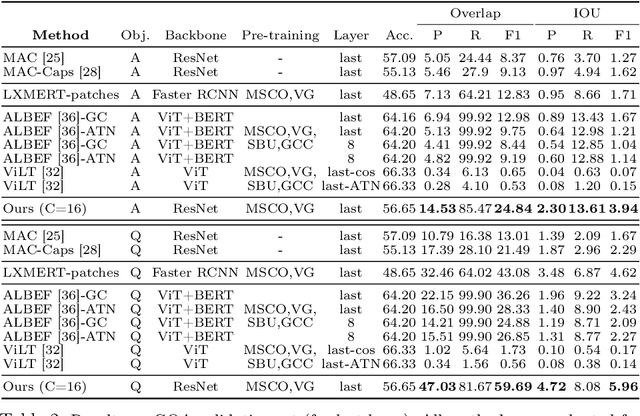
Transformers for visual-language representation learning have been getting a lot of interest and shown tremendous performance on visual question answering (VQA) and grounding. But most systems that show good performance of those tasks still rely on pre-trained object detectors during training, which limits their applicability to the object classes available for those detectors. To mitigate this limitation, the following paper focuses on the problem of weakly supervised grounding in context of visual question answering in transformers. The approach leverages capsules by grouping each visual token in the visual encoder and uses activations from language self-attention layers as a text-guided selection module to mask those capsules before they are forwarded to the next layer. We evaluate our approach on the challenging GQA as well as VQA-HAT dataset for VQA grounding. Our experiments show that: while removing the information of masked objects from standard transformer architectures leads to a significant drop in performance, the integration of capsules significantly improves the grounding ability of such systems and provides new state-of-the-art results compared to other approaches in the field.