 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Generation to Collaboration: Using LLMs to Edit for Empathy in Healthcare
Jan 22, 2026Clinical empathy is essential for patient care, but physicians need continually balance emotional warmth with factual precision under the cognitive and emotional constraints of clinical practice. This study investigates how large language models (LLMs) can function as empathy editors, refining physicians' written responses to enhance empathetic tone while preserving underlying medical information. More importantly, we introduce novel quantitative metrics, an Empathy Ranking Score and a MedFactChecking Score to systematically assess both emotional and factual quality of the responses. Experimental results show that LLM edited responses significantly increase perceived empathy while preserving factual accuracy compared with fully LLM generated outputs. These findings suggest that using LLMs as editorial assistants, rather than autonomous generators, offers a safer, more effective pathway to empathetic and trustworthy AI-assisted healthcare communication.
Position: Restructuring of Categories and Implementation of Guidelines Essential for VLM Adoption in Healthcare
May 12, 2025The intricate and multifaceted nature of vision language model (VLM) development, adaptation, and application necessitates the establishment of clear and standardized reporting protocols, particularly within the high-stakes context of healthcare. Defining these reporting standards is inherently challenging due to the diverse nature of studies involving VLMs, which vary significantly from the development of all new VLMs or finetuning for domain alignment to off-the-shelf use of VLM for targeted diagnosis and prediction tasks. In this position paper, we argue that traditional machine learning reporting standards and evaluation guidelines must be restructured to accommodate multiphase VLM studies; it also has to be organized for intuitive understanding of developers while maintaining rigorous standards for reproducibility. To facilitate community adoption, we propose a categorization framework for VLM studies and outline corresponding reporting standards that comprehensively address performance evaluation, data reporting protocols, and recommendations for manuscript composition. These guidelines are organized according to the proposed categorization scheme. Lastly, we present a checklist that consolidates reporting standards, offering a standardized tool to ensure consistency and quality in the publication of VLM-related research.
Opportunistic Screening for Pancreatic Cancer using Computed Tomography Imaging and Radiology Reports
Mar 31, 2025Pancreatic ductal adenocarcinoma (PDAC) is a highly aggressive cancer, with most cases diagnosed at stage IV and a five-year overall survival rate below 5%. Early detection and prognosis modeling are crucial for improving patient outcomes and guiding early intervention strategies. In this study, we developed and evaluated a deep learning fusion model that integrates radiology reports and CT imaging to predict PDAC risk. The model achieved a concordance index (C-index) of 0.6750 (95% CI: 0.6429, 0.7121) and 0.6435 (95% CI: 0.6055, 0.6789) on the internal and external dataset, respectively, for 5-year survival risk estimation. Kaplan-Meier analysis demonstrated significant separation (p<0.0001) between the low and high risk groups predicted by the fusion model. These findings highlight the potential of deep learning-based survival models in leveraging clinical and imaging data for pancreatic cancer.
Knowledge-grounded Adaptation Strategy for Vision-language Models: Building Unique Case-set for Screening Mammograms for Residents Training
May 30, 2024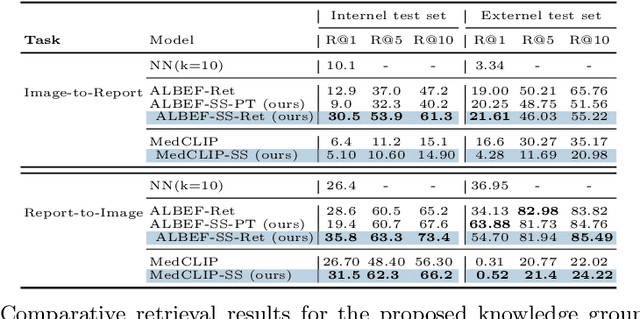
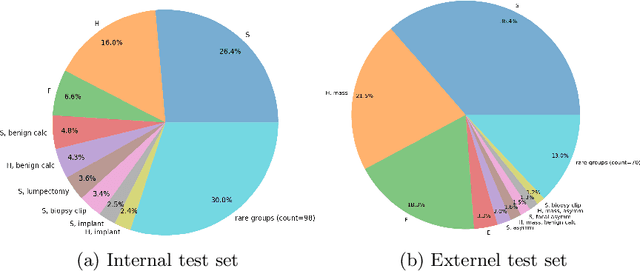
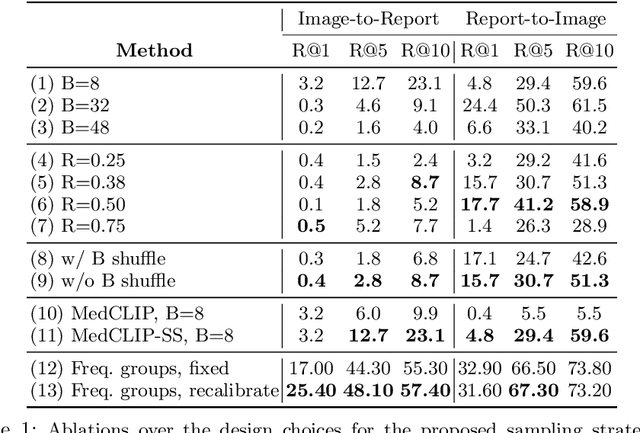
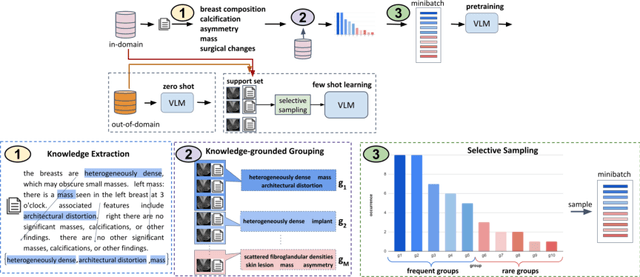
A visual-language model (VLM) pre-trained on natural images and text pairs poses a significant barrier when applied to medical contexts due to domain shift. Yet, adapting or fine-tuning these VLMs for medical use presents considerable hurdles, including domain misalignment, limited access to extensive datasets, and high-class imbalances. Hence, there is a pressing need for strategies to effectively adapt these VLMs to the medical domain, as such adaptations would prove immensely valuable in healthcare applications. In this study, we propose a framework designed to adeptly tailor VLMs to the medical domain, employing selective sampling and hard-negative mining techniques for enhanced performance in retrieval tasks. We validate the efficacy of our proposed approach by implementing it across two distinct VLMs: the in-domain VLM (MedCLIP) and out-of-domain VLMs (ALBEF). We assess the performance of these models both in their original off-the-shelf state and after undergoing our proposed training strategies, using two extensive datasets containing mammograms and their corresponding reports. Our evaluation spans zero-shot, few-shot, and supervised scenarios. Through our approach, we observe a notable enhancement in Recall@K performance for the image-text retrieval task.
PathologyBERT -- Pre-trained Vs. A New Transformer Language Model for Pathology Domain
May 13, 2022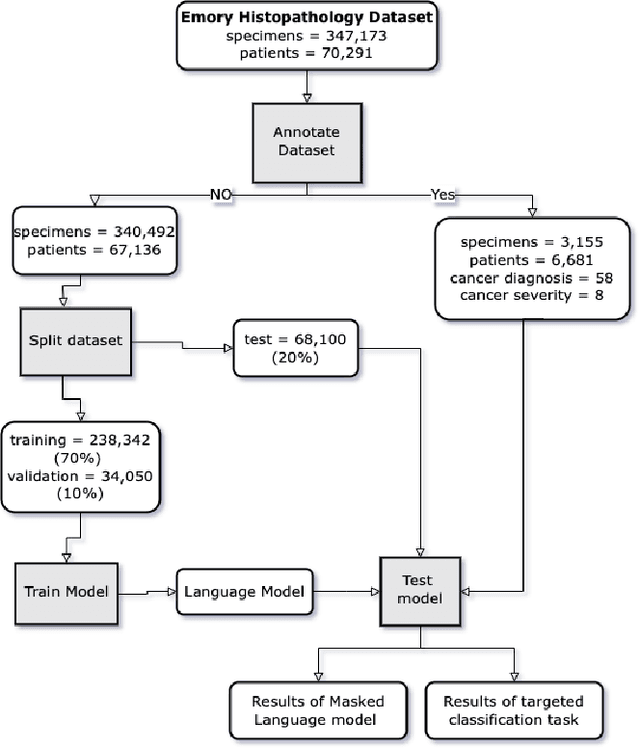

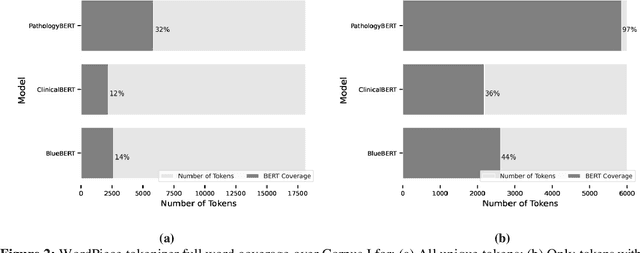
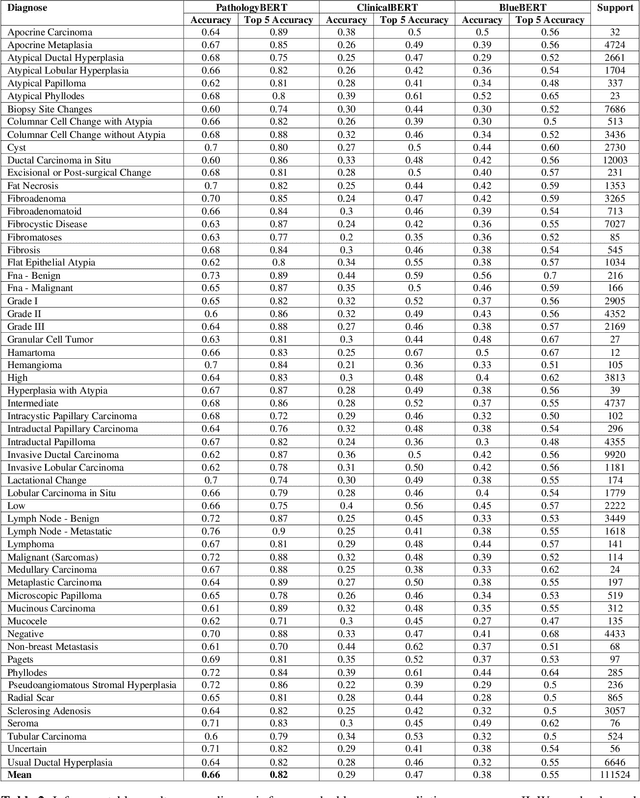
Pathology text mining is a challenging task given the reporting variability and constant new findings in cancer sub-type definitions. However, successful text mining of a large pathology database can play a critical role to advance 'big data' cancer research like similarity-based treatment selection, case identification, prognostication, surveillance, clinical trial screening, risk stratification, and many others. While there is a growing interest in developing language models for more specific clinical domains, no pathology-specific language space exist to support the rapid data-mining development in pathology space. In literature, a few approaches fine-tuned general transformer models on specialized corpora while maintaining the original tokenizer, but in fields requiring specialized terminology, these models often fail to perform adequately. We propose PathologyBERT - a pre-trained masked language model which was trained on 347,173 histopathology specimen reports and publicly released in the Huggingface repository. Our comprehensive experiments demonstrate that pre-training of transformer model on pathology corpora yields performance improvements on Natural Language Understanding (NLU) and Breast Cancer Diagnose Classification when compared to nonspecific language models.
Multimodal spatiotemporal graph neural networks for improved prediction of 30-day all-cause hospital readmission
Apr 14, 2022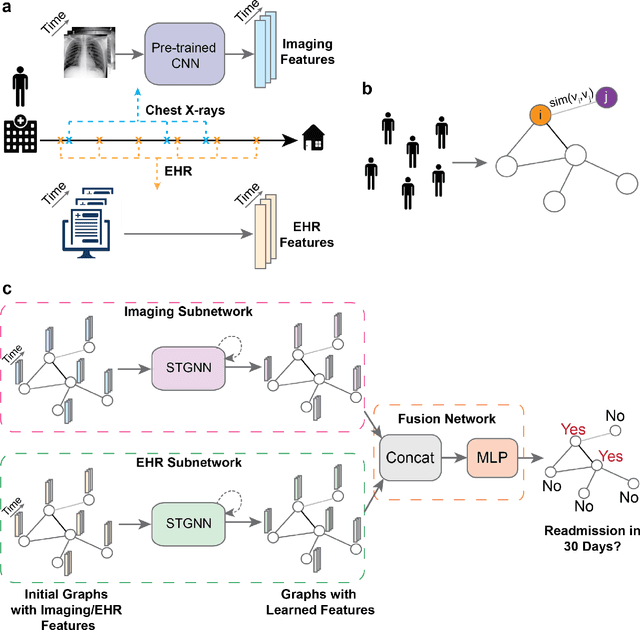
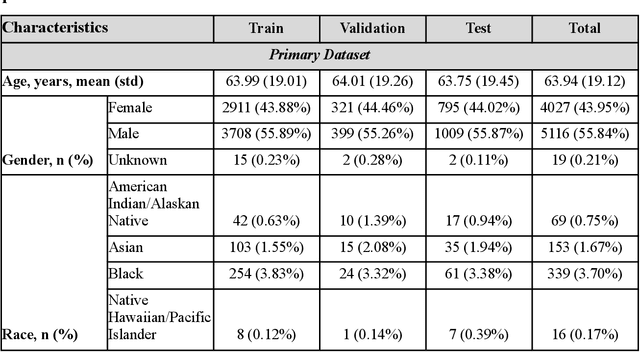
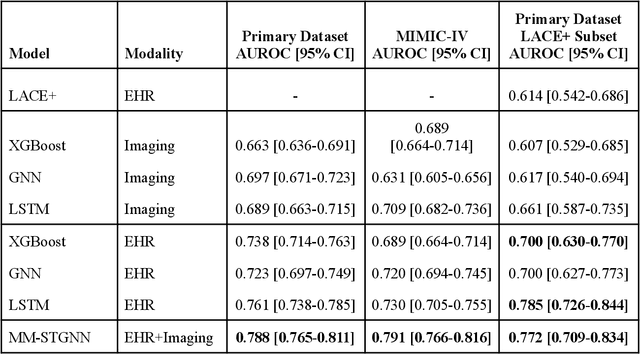
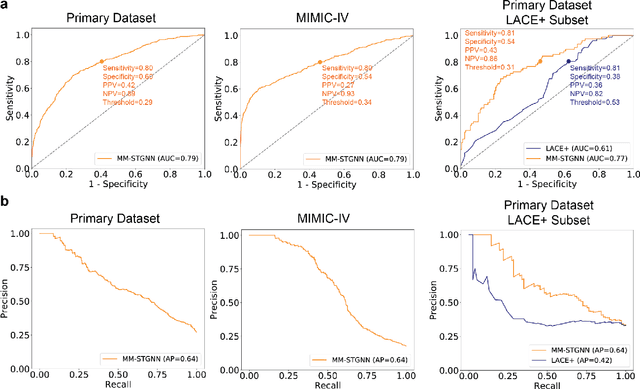
Measures to predict 30-day readmission are considered an important quality factor for hospitals as accurate predictions can reduce the overall cost of care by identifying high risk patients before they are discharged. While recent deep learning-based studies have shown promising empirical results on readmission prediction, several limitations exist that may hinder widespread clinical utility, such as (a) only patients with certain conditions are considered, (b) existing approaches do not leverage data temporality, (c) individual admissions are assumed independent of each other, which is unrealistic, (d) prior studies are usually limited to single source of data and single center data. To address these limitations, we propose a multimodal, modality-agnostic spatiotemporal graph neural network (MM-STGNN) for prediction of 30-day all-cause hospital readmission that fuses multimodal in-patient longitudinal data. By training and evaluating our methods using longitudinal chest radiographs and electronic health records from two independent centers, we demonstrate that MM-STGNN achieves AUROC of 0.79 on both primary and external datasets. Furthermore, MM-STGNN significantly outperforms the current clinical reference standard, LACE+ score (AUROC=0.61), on the primary dataset. For subset populations of patients with heart and vascular disease, our model also outperforms baselines on predicting 30-day readmission (e.g., 3.7 point improvement in AUROC in patients with heart disease). Lastly, qualitative model interpretability analysis indicates that while patients' primary diagnoses were not explicitly used to train the model, node features crucial for model prediction directly reflect patients' primary diagnoses. Importantly, our MM-STGNN is agnostic to node feature modalities and could be utilized to integrate multimodal data for triaging patients in various downstream resource allocation tasks.
Generalization of Deep Convolutional Neural Networks -- A Case-study on Open-source Chest Radiographs
Jul 11, 2020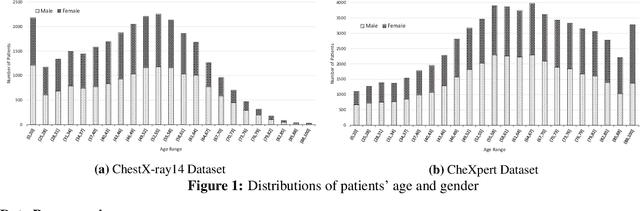
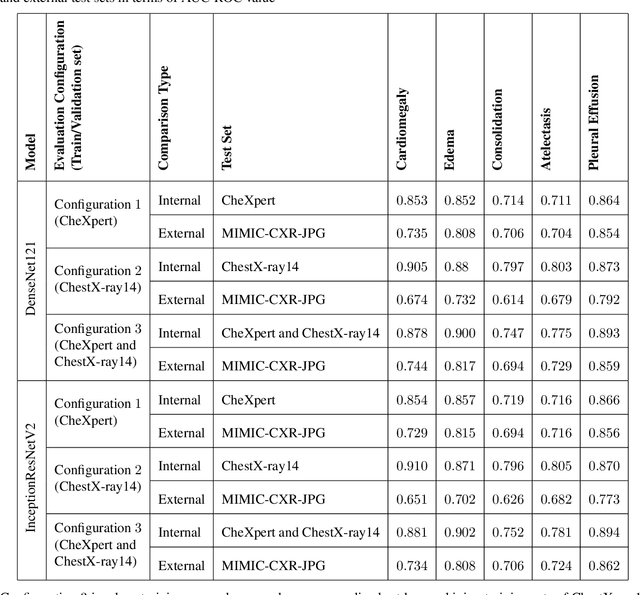
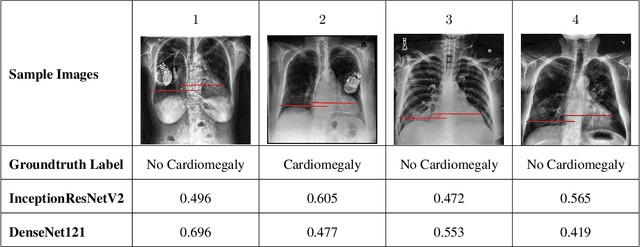
Deep Convolutional Neural Networks (DCNNs) have attracted extensive attention and been applied in many areas, including medical image analysis and clinical diagnosis. One major challenge is to conceive a DCNN model with remarkable performance on both internal and external data. We demonstrate that DCNNs may not generalize to new data, but increasing the quality and heterogeneity of the training data helps to improve the generalizibility factor. We use InceptionResNetV2 and DenseNet121 architectures to predict the risk of 5 common chest pathologies. The experiments were conducted on three publicly available databases: CheXpert, ChestX-ray14, and MIMIC Chest Xray JPG. The results show the internal performance of each of the 5 pathologies outperformed external performance on both of the models. Moreover, our strategy of exposing the models to a mix of different datasets during the training phase helps to improve model performance on the external dataset.
Was there COVID-19 back in 2012? Challenge for AI in Diagnosis with Similar Indications
Jun 23, 2020
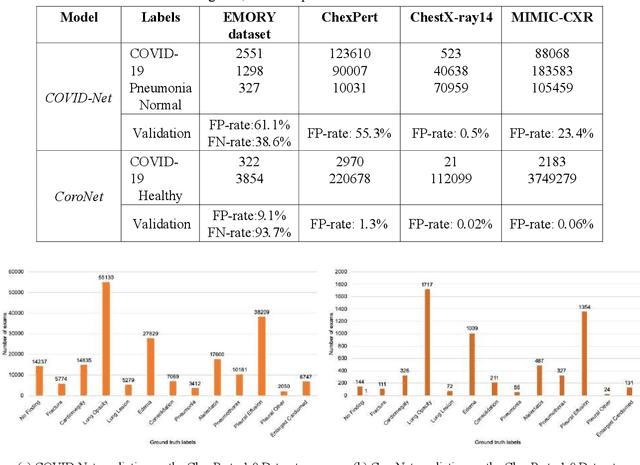
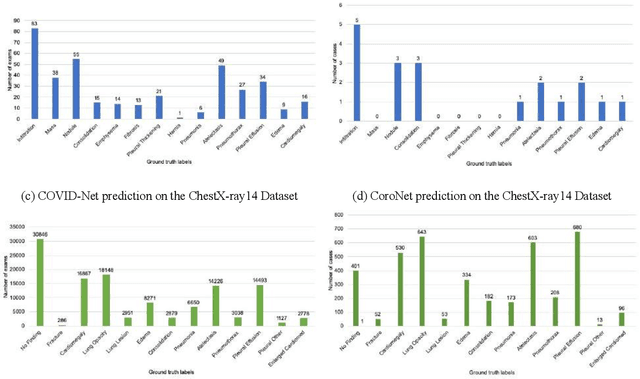

Purpose: Since the recent COVID-19 outbreak, there has been an avalanche of research papers applying deep learning based image processing to chest radiographs for detection of the disease. To test the performance of the two top models for CXR COVID-19 diagnosis on external datasets to assess model generalizability. Methods: In this paper, we present our argument regarding the efficiency and applicability of existing deep learning models for COVID-19 diagnosis. We provide results from two popular models - COVID-Net and CoroNet evaluated on three publicly available datasets and an additional institutional dataset collected from EMORY Hospital between January and May 2020, containing patients tested for COVID-19 infection using RT-PCR. Results: There is a large false positive rate (FPR) for COVID-Net on both ChexPert (55.3%) and MIMIC-CXR (23.4%) dataset. On the EMORY Dataset, COVID-Net has 61.4% sensitivity, 0.54 F1-score and 0.49 precision value. The FPR of the CoroNet model is significantly lower across all the datasets as compared to COVID-Net - EMORY(9.1%), ChexPert (1.3%), ChestX-ray14 (0.02%), MIMIC-CXR (0.06%). Conclusion: The models reported good to excellent performance on their internal datasets, however we observed from our testing that their performance dramatically worsened on external data. This is likely from several causes including overfitting models due to lack of appropriate control patients and ground truth labels. The fourth institutional dataset was labeled using RT-PCR, which could be positive without radiographic findings and vice versa. Therefore, a fusion model of both clinical and radiographic data may have better performance and generalization.
Learning Semantics for Image Annotation
May 15, 2017



Image search and retrieval engines rely heavily on textual annotation in order to match word queries to a set of candidate images. A system that can automatically annotate images with meaningful text can be highly beneficial for such engines. Currently, the approaches to develop such systems try to establish relationships between keywords and visual features of images. In this paper, We make three main contributions to this area: (i) We transform this problem from the low-level keyword space to the high-level semantics space that we refer to as the "{\em image theme}", (ii) Instead of treating each possible keyword independently, we use latent Dirichlet allocation to learn image themes from the associated texts in a training phase. Images are then annotated with image themes rather than keywords, using a modified continuous relevance model, which takes into account the spatial coherence and the visual continuity among images of common theme. (iii) To achieve more coherent annotations among images of common theme, we have integrated ConceptNet in learning the semantics of images, and hence augment image descriptions beyond annotations provided by humans. Images are thus further annotated by a few most significant words of the prominent image theme. Our extensive experiments show that a coherent theme-based image annotation using high-level semantics results in improved precision and recall as compared with equivalent classical keyword annotation systems.
Image Annotation using Multi-Layer Sparse Coding
May 06, 2017

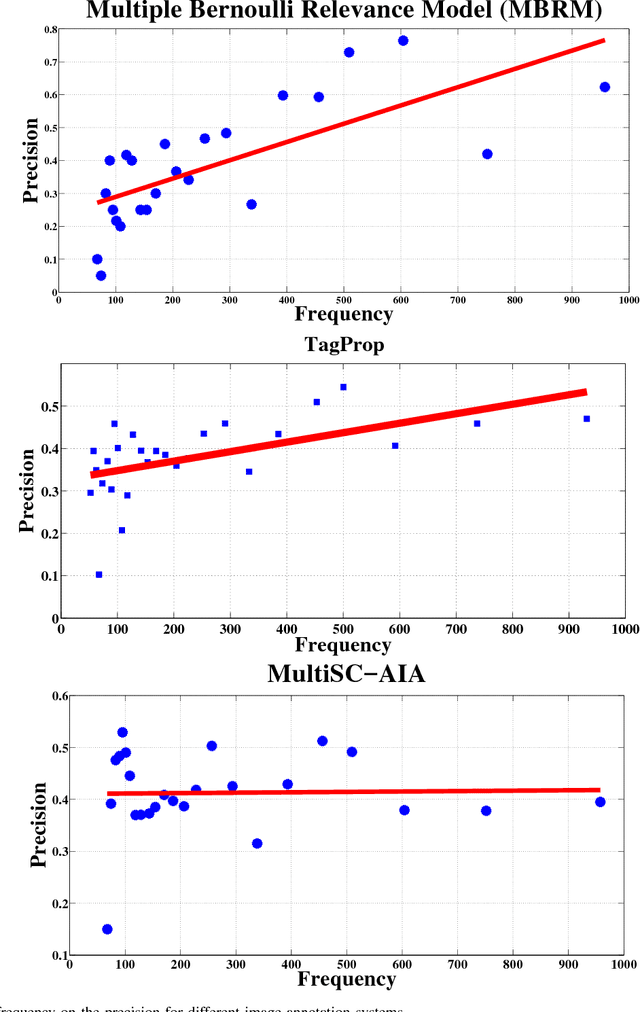

Automatic annotation of images with descriptive words is a challenging problem with vast applications in the areas of image search and retrieval. This problem can be viewed as a label-assignment problem by a classifier dealing with a very large set of labels, i.e., the vocabulary set. We propose a novel annotation method that employs two layers of sparse coding and performs coarse-to-fine labeling. Themes extracted from the training data are treated as coarse labels. Each theme is a set of training images that share a common subject in their visual and textual contents. Our system extracts coarse labels for training and test images without requiring any prior knowledge. Vocabulary words are the fine labels to be associated with images. Most of the annotation methods achieve low recall due to the large number of available fine labels, i.e., vocabulary words. These systems also tend to achieve high precision for highly frequent words only while relatively rare words are more important for search and retrieval purposes. Our system not only outperforms various previously proposed annotation systems, but also achieves symmetric response in terms of precision and recall. Our system scores and maintains high precision for words with a wide range of frequencies. Such behavior is achieved by intelligently reducing the number of available fine labels or words for each image based on coarse labels assigned to it.